forked from olcxjas-softworks/LarpixClient
Update gitignore (sorry)
This commit is contained in:
parent
a8f8c4d7ad
commit
cca8b02fea
6604 changed files with 1219661 additions and 4 deletions
1
electron/node_modules/cacache/node_modules/.bin/mkdirp
generated
vendored
Symbolic link
1
electron/node_modules/cacache/node_modules/.bin/mkdirp
generated
vendored
Symbolic link
|
|
@ -0,0 +1 @@
|
|||
../mkdirp/bin/cmd.js
|
||||
1
electron/node_modules/cacache/node_modules/.bin/rimraf
generated
vendored
Symbolic link
1
electron/node_modules/cacache/node_modules/.bin/rimraf
generated
vendored
Symbolic link
|
|
@ -0,0 +1 @@
|
|||
../rimraf/bin.js
|
||||
2
electron/node_modules/cacache/node_modules/brace-expansion/.github/FUNDING.yml
generated
vendored
Normal file
2
electron/node_modules/cacache/node_modules/brace-expansion/.github/FUNDING.yml
generated
vendored
Normal file
|
|
@ -0,0 +1,2 @@
|
|||
tidelift: "npm/brace-expansion"
|
||||
patreon: juliangruber
|
||||
21
electron/node_modules/cacache/node_modules/brace-expansion/LICENSE
generated
vendored
Normal file
21
electron/node_modules/cacache/node_modules/brace-expansion/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
MIT License
|
||||
|
||||
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
135
electron/node_modules/cacache/node_modules/brace-expansion/README.md
generated
vendored
Normal file
135
electron/node_modules/cacache/node_modules/brace-expansion/README.md
generated
vendored
Normal file
|
|
@ -0,0 +1,135 @@
|
|||
# brace-expansion
|
||||
|
||||
[Brace expansion](https://www.gnu.org/software/bash/manual/html_node/Brace-Expansion.html),
|
||||
as known from sh/bash, in JavaScript.
|
||||
|
||||
[](http://travis-ci.org/juliangruber/brace-expansion)
|
||||
[](https://www.npmjs.org/package/brace-expansion)
|
||||
[](https://greenkeeper.io/)
|
||||
|
||||
[](https://ci.testling.com/juliangruber/brace-expansion)
|
||||
|
||||
## Example
|
||||
|
||||
```js
|
||||
var expand = require('brace-expansion');
|
||||
|
||||
expand('file-{a,b,c}.jpg')
|
||||
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
|
||||
|
||||
expand('-v{,,}')
|
||||
// => ['-v', '-v', '-v']
|
||||
|
||||
expand('file{0..2}.jpg')
|
||||
// => ['file0.jpg', 'file1.jpg', 'file2.jpg']
|
||||
|
||||
expand('file-{a..c}.jpg')
|
||||
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
|
||||
|
||||
expand('file{2..0}.jpg')
|
||||
// => ['file2.jpg', 'file1.jpg', 'file0.jpg']
|
||||
|
||||
expand('file{0..4..2}.jpg')
|
||||
// => ['file0.jpg', 'file2.jpg', 'file4.jpg']
|
||||
|
||||
expand('file-{a..e..2}.jpg')
|
||||
// => ['file-a.jpg', 'file-c.jpg', 'file-e.jpg']
|
||||
|
||||
expand('file{00..10..5}.jpg')
|
||||
// => ['file00.jpg', 'file05.jpg', 'file10.jpg']
|
||||
|
||||
expand('{{A..C},{a..c}}')
|
||||
// => ['A', 'B', 'C', 'a', 'b', 'c']
|
||||
|
||||
expand('ppp{,config,oe{,conf}}')
|
||||
// => ['ppp', 'pppconfig', 'pppoe', 'pppoeconf']
|
||||
```
|
||||
|
||||
## API
|
||||
|
||||
```js
|
||||
var expand = require('brace-expansion');
|
||||
```
|
||||
|
||||
### var expanded = expand(str)
|
||||
|
||||
Return an array of all possible and valid expansions of `str`. If none are
|
||||
found, `[str]` is returned.
|
||||
|
||||
Valid expansions are:
|
||||
|
||||
```js
|
||||
/^(.*,)+(.+)?$/
|
||||
// {a,b,...}
|
||||
```
|
||||
|
||||
A comma separated list of options, like `{a,b}` or `{a,{b,c}}` or `{,a,}`.
|
||||
|
||||
```js
|
||||
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
|
||||
// {x..y[..incr]}
|
||||
```
|
||||
|
||||
A numeric sequence from `x` to `y` inclusive, with optional increment.
|
||||
If `x` or `y` start with a leading `0`, all the numbers will be padded
|
||||
to have equal length. Negative numbers and backwards iteration work too.
|
||||
|
||||
```js
|
||||
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
|
||||
// {x..y[..incr]}
|
||||
```
|
||||
|
||||
An alphabetic sequence from `x` to `y` inclusive, with optional increment.
|
||||
`x` and `y` must be exactly one character, and if given, `incr` must be a
|
||||
number.
|
||||
|
||||
For compatibility reasons, the string `${` is not eligible for brace expansion.
|
||||
|
||||
## Installation
|
||||
|
||||
With [npm](https://npmjs.org) do:
|
||||
|
||||
```bash
|
||||
npm install brace-expansion
|
||||
```
|
||||
|
||||
## Contributors
|
||||
|
||||
- [Julian Gruber](https://github.com/juliangruber)
|
||||
- [Isaac Z. Schlueter](https://github.com/isaacs)
|
||||
|
||||
## Sponsors
|
||||
|
||||
This module is proudly supported by my [Sponsors](https://github.com/juliangruber/sponsors)!
|
||||
|
||||
Do you want to support modules like this to improve their quality, stability and weigh in on new features? Then please consider donating to my [Patreon](https://www.patreon.com/juliangruber). Not sure how much of my modules you're using? Try [feross/thanks](https://github.com/feross/thanks)!
|
||||
|
||||
## Security contact information
|
||||
|
||||
To report a security vulnerability, please use the
|
||||
[Tidelift security contact](https://tidelift.com/security).
|
||||
Tidelift will coordinate the fix and disclosure.
|
||||
|
||||
## License
|
||||
|
||||
(MIT)
|
||||
|
||||
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy of
|
||||
this software and associated documentation files (the "Software"), to deal in
|
||||
the Software without restriction, including without limitation the rights to
|
||||
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
||||
of the Software, and to permit persons to whom the Software is furnished to do
|
||||
so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
205
electron/node_modules/cacache/node_modules/brace-expansion/index.js
generated
vendored
Normal file
205
electron/node_modules/cacache/node_modules/brace-expansion/index.js
generated
vendored
Normal file
|
|
@ -0,0 +1,205 @@
|
|||
var balanced = require('balanced-match');
|
||||
|
||||
module.exports = expandTop;
|
||||
|
||||
var escSlash = '\0SLASH'+Math.random()+'\0';
|
||||
var escOpen = '\0OPEN'+Math.random()+'\0';
|
||||
var escClose = '\0CLOSE'+Math.random()+'\0';
|
||||
var escComma = '\0COMMA'+Math.random()+'\0';
|
||||
var escPeriod = '\0PERIOD'+Math.random()+'\0';
|
||||
|
||||
function numeric(str) {
|
||||
return parseInt(str, 10) == str
|
||||
? parseInt(str, 10)
|
||||
: str.charCodeAt(0);
|
||||
}
|
||||
|
||||
function escapeBraces(str) {
|
||||
return str.split('\\\\').join(escSlash)
|
||||
.split('\\{').join(escOpen)
|
||||
.split('\\}').join(escClose)
|
||||
.split('\\,').join(escComma)
|
||||
.split('\\.').join(escPeriod);
|
||||
}
|
||||
|
||||
function unescapeBraces(str) {
|
||||
return str.split(escSlash).join('\\')
|
||||
.split(escOpen).join('{')
|
||||
.split(escClose).join('}')
|
||||
.split(escComma).join(',')
|
||||
.split(escPeriod).join('.');
|
||||
}
|
||||
|
||||
|
||||
// Basically just str.split(","), but handling cases
|
||||
// where we have nested braced sections, which should be
|
||||
// treated as individual members, like {a,{b,c},d}
|
||||
function parseCommaParts(str) {
|
||||
if (!str)
|
||||
return [''];
|
||||
|
||||
var parts = [];
|
||||
var m = balanced('{', '}', str);
|
||||
|
||||
if (!m)
|
||||
return str.split(',');
|
||||
|
||||
var pre = m.pre;
|
||||
var body = m.body;
|
||||
var post = m.post;
|
||||
var p = pre.split(',');
|
||||
|
||||
p[p.length-1] += '{' + body + '}';
|
||||
var postParts = parseCommaParts(post);
|
||||
if (post.length) {
|
||||
p[p.length-1] += postParts.shift();
|
||||
p.push.apply(p, postParts);
|
||||
}
|
||||
|
||||
parts.push.apply(parts, p);
|
||||
|
||||
return parts;
|
||||
}
|
||||
|
||||
function expandTop(str, options) {
|
||||
if (!str)
|
||||
return [];
|
||||
|
||||
options = options || {};
|
||||
var max = options.max == null ? Infinity : options.max;
|
||||
|
||||
// I don't know why Bash 4.3 does this, but it does.
|
||||
// Anything starting with {} will have the first two bytes preserved
|
||||
// but *only* at the top level, so {},a}b will not expand to anything,
|
||||
// but a{},b}c will be expanded to [a}c,abc].
|
||||
// One could argue that this is a bug in Bash, but since the goal of
|
||||
// this module is to match Bash's rules, we escape a leading {}
|
||||
if (str.substr(0, 2) === '{}') {
|
||||
str = '\\{\\}' + str.substr(2);
|
||||
}
|
||||
|
||||
return expand(escapeBraces(str), max, true).map(unescapeBraces);
|
||||
}
|
||||
|
||||
function embrace(str) {
|
||||
return '{' + str + '}';
|
||||
}
|
||||
function isPadded(el) {
|
||||
return /^-?0\d/.test(el);
|
||||
}
|
||||
|
||||
function lte(i, y) {
|
||||
return i <= y;
|
||||
}
|
||||
function gte(i, y) {
|
||||
return i >= y;
|
||||
}
|
||||
|
||||
function expand(str, max, isTop) {
|
||||
var expansions = [];
|
||||
|
||||
var m = balanced('{', '}', str);
|
||||
if (!m) return [str];
|
||||
|
||||
// no need to expand pre, since it is guaranteed to be free of brace-sets
|
||||
var pre = m.pre;
|
||||
var post = m.post.length
|
||||
? expand(m.post, max, false)
|
||||
: [''];
|
||||
|
||||
if (/\$$/.test(m.pre)) {
|
||||
for (var k = 0; k < post.length && k < max; k++) {
|
||||
var expansion = pre+ '{' + m.body + '}' + post[k];
|
||||
expansions.push(expansion);
|
||||
}
|
||||
} else {
|
||||
var isNumericSequence = /^-?\d+\.\.-?\d+(?:\.\.-?\d+)?$/.test(m.body);
|
||||
var isAlphaSequence = /^[a-zA-Z]\.\.[a-zA-Z](?:\.\.-?\d+)?$/.test(m.body);
|
||||
var isSequence = isNumericSequence || isAlphaSequence;
|
||||
var isOptions = m.body.indexOf(',') >= 0;
|
||||
if (!isSequence && !isOptions) {
|
||||
// {a},b}
|
||||
if (m.post.match(/,(?!,).*\}/)) {
|
||||
str = m.pre + '{' + m.body + escClose + m.post;
|
||||
return expand(str, max, true);
|
||||
}
|
||||
return [str];
|
||||
}
|
||||
|
||||
var n;
|
||||
if (isSequence) {
|
||||
n = m.body.split(/\.\./);
|
||||
} else {
|
||||
n = parseCommaParts(m.body);
|
||||
if (n.length === 1) {
|
||||
// x{{a,b}}y ==> x{a}y x{b}y
|
||||
n = expand(n[0], max, false).map(embrace);
|
||||
if (n.length === 1) {
|
||||
return post.map(function(p) {
|
||||
return m.pre + n[0] + p;
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// at this point, n is the parts, and we know it's not a comma set
|
||||
// with a single entry.
|
||||
var N;
|
||||
|
||||
if (isSequence) {
|
||||
var x = numeric(n[0]);
|
||||
var y = numeric(n[1]);
|
||||
var width = Math.max(n[0].length, n[1].length)
|
||||
var incr = n.length == 3
|
||||
? Math.max(Math.abs(numeric(n[2])), 1)
|
||||
: 1;
|
||||
var test = lte;
|
||||
var reverse = y < x;
|
||||
if (reverse) {
|
||||
incr *= -1;
|
||||
test = gte;
|
||||
}
|
||||
var pad = n.some(isPadded);
|
||||
|
||||
N = [];
|
||||
|
||||
for (var i = x; test(i, y); i += incr) {
|
||||
var c;
|
||||
if (isAlphaSequence) {
|
||||
c = String.fromCharCode(i);
|
||||
if (c === '\\')
|
||||
c = '';
|
||||
} else {
|
||||
c = String(i);
|
||||
if (pad) {
|
||||
var need = width - c.length;
|
||||
if (need > 0) {
|
||||
var z = new Array(need + 1).join('0');
|
||||
if (i < 0)
|
||||
c = '-' + z + c.slice(1);
|
||||
else
|
||||
c = z + c;
|
||||
}
|
||||
}
|
||||
}
|
||||
N.push(c);
|
||||
}
|
||||
} else {
|
||||
N = [];
|
||||
|
||||
for (var j = 0; j < n.length; j++) {
|
||||
N.push.apply(N, expand(n[j], max, false));
|
||||
}
|
||||
}
|
||||
|
||||
for (var j = 0; j < N.length; j++) {
|
||||
for (var k = 0; k < post.length && expansions.length < max; k++) {
|
||||
var expansion = pre + N[j] + post[k];
|
||||
if (!isTop || isSequence || expansion)
|
||||
expansions.push(expansion);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return expansions;
|
||||
}
|
||||
49
electron/node_modules/cacache/node_modules/brace-expansion/package.json
generated
vendored
Normal file
49
electron/node_modules/cacache/node_modules/brace-expansion/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,49 @@
|
|||
{
|
||||
"name": "brace-expansion",
|
||||
"description": "Brace expansion as known from sh/bash",
|
||||
"version": "2.1.0",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/juliangruber/brace-expansion.git"
|
||||
},
|
||||
"homepage": "https://github.com/juliangruber/brace-expansion",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "tape test/*.js",
|
||||
"gentest": "bash test/generate.sh",
|
||||
"bench": "matcha test/perf/bench.js"
|
||||
},
|
||||
"dependencies": {
|
||||
"balanced-match": "^1.0.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@c4312/matcha": "^1.3.1",
|
||||
"tape": "^4.6.0"
|
||||
},
|
||||
"keywords": [],
|
||||
"author": {
|
||||
"name": "Julian Gruber",
|
||||
"email": "mail@juliangruber.com",
|
||||
"url": "http://juliangruber.com"
|
||||
},
|
||||
"license": "MIT",
|
||||
"testling": {
|
||||
"files": "test/*.js",
|
||||
"browsers": [
|
||||
"ie/8..latest",
|
||||
"firefox/20..latest",
|
||||
"firefox/nightly",
|
||||
"chrome/25..latest",
|
||||
"chrome/canary",
|
||||
"opera/12..latest",
|
||||
"opera/next",
|
||||
"safari/5.1..latest",
|
||||
"ipad/6.0..latest",
|
||||
"iphone/6.0..latest",
|
||||
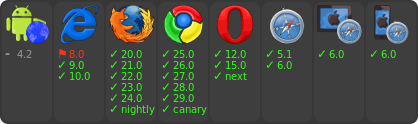
"android-browser/4.2..latest"
|
||||
]
|
||||
},
|
||||
"publishConfig": {
|
||||
"tag": "2.x"
|
||||
}
|
||||
}
|
||||
15
electron/node_modules/cacache/node_modules/glob/LICENSE
generated
vendored
Normal file
15
electron/node_modules/cacache/node_modules/glob/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
The ISC License
|
||||
|
||||
Copyright (c) 2009-2022 Isaac Z. Schlueter and Contributors
|
||||
|
||||
Permission to use, copy, modify, and/or distribute this software for any
|
||||
purpose with or without fee is hereby granted, provided that the above
|
||||
copyright notice and this permission notice appear in all copies.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
||||
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
||||
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
||||
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
||||
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR
|
||||
IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
399
electron/node_modules/cacache/node_modules/glob/README.md
generated
vendored
Normal file
399
electron/node_modules/cacache/node_modules/glob/README.md
generated
vendored
Normal file
|
|
@ -0,0 +1,399 @@
|
|||
# Glob
|
||||
|
||||
Match files using the patterns the shell uses, like stars and stuff.
|
||||
|
||||
[](https://travis-ci.org/isaacs/node-glob/) [](https://ci.appveyor.com/project/isaacs/node-glob) [](https://coveralls.io/github/isaacs/node-glob?branch=master)
|
||||
|
||||
This is a glob implementation in JavaScript. It uses the `minimatch`
|
||||
library to do its matching.
|
||||
|
||||

|
||||
|
||||
## Usage
|
||||
|
||||
Install with npm
|
||||
|
||||
```
|
||||
npm i glob
|
||||
```
|
||||
|
||||
```javascript
|
||||
var glob = require("glob")
|
||||
|
||||
// options is optional
|
||||
glob("**/*.js", options, function (er, files) {
|
||||
// files is an array of filenames.
|
||||
// If the `nonull` option is set, and nothing
|
||||
// was found, then files is ["**/*.js"]
|
||||
// er is an error object or null.
|
||||
})
|
||||
```
|
||||
|
||||
## Glob Primer
|
||||
|
||||
"Globs" are the patterns you type when you do stuff like `ls *.js` on
|
||||
the command line, or put `build/*` in a `.gitignore` file.
|
||||
|
||||
Before parsing the path part patterns, braced sections are expanded
|
||||
into a set. Braced sections start with `{` and end with `}`, with any
|
||||
number of comma-delimited sections within. Braced sections may contain
|
||||
slash characters, so `a{/b/c,bcd}` would expand into `a/b/c` and `abcd`.
|
||||
|
||||
The following characters have special magic meaning when used in a
|
||||
path portion:
|
||||
|
||||
* `*` Matches 0 or more characters in a single path portion
|
||||
* `?` Matches 1 character
|
||||
* `[...]` Matches a range of characters, similar to a RegExp range.
|
||||
If the first character of the range is `!` or `^` then it matches
|
||||
any character not in the range.
|
||||
* `!(pattern|pattern|pattern)` Matches anything that does not match
|
||||
any of the patterns provided.
|
||||
* `?(pattern|pattern|pattern)` Matches zero or one occurrence of the
|
||||
patterns provided.
|
||||
* `+(pattern|pattern|pattern)` Matches one or more occurrences of the
|
||||
patterns provided.
|
||||
* `*(a|b|c)` Matches zero or more occurrences of the patterns provided
|
||||
* `@(pattern|pat*|pat?erN)` Matches exactly one of the patterns
|
||||
provided
|
||||
* `**` If a "globstar" is alone in a path portion, then it matches
|
||||
zero or more directories and subdirectories searching for matches.
|
||||
It does not crawl symlinked directories.
|
||||
|
||||
### Dots
|
||||
|
||||
If a file or directory path portion has a `.` as the first character,
|
||||
then it will not match any glob pattern unless that pattern's
|
||||
corresponding path part also has a `.` as its first character.
|
||||
|
||||
For example, the pattern `a/.*/c` would match the file at `a/.b/c`.
|
||||
However the pattern `a/*/c` would not, because `*` does not start with
|
||||
a dot character.
|
||||
|
||||
You can make glob treat dots as normal characters by setting
|
||||
`dot:true` in the options.
|
||||
|
||||
### Basename Matching
|
||||
|
||||
If you set `matchBase:true` in the options, and the pattern has no
|
||||
slashes in it, then it will seek for any file anywhere in the tree
|
||||
with a matching basename. For example, `*.js` would match
|
||||
`test/simple/basic.js`.
|
||||
|
||||
### Empty Sets
|
||||
|
||||
If no matching files are found, then an empty array is returned. This
|
||||
differs from the shell, where the pattern itself is returned. For
|
||||
example:
|
||||
|
||||
$ echo a*s*d*f
|
||||
a*s*d*f
|
||||
|
||||
To get the bash-style behavior, set the `nonull:true` in the options.
|
||||
|
||||
### See Also:
|
||||
|
||||
* `man sh`
|
||||
* `man bash` (Search for "Pattern Matching")
|
||||
* `man 3 fnmatch`
|
||||
* `man 5 gitignore`
|
||||
* [minimatch documentation](https://github.com/isaacs/minimatch)
|
||||
|
||||
## glob.hasMagic(pattern, [options])
|
||||
|
||||
Returns `true` if there are any special characters in the pattern, and
|
||||
`false` otherwise.
|
||||
|
||||
Note that the options affect the results. If `noext:true` is set in
|
||||
the options object, then `+(a|b)` will not be considered a magic
|
||||
pattern. If the pattern has a brace expansion, like `a/{b/c,x/y}`
|
||||
then that is considered magical, unless `nobrace:true` is set in the
|
||||
options.
|
||||
|
||||
## glob(pattern, [options], cb)
|
||||
|
||||
* `pattern` `{String}` Pattern to be matched
|
||||
* `options` `{Object}`
|
||||
* `cb` `{Function}`
|
||||
* `err` `{Error | null}`
|
||||
* `matches` `{Array<String>}` filenames found matching the pattern
|
||||
|
||||
Perform an asynchronous glob search.
|
||||
|
||||
## glob.sync(pattern, [options])
|
||||
|
||||
* `pattern` `{String}` Pattern to be matched
|
||||
* `options` `{Object}`
|
||||
* return: `{Array<String>}` filenames found matching the pattern
|
||||
|
||||
Perform a synchronous glob search.
|
||||
|
||||
## Class: glob.Glob
|
||||
|
||||
Create a Glob object by instantiating the `glob.Glob` class.
|
||||
|
||||
```javascript
|
||||
var Glob = require("glob").Glob
|
||||
var mg = new Glob(pattern, options, cb)
|
||||
```
|
||||
|
||||
It's an EventEmitter, and starts walking the filesystem to find matches
|
||||
immediately.
|
||||
|
||||
### new glob.Glob(pattern, [options], [cb])
|
||||
|
||||
* `pattern` `{String}` pattern to search for
|
||||
* `options` `{Object}`
|
||||
* `cb` `{Function}` Called when an error occurs, or matches are found
|
||||
* `err` `{Error | null}`
|
||||
* `matches` `{Array<String>}` filenames found matching the pattern
|
||||
|
||||
Note that if the `sync` flag is set in the options, then matches will
|
||||
be immediately available on the `g.found` member.
|
||||
|
||||
### Properties
|
||||
|
||||
* `minimatch` The minimatch object that the glob uses.
|
||||
* `options` The options object passed in.
|
||||
* `aborted` Boolean which is set to true when calling `abort()`. There
|
||||
is no way at this time to continue a glob search after aborting, but
|
||||
you can re-use the statCache to avoid having to duplicate syscalls.
|
||||
* `cache` Convenience object. Each field has the following possible
|
||||
values:
|
||||
* `false` - Path does not exist
|
||||
* `true` - Path exists
|
||||
* `'FILE'` - Path exists, and is not a directory
|
||||
* `'DIR'` - Path exists, and is a directory
|
||||
* `[file, entries, ...]` - Path exists, is a directory, and the
|
||||
array value is the results of `fs.readdir`
|
||||
* `statCache` Cache of `fs.stat` results, to prevent statting the same
|
||||
path multiple times.
|
||||
* `symlinks` A record of which paths are symbolic links, which is
|
||||
relevant in resolving `**` patterns.
|
||||
* `realpathCache` An optional object which is passed to `fs.realpath`
|
||||
to minimize unnecessary syscalls. It is stored on the instantiated
|
||||
Glob object, and may be re-used.
|
||||
|
||||
### Events
|
||||
|
||||
* `end` When the matching is finished, this is emitted with all the
|
||||
matches found. If the `nonull` option is set, and no match was found,
|
||||
then the `matches` list contains the original pattern. The matches
|
||||
are sorted, unless the `nosort` flag is set.
|
||||
* `match` Every time a match is found, this is emitted with the specific
|
||||
thing that matched. It is not deduplicated or resolved to a realpath.
|
||||
* `error` Emitted when an unexpected error is encountered, or whenever
|
||||
any fs error occurs if `options.strict` is set.
|
||||
* `abort` When `abort()` is called, this event is raised.
|
||||
|
||||
### Methods
|
||||
|
||||
* `pause` Temporarily stop the search
|
||||
* `resume` Resume the search
|
||||
* `abort` Stop the search forever
|
||||
|
||||
### Options
|
||||
|
||||
All the options that can be passed to Minimatch can also be passed to
|
||||
Glob to change pattern matching behavior. Also, some have been added,
|
||||
or have glob-specific ramifications.
|
||||
|
||||
All options are false by default, unless otherwise noted.
|
||||
|
||||
All options are added to the Glob object, as well.
|
||||
|
||||
If you are running many `glob` operations, you can pass a Glob object
|
||||
as the `options` argument to a subsequent operation to shortcut some
|
||||
`stat` and `readdir` calls. At the very least, you may pass in shared
|
||||
`symlinks`, `statCache`, `realpathCache`, and `cache` options, so that
|
||||
parallel glob operations will be sped up by sharing information about
|
||||
the filesystem.
|
||||
|
||||
* `cwd` The current working directory in which to search. Defaults
|
||||
to `process.cwd()`. This option is always coerced to use
|
||||
forward-slashes as a path separator, because it is not tested
|
||||
as a glob pattern, so there is no need to escape anything.
|
||||
* `root` The place where patterns starting with `/` will be mounted
|
||||
onto. Defaults to `path.resolve(options.cwd, "/")` (`/` on Unix
|
||||
systems, and `C:\` or some such on Windows.) This option is
|
||||
always coerced to use forward-slashes as a path separator,
|
||||
because it is not tested as a glob pattern, so there is no need
|
||||
to escape anything.
|
||||
* `windowsPathsNoEscape` Use `\\` as a path separator _only_, and
|
||||
_never_ as an escape character. If set, all `\\` characters
|
||||
are replaced with `/` in the pattern. Note that this makes it
|
||||
**impossible** to match against paths containing literal glob
|
||||
pattern characters, but allows matching with patterns constructed
|
||||
using `path.join()` and `path.resolve()` on Windows platforms,
|
||||
mimicking the (buggy!) behavior of Glob v7 and before on
|
||||
Windows. Please use with caution, and be mindful of [the caveat
|
||||
below about Windows paths](#windows). (For legacy reasons,
|
||||
this is also set if `allowWindowsEscape` is set to the exact
|
||||
value `false`.)
|
||||
* `dot` Include `.dot` files in normal matches and `globstar` matches.
|
||||
Note that an explicit dot in a portion of the pattern will always
|
||||
match dot files.
|
||||
* `nomount` By default, a pattern starting with a forward-slash will be
|
||||
"mounted" onto the root setting, so that a valid filesystem path is
|
||||
returned. Set this flag to disable that behavior.
|
||||
* `mark` Add a `/` character to directory matches. Note that this
|
||||
requires additional stat calls.
|
||||
* `nosort` Don't sort the results.
|
||||
* `stat` Set to true to stat *all* results. This reduces performance
|
||||
somewhat, and is completely unnecessary, unless `readdir` is presumed
|
||||
to be an untrustworthy indicator of file existence.
|
||||
* `silent` When an unusual error is encountered when attempting to
|
||||
read a directory, a warning will be printed to stderr. Set the
|
||||
`silent` option to true to suppress these warnings.
|
||||
* `strict` When an unusual error is encountered when attempting to
|
||||
read a directory, the process will just continue on in search of
|
||||
other matches. Set the `strict` option to raise an error in these
|
||||
cases.
|
||||
* `cache` See `cache` property above. Pass in a previously generated
|
||||
cache object to save some fs calls.
|
||||
* `statCache` A cache of results of filesystem information, to prevent
|
||||
unnecessary stat calls. While it should not normally be necessary
|
||||
to set this, you may pass the statCache from one glob() call to the
|
||||
options object of another, if you know that the filesystem will not
|
||||
change between calls. (See "Race Conditions" below.)
|
||||
* `symlinks` A cache of known symbolic links. You may pass in a
|
||||
previously generated `symlinks` object to save `lstat` calls when
|
||||
resolving `**` matches.
|
||||
* `sync` DEPRECATED: use `glob.sync(pattern, opts)` instead.
|
||||
* `nounique` In some cases, brace-expanded patterns can result in the
|
||||
same file showing up multiple times in the result set. By default,
|
||||
this implementation prevents duplicates in the result set. Set this
|
||||
flag to disable that behavior.
|
||||
* `nonull` Set to never return an empty set, instead returning a set
|
||||
containing the pattern itself. This is the default in glob(3).
|
||||
* `debug` Set to enable debug logging in minimatch and glob.
|
||||
* `nobrace` Do not expand `{a,b}` and `{1..3}` brace sets.
|
||||
* `noglobstar` Do not match `**` against multiple filenames. (Ie,
|
||||
treat it as a normal `*` instead.)
|
||||
* `noext` Do not match `+(a|b)` "extglob" patterns.
|
||||
* `nocase` Perform a case-insensitive match. Note: on
|
||||
case-insensitive filesystems, non-magic patterns will match by
|
||||
default, since `stat` and `readdir` will not raise errors.
|
||||
* `matchBase` Perform a basename-only match if the pattern does not
|
||||
contain any slash characters. That is, `*.js` would be treated as
|
||||
equivalent to `**/*.js`, matching all js files in all directories.
|
||||
* `nodir` Do not match directories, only files. (Note: to match
|
||||
*only* directories, simply put a `/` at the end of the pattern.)
|
||||
* `ignore` Add a pattern or an array of glob patterns to exclude matches.
|
||||
Note: `ignore` patterns are *always* in `dot:true` mode, regardless
|
||||
of any other settings.
|
||||
* `follow` Follow symlinked directories when expanding `**` patterns.
|
||||
Note that this can result in a lot of duplicate references in the
|
||||
presence of cyclic links.
|
||||
* `realpath` Set to true to call `fs.realpath` on all of the results.
|
||||
In the case of a symlink that cannot be resolved, the full absolute
|
||||
path to the matched entry is returned (though it will usually be a
|
||||
broken symlink)
|
||||
* `absolute` Set to true to always receive absolute paths for matched
|
||||
files. Unlike `realpath`, this also affects the values returned in
|
||||
the `match` event.
|
||||
* `fs` File-system object with Node's `fs` API. By default, the built-in
|
||||
`fs` module will be used. Set to a volume provided by a library like
|
||||
`memfs` to avoid using the "real" file-system.
|
||||
|
||||
## Comparisons to other fnmatch/glob implementations
|
||||
|
||||
While strict compliance with the existing standards is a worthwhile
|
||||
goal, some discrepancies exist between node-glob and other
|
||||
implementations, and are intentional.
|
||||
|
||||
The double-star character `**` is supported by default, unless the
|
||||
`noglobstar` flag is set. This is supported in the manner of bsdglob
|
||||
and bash 4.3, where `**` only has special significance if it is the only
|
||||
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
|
||||
`a/**b` will not.
|
||||
|
||||
Note that symlinked directories are not crawled as part of a `**`,
|
||||
though their contents may match against subsequent portions of the
|
||||
pattern. This prevents infinite loops and duplicates and the like.
|
||||
|
||||
If an escaped pattern has no matches, and the `nonull` flag is set,
|
||||
then glob returns the pattern as-provided, rather than
|
||||
interpreting the character escapes. For example,
|
||||
`glob.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
|
||||
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
|
||||
that it does not resolve escaped pattern characters.
|
||||
|
||||
If brace expansion is not disabled, then it is performed before any
|
||||
other interpretation of the glob pattern. Thus, a pattern like
|
||||
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
|
||||
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
|
||||
checked for validity. Since those two are valid, matching proceeds.
|
||||
|
||||
### Comments and Negation
|
||||
|
||||
Previously, this module let you mark a pattern as a "comment" if it
|
||||
started with a `#` character, or a "negated" pattern if it started
|
||||
with a `!` character.
|
||||
|
||||
These options were deprecated in version 5, and removed in version 6.
|
||||
|
||||
To specify things that should not match, use the `ignore` option.
|
||||
|
||||
## Windows
|
||||
|
||||
**Please only use forward-slashes in glob expressions.**
|
||||
|
||||
Though windows uses either `/` or `\` as its path separator, only `/`
|
||||
characters are used by this glob implementation. You must use
|
||||
forward-slashes **only** in glob expressions. Back-slashes will always
|
||||
be interpreted as escape characters, not path separators.
|
||||
|
||||
Results from absolute patterns such as `/foo/*` are mounted onto the
|
||||
root setting using `path.join`. On windows, this will by default result
|
||||
in `/foo/*` matching `C:\foo\bar.txt`.
|
||||
|
||||
To automatically coerce all `\` characters to `/` in pattern
|
||||
strings, **thus making it impossible to escape literal glob
|
||||
characters**, you may set the `windowsPathsNoEscape` option to
|
||||
`true`.
|
||||
|
||||
## Race Conditions
|
||||
|
||||
Glob searching, by its very nature, is susceptible to race conditions,
|
||||
since it relies on directory walking and such.
|
||||
|
||||
As a result, it is possible that a file that exists when glob looks for
|
||||
it may have been deleted or modified by the time it returns the result.
|
||||
|
||||
As part of its internal implementation, this program caches all stat
|
||||
and readdir calls that it makes, in order to cut down on system
|
||||
overhead. However, this also makes it even more susceptible to races,
|
||||
especially if the cache or statCache objects are reused between glob
|
||||
calls.
|
||||
|
||||
Users are thus advised not to use a glob result as a guarantee of
|
||||
filesystem state in the face of rapid changes. For the vast majority
|
||||
of operations, this is never a problem.
|
||||
|
||||
## Glob Logo
|
||||
Glob's logo was created by [Tanya Brassie](http://tanyabrassie.com/). Logo files can be found [here](https://github.com/isaacs/node-glob/tree/master/logo).
|
||||
|
||||
The logo is licensed under a [Creative Commons Attribution-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-sa/4.0/).
|
||||
|
||||
## Contributing
|
||||
|
||||
Any change to behavior (including bugfixes) must come with a test.
|
||||
|
||||
Patches that fail tests or reduce performance will be rejected.
|
||||
|
||||
```
|
||||
# to run tests
|
||||
npm test
|
||||
|
||||
# to re-generate test fixtures
|
||||
npm run test-regen
|
||||
|
||||
# to benchmark against bash/zsh
|
||||
npm run bench
|
||||
|
||||
# to profile javascript
|
||||
npm run prof
|
||||
```
|
||||
|
||||

|
||||
244
electron/node_modules/cacache/node_modules/glob/common.js
generated
vendored
Normal file
244
electron/node_modules/cacache/node_modules/glob/common.js
generated
vendored
Normal file
|
|
@ -0,0 +1,244 @@
|
|||
exports.setopts = setopts
|
||||
exports.ownProp = ownProp
|
||||
exports.makeAbs = makeAbs
|
||||
exports.finish = finish
|
||||
exports.mark = mark
|
||||
exports.isIgnored = isIgnored
|
||||
exports.childrenIgnored = childrenIgnored
|
||||
|
||||
function ownProp (obj, field) {
|
||||
return Object.prototype.hasOwnProperty.call(obj, field)
|
||||
}
|
||||
|
||||
var fs = require("fs")
|
||||
var path = require("path")
|
||||
var minimatch = require("minimatch")
|
||||
var isAbsolute = require("path").isAbsolute
|
||||
var Minimatch = minimatch.Minimatch
|
||||
|
||||
function alphasort (a, b) {
|
||||
return a.localeCompare(b, 'en')
|
||||
}
|
||||
|
||||
function setupIgnores (self, options) {
|
||||
self.ignore = options.ignore || []
|
||||
|
||||
if (!Array.isArray(self.ignore))
|
||||
self.ignore = [self.ignore]
|
||||
|
||||
if (self.ignore.length) {
|
||||
self.ignore = self.ignore.map(ignoreMap)
|
||||
}
|
||||
}
|
||||
|
||||
// ignore patterns are always in dot:true mode.
|
||||
function ignoreMap (pattern) {
|
||||
var gmatcher = null
|
||||
if (pattern.slice(-3) === '/**') {
|
||||
var gpattern = pattern.replace(/(\/\*\*)+$/, '')
|
||||
gmatcher = new Minimatch(gpattern, { dot: true })
|
||||
}
|
||||
|
||||
return {
|
||||
matcher: new Minimatch(pattern, { dot: true }),
|
||||
gmatcher: gmatcher
|
||||
}
|
||||
}
|
||||
|
||||
function setopts (self, pattern, options) {
|
||||
if (!options)
|
||||
options = {}
|
||||
|
||||
// base-matching: just use globstar for that.
|
||||
if (options.matchBase && -1 === pattern.indexOf("/")) {
|
||||
if (options.noglobstar) {
|
||||
throw new Error("base matching requires globstar")
|
||||
}
|
||||
pattern = "**/" + pattern
|
||||
}
|
||||
|
||||
self.windowsPathsNoEscape = !!options.windowsPathsNoEscape ||
|
||||
options.allowWindowsEscape === false
|
||||
if (self.windowsPathsNoEscape) {
|
||||
pattern = pattern.replace(/\\/g, '/')
|
||||
}
|
||||
|
||||
self.silent = !!options.silent
|
||||
self.pattern = pattern
|
||||
self.strict = options.strict !== false
|
||||
self.realpath = !!options.realpath
|
||||
self.realpathCache = options.realpathCache || Object.create(null)
|
||||
self.follow = !!options.follow
|
||||
self.dot = !!options.dot
|
||||
self.mark = !!options.mark
|
||||
self.nodir = !!options.nodir
|
||||
if (self.nodir)
|
||||
self.mark = true
|
||||
self.sync = !!options.sync
|
||||
self.nounique = !!options.nounique
|
||||
self.nonull = !!options.nonull
|
||||
self.nosort = !!options.nosort
|
||||
self.nocase = !!options.nocase
|
||||
self.stat = !!options.stat
|
||||
self.noprocess = !!options.noprocess
|
||||
self.absolute = !!options.absolute
|
||||
self.fs = options.fs || fs
|
||||
|
||||
self.maxLength = options.maxLength || Infinity
|
||||
self.cache = options.cache || Object.create(null)
|
||||
self.statCache = options.statCache || Object.create(null)
|
||||
self.symlinks = options.symlinks || Object.create(null)
|
||||
|
||||
setupIgnores(self, options)
|
||||
|
||||
self.changedCwd = false
|
||||
var cwd = process.cwd()
|
||||
if (!ownProp(options, "cwd"))
|
||||
self.cwd = path.resolve(cwd)
|
||||
else {
|
||||
self.cwd = path.resolve(options.cwd)
|
||||
self.changedCwd = self.cwd !== cwd
|
||||
}
|
||||
|
||||
self.root = options.root || path.resolve(self.cwd, "/")
|
||||
self.root = path.resolve(self.root)
|
||||
|
||||
// TODO: is an absolute `cwd` supposed to be resolved against `root`?
|
||||
// e.g. { cwd: '/test', root: __dirname } === path.join(__dirname, '/test')
|
||||
self.cwdAbs = isAbsolute(self.cwd) ? self.cwd : makeAbs(self, self.cwd)
|
||||
self.nomount = !!options.nomount
|
||||
|
||||
if (process.platform === "win32") {
|
||||
self.root = self.root.replace(/\\/g, "/")
|
||||
self.cwd = self.cwd.replace(/\\/g, "/")
|
||||
self.cwdAbs = self.cwdAbs.replace(/\\/g, "/")
|
||||
}
|
||||
|
||||
// disable comments and negation in Minimatch.
|
||||
// Note that they are not supported in Glob itself anyway.
|
||||
options.nonegate = true
|
||||
options.nocomment = true
|
||||
|
||||
self.minimatch = new Minimatch(pattern, options)
|
||||
self.options = self.minimatch.options
|
||||
}
|
||||
|
||||
function finish (self) {
|
||||
var nou = self.nounique
|
||||
var all = nou ? [] : Object.create(null)
|
||||
|
||||
for (var i = 0, l = self.matches.length; i < l; i ++) {
|
||||
var matches = self.matches[i]
|
||||
if (!matches || Object.keys(matches).length === 0) {
|
||||
if (self.nonull) {
|
||||
// do like the shell, and spit out the literal glob
|
||||
var literal = self.minimatch.globSet[i]
|
||||
if (nou)
|
||||
all.push(literal)
|
||||
else
|
||||
all[literal] = true
|
||||
}
|
||||
} else {
|
||||
// had matches
|
||||
var m = Object.keys(matches)
|
||||
if (nou)
|
||||
all.push.apply(all, m)
|
||||
else
|
||||
m.forEach(function (m) {
|
||||
all[m] = true
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
if (!nou)
|
||||
all = Object.keys(all)
|
||||
|
||||
if (!self.nosort)
|
||||
all = all.sort(alphasort)
|
||||
|
||||
// at *some* point we statted all of these
|
||||
if (self.mark) {
|
||||
for (var i = 0; i < all.length; i++) {
|
||||
all[i] = self._mark(all[i])
|
||||
}
|
||||
if (self.nodir) {
|
||||
all = all.filter(function (e) {
|
||||
var notDir = !(/\/$/.test(e))
|
||||
var c = self.cache[e] || self.cache[makeAbs(self, e)]
|
||||
if (notDir && c)
|
||||
notDir = c !== 'DIR' && !Array.isArray(c)
|
||||
return notDir
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
if (self.ignore.length)
|
||||
all = all.filter(function(m) {
|
||||
return !isIgnored(self, m)
|
||||
})
|
||||
|
||||
self.found = all
|
||||
}
|
||||
|
||||
function mark (self, p) {
|
||||
var abs = makeAbs(self, p)
|
||||
var c = self.cache[abs]
|
||||
var m = p
|
||||
if (c) {
|
||||
var isDir = c === 'DIR' || Array.isArray(c)
|
||||
var slash = p.slice(-1) === '/'
|
||||
|
||||
if (isDir && !slash)
|
||||
m += '/'
|
||||
else if (!isDir && slash)
|
||||
m = m.slice(0, -1)
|
||||
|
||||
if (m !== p) {
|
||||
var mabs = makeAbs(self, m)
|
||||
self.statCache[mabs] = self.statCache[abs]
|
||||
self.cache[mabs] = self.cache[abs]
|
||||
}
|
||||
}
|
||||
|
||||
return m
|
||||
}
|
||||
|
||||
// lotta situps...
|
||||
function makeAbs (self, f) {
|
||||
var abs = f
|
||||
if (f.charAt(0) === '/') {
|
||||
abs = path.join(self.root, f)
|
||||
} else if (isAbsolute(f) || f === '') {
|
||||
abs = f
|
||||
} else if (self.changedCwd) {
|
||||
abs = path.resolve(self.cwd, f)
|
||||
} else {
|
||||
abs = path.resolve(f)
|
||||
}
|
||||
|
||||
if (process.platform === 'win32')
|
||||
abs = abs.replace(/\\/g, '/')
|
||||
|
||||
return abs
|
||||
}
|
||||
|
||||
|
||||
// Return true, if pattern ends with globstar '**', for the accompanying parent directory.
|
||||
// Ex:- If node_modules/** is the pattern, add 'node_modules' to ignore list along with it's contents
|
||||
function isIgnored (self, path) {
|
||||
if (!self.ignore.length)
|
||||
return false
|
||||
|
||||
return self.ignore.some(function(item) {
|
||||
return item.matcher.match(path) || !!(item.gmatcher && item.gmatcher.match(path))
|
||||
})
|
||||
}
|
||||
|
||||
function childrenIgnored (self, path) {
|
||||
if (!self.ignore.length)
|
||||
return false
|
||||
|
||||
return self.ignore.some(function(item) {
|
||||
return !!(item.gmatcher && item.gmatcher.match(path))
|
||||
})
|
||||
}
|
||||
790
electron/node_modules/cacache/node_modules/glob/glob.js
generated
vendored
Normal file
790
electron/node_modules/cacache/node_modules/glob/glob.js
generated
vendored
Normal file
|
|
@ -0,0 +1,790 @@
|
|||
// Approach:
|
||||
//
|
||||
// 1. Get the minimatch set
|
||||
// 2. For each pattern in the set, PROCESS(pattern, false)
|
||||
// 3. Store matches per-set, then uniq them
|
||||
//
|
||||
// PROCESS(pattern, inGlobStar)
|
||||
// Get the first [n] items from pattern that are all strings
|
||||
// Join these together. This is PREFIX.
|
||||
// If there is no more remaining, then stat(PREFIX) and
|
||||
// add to matches if it succeeds. END.
|
||||
//
|
||||
// If inGlobStar and PREFIX is symlink and points to dir
|
||||
// set ENTRIES = []
|
||||
// else readdir(PREFIX) as ENTRIES
|
||||
// If fail, END
|
||||
//
|
||||
// with ENTRIES
|
||||
// If pattern[n] is GLOBSTAR
|
||||
// // handle the case where the globstar match is empty
|
||||
// // by pruning it out, and testing the resulting pattern
|
||||
// PROCESS(pattern[0..n] + pattern[n+1 .. $], false)
|
||||
// // handle other cases.
|
||||
// for ENTRY in ENTRIES (not dotfiles)
|
||||
// // attach globstar + tail onto the entry
|
||||
// // Mark that this entry is a globstar match
|
||||
// PROCESS(pattern[0..n] + ENTRY + pattern[n .. $], true)
|
||||
//
|
||||
// else // not globstar
|
||||
// for ENTRY in ENTRIES (not dotfiles, unless pattern[n] is dot)
|
||||
// Test ENTRY against pattern[n]
|
||||
// If fails, continue
|
||||
// If passes, PROCESS(pattern[0..n] + item + pattern[n+1 .. $])
|
||||
//
|
||||
// Caveat:
|
||||
// Cache all stats and readdirs results to minimize syscall. Since all
|
||||
// we ever care about is existence and directory-ness, we can just keep
|
||||
// `true` for files, and [children,...] for directories, or `false` for
|
||||
// things that don't exist.
|
||||
|
||||
module.exports = glob
|
||||
|
||||
var rp = require('fs.realpath')
|
||||
var minimatch = require('minimatch')
|
||||
var Minimatch = minimatch.Minimatch
|
||||
var inherits = require('inherits')
|
||||
var EE = require('events').EventEmitter
|
||||
var path = require('path')
|
||||
var assert = require('assert')
|
||||
var isAbsolute = require('path').isAbsolute
|
||||
var globSync = require('./sync.js')
|
||||
var common = require('./common.js')
|
||||
var setopts = common.setopts
|
||||
var ownProp = common.ownProp
|
||||
var inflight = require('inflight')
|
||||
var util = require('util')
|
||||
var childrenIgnored = common.childrenIgnored
|
||||
var isIgnored = common.isIgnored
|
||||
|
||||
var once = require('once')
|
||||
|
||||
function glob (pattern, options, cb) {
|
||||
if (typeof options === 'function') cb = options, options = {}
|
||||
if (!options) options = {}
|
||||
|
||||
if (options.sync) {
|
||||
if (cb)
|
||||
throw new TypeError('callback provided to sync glob')
|
||||
return globSync(pattern, options)
|
||||
}
|
||||
|
||||
return new Glob(pattern, options, cb)
|
||||
}
|
||||
|
||||
glob.sync = globSync
|
||||
var GlobSync = glob.GlobSync = globSync.GlobSync
|
||||
|
||||
// old api surface
|
||||
glob.glob = glob
|
||||
|
||||
function extend (origin, add) {
|
||||
if (add === null || typeof add !== 'object') {
|
||||
return origin
|
||||
}
|
||||
|
||||
var keys = Object.keys(add)
|
||||
var i = keys.length
|
||||
while (i--) {
|
||||
origin[keys[i]] = add[keys[i]]
|
||||
}
|
||||
return origin
|
||||
}
|
||||
|
||||
glob.hasMagic = function (pattern, options_) {
|
||||
var options = extend({}, options_)
|
||||
options.noprocess = true
|
||||
|
||||
var g = new Glob(pattern, options)
|
||||
var set = g.minimatch.set
|
||||
|
||||
if (!pattern)
|
||||
return false
|
||||
|
||||
if (set.length > 1)
|
||||
return true
|
||||
|
||||
for (var j = 0; j < set[0].length; j++) {
|
||||
if (typeof set[0][j] !== 'string')
|
||||
return true
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
glob.Glob = Glob
|
||||
inherits(Glob, EE)
|
||||
function Glob (pattern, options, cb) {
|
||||
if (typeof options === 'function') {
|
||||
cb = options
|
||||
options = null
|
||||
}
|
||||
|
||||
if (options && options.sync) {
|
||||
if (cb)
|
||||
throw new TypeError('callback provided to sync glob')
|
||||
return new GlobSync(pattern, options)
|
||||
}
|
||||
|
||||
if (!(this instanceof Glob))
|
||||
return new Glob(pattern, options, cb)
|
||||
|
||||
setopts(this, pattern, options)
|
||||
this._didRealPath = false
|
||||
|
||||
// process each pattern in the minimatch set
|
||||
var n = this.minimatch.set.length
|
||||
|
||||
// The matches are stored as {<filename>: true,...} so that
|
||||
// duplicates are automagically pruned.
|
||||
// Later, we do an Object.keys() on these.
|
||||
// Keep them as a list so we can fill in when nonull is set.
|
||||
this.matches = new Array(n)
|
||||
|
||||
if (typeof cb === 'function') {
|
||||
cb = once(cb)
|
||||
this.on('error', cb)
|
||||
this.on('end', function (matches) {
|
||||
cb(null, matches)
|
||||
})
|
||||
}
|
||||
|
||||
var self = this
|
||||
this._processing = 0
|
||||
|
||||
this._emitQueue = []
|
||||
this._processQueue = []
|
||||
this.paused = false
|
||||
|
||||
if (this.noprocess)
|
||||
return this
|
||||
|
||||
if (n === 0)
|
||||
return done()
|
||||
|
||||
var sync = true
|
||||
for (var i = 0; i < n; i ++) {
|
||||
this._process(this.minimatch.set[i], i, false, done)
|
||||
}
|
||||
sync = false
|
||||
|
||||
function done () {
|
||||
--self._processing
|
||||
if (self._processing <= 0) {
|
||||
if (sync) {
|
||||
process.nextTick(function () {
|
||||
self._finish()
|
||||
})
|
||||
} else {
|
||||
self._finish()
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._finish = function () {
|
||||
assert(this instanceof Glob)
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
if (this.realpath && !this._didRealpath)
|
||||
return this._realpath()
|
||||
|
||||
common.finish(this)
|
||||
this.emit('end', this.found)
|
||||
}
|
||||
|
||||
Glob.prototype._realpath = function () {
|
||||
if (this._didRealpath)
|
||||
return
|
||||
|
||||
this._didRealpath = true
|
||||
|
||||
var n = this.matches.length
|
||||
if (n === 0)
|
||||
return this._finish()
|
||||
|
||||
var self = this
|
||||
for (var i = 0; i < this.matches.length; i++)
|
||||
this._realpathSet(i, next)
|
||||
|
||||
function next () {
|
||||
if (--n === 0)
|
||||
self._finish()
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._realpathSet = function (index, cb) {
|
||||
var matchset = this.matches[index]
|
||||
if (!matchset)
|
||||
return cb()
|
||||
|
||||
var found = Object.keys(matchset)
|
||||
var self = this
|
||||
var n = found.length
|
||||
|
||||
if (n === 0)
|
||||
return cb()
|
||||
|
||||
var set = this.matches[index] = Object.create(null)
|
||||
found.forEach(function (p, i) {
|
||||
// If there's a problem with the stat, then it means that
|
||||
// one or more of the links in the realpath couldn't be
|
||||
// resolved. just return the abs value in that case.
|
||||
p = self._makeAbs(p)
|
||||
rp.realpath(p, self.realpathCache, function (er, real) {
|
||||
if (!er)
|
||||
set[real] = true
|
||||
else if (er.syscall === 'stat')
|
||||
set[p] = true
|
||||
else
|
||||
self.emit('error', er) // srsly wtf right here
|
||||
|
||||
if (--n === 0) {
|
||||
self.matches[index] = set
|
||||
cb()
|
||||
}
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
Glob.prototype._mark = function (p) {
|
||||
return common.mark(this, p)
|
||||
}
|
||||
|
||||
Glob.prototype._makeAbs = function (f) {
|
||||
return common.makeAbs(this, f)
|
||||
}
|
||||
|
||||
Glob.prototype.abort = function () {
|
||||
this.aborted = true
|
||||
this.emit('abort')
|
||||
}
|
||||
|
||||
Glob.prototype.pause = function () {
|
||||
if (!this.paused) {
|
||||
this.paused = true
|
||||
this.emit('pause')
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype.resume = function () {
|
||||
if (this.paused) {
|
||||
this.emit('resume')
|
||||
this.paused = false
|
||||
if (this._emitQueue.length) {
|
||||
var eq = this._emitQueue.slice(0)
|
||||
this._emitQueue.length = 0
|
||||
for (var i = 0; i < eq.length; i ++) {
|
||||
var e = eq[i]
|
||||
this._emitMatch(e[0], e[1])
|
||||
}
|
||||
}
|
||||
if (this._processQueue.length) {
|
||||
var pq = this._processQueue.slice(0)
|
||||
this._processQueue.length = 0
|
||||
for (var i = 0; i < pq.length; i ++) {
|
||||
var p = pq[i]
|
||||
this._processing--
|
||||
this._process(p[0], p[1], p[2], p[3])
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._process = function (pattern, index, inGlobStar, cb) {
|
||||
assert(this instanceof Glob)
|
||||
assert(typeof cb === 'function')
|
||||
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
this._processing++
|
||||
if (this.paused) {
|
||||
this._processQueue.push([pattern, index, inGlobStar, cb])
|
||||
return
|
||||
}
|
||||
|
||||
//console.error('PROCESS %d', this._processing, pattern)
|
||||
|
||||
// Get the first [n] parts of pattern that are all strings.
|
||||
var n = 0
|
||||
while (typeof pattern[n] === 'string') {
|
||||
n ++
|
||||
}
|
||||
// now n is the index of the first one that is *not* a string.
|
||||
|
||||
// see if there's anything else
|
||||
var prefix
|
||||
switch (n) {
|
||||
// if not, then this is rather simple
|
||||
case pattern.length:
|
||||
this._processSimple(pattern.join('/'), index, cb)
|
||||
return
|
||||
|
||||
case 0:
|
||||
// pattern *starts* with some non-trivial item.
|
||||
// going to readdir(cwd), but not include the prefix in matches.
|
||||
prefix = null
|
||||
break
|
||||
|
||||
default:
|
||||
// pattern has some string bits in the front.
|
||||
// whatever it starts with, whether that's 'absolute' like /foo/bar,
|
||||
// or 'relative' like '../baz'
|
||||
prefix = pattern.slice(0, n).join('/')
|
||||
break
|
||||
}
|
||||
|
||||
var remain = pattern.slice(n)
|
||||
|
||||
// get the list of entries.
|
||||
var read
|
||||
if (prefix === null)
|
||||
read = '.'
|
||||
else if (isAbsolute(prefix) ||
|
||||
isAbsolute(pattern.map(function (p) {
|
||||
return typeof p === 'string' ? p : '[*]'
|
||||
}).join('/'))) {
|
||||
if (!prefix || !isAbsolute(prefix))
|
||||
prefix = '/' + prefix
|
||||
read = prefix
|
||||
} else
|
||||
read = prefix
|
||||
|
||||
var abs = this._makeAbs(read)
|
||||
|
||||
//if ignored, skip _processing
|
||||
if (childrenIgnored(this, read))
|
||||
return cb()
|
||||
|
||||
var isGlobStar = remain[0] === minimatch.GLOBSTAR
|
||||
if (isGlobStar)
|
||||
this._processGlobStar(prefix, read, abs, remain, index, inGlobStar, cb)
|
||||
else
|
||||
this._processReaddir(prefix, read, abs, remain, index, inGlobStar, cb)
|
||||
}
|
||||
|
||||
Glob.prototype._processReaddir = function (prefix, read, abs, remain, index, inGlobStar, cb) {
|
||||
var self = this
|
||||
this._readdir(abs, inGlobStar, function (er, entries) {
|
||||
return self._processReaddir2(prefix, read, abs, remain, index, inGlobStar, entries, cb)
|
||||
})
|
||||
}
|
||||
|
||||
Glob.prototype._processReaddir2 = function (prefix, read, abs, remain, index, inGlobStar, entries, cb) {
|
||||
|
||||
// if the abs isn't a dir, then nothing can match!
|
||||
if (!entries)
|
||||
return cb()
|
||||
|
||||
// It will only match dot entries if it starts with a dot, or if
|
||||
// dot is set. Stuff like @(.foo|.bar) isn't allowed.
|
||||
var pn = remain[0]
|
||||
var negate = !!this.minimatch.negate
|
||||
var rawGlob = pn._glob
|
||||
var dotOk = this.dot || rawGlob.charAt(0) === '.'
|
||||
|
||||
var matchedEntries = []
|
||||
for (var i = 0; i < entries.length; i++) {
|
||||
var e = entries[i]
|
||||
if (e.charAt(0) !== '.' || dotOk) {
|
||||
var m
|
||||
if (negate && !prefix) {
|
||||
m = !e.match(pn)
|
||||
} else {
|
||||
m = e.match(pn)
|
||||
}
|
||||
if (m)
|
||||
matchedEntries.push(e)
|
||||
}
|
||||
}
|
||||
|
||||
//console.error('prd2', prefix, entries, remain[0]._glob, matchedEntries)
|
||||
|
||||
var len = matchedEntries.length
|
||||
// If there are no matched entries, then nothing matches.
|
||||
if (len === 0)
|
||||
return cb()
|
||||
|
||||
// if this is the last remaining pattern bit, then no need for
|
||||
// an additional stat *unless* the user has specified mark or
|
||||
// stat explicitly. We know they exist, since readdir returned
|
||||
// them.
|
||||
|
||||
if (remain.length === 1 && !this.mark && !this.stat) {
|
||||
if (!this.matches[index])
|
||||
this.matches[index] = Object.create(null)
|
||||
|
||||
for (var i = 0; i < len; i ++) {
|
||||
var e = matchedEntries[i]
|
||||
if (prefix) {
|
||||
if (prefix !== '/')
|
||||
e = prefix + '/' + e
|
||||
else
|
||||
e = prefix + e
|
||||
}
|
||||
|
||||
if (e.charAt(0) === '/' && !this.nomount) {
|
||||
e = path.join(this.root, e)
|
||||
}
|
||||
this._emitMatch(index, e)
|
||||
}
|
||||
// This was the last one, and no stats were needed
|
||||
return cb()
|
||||
}
|
||||
|
||||
// now test all matched entries as stand-ins for that part
|
||||
// of the pattern.
|
||||
remain.shift()
|
||||
for (var i = 0; i < len; i ++) {
|
||||
var e = matchedEntries[i]
|
||||
var newPattern
|
||||
if (prefix) {
|
||||
if (prefix !== '/')
|
||||
e = prefix + '/' + e
|
||||
else
|
||||
e = prefix + e
|
||||
}
|
||||
this._process([e].concat(remain), index, inGlobStar, cb)
|
||||
}
|
||||
cb()
|
||||
}
|
||||
|
||||
Glob.prototype._emitMatch = function (index, e) {
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
if (isIgnored(this, e))
|
||||
return
|
||||
|
||||
if (this.paused) {
|
||||
this._emitQueue.push([index, e])
|
||||
return
|
||||
}
|
||||
|
||||
var abs = isAbsolute(e) ? e : this._makeAbs(e)
|
||||
|
||||
if (this.mark)
|
||||
e = this._mark(e)
|
||||
|
||||
if (this.absolute)
|
||||
e = abs
|
||||
|
||||
if (this.matches[index][e])
|
||||
return
|
||||
|
||||
if (this.nodir) {
|
||||
var c = this.cache[abs]
|
||||
if (c === 'DIR' || Array.isArray(c))
|
||||
return
|
||||
}
|
||||
|
||||
this.matches[index][e] = true
|
||||
|
||||
var st = this.statCache[abs]
|
||||
if (st)
|
||||
this.emit('stat', e, st)
|
||||
|
||||
this.emit('match', e)
|
||||
}
|
||||
|
||||
Glob.prototype._readdirInGlobStar = function (abs, cb) {
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
// follow all symlinked directories forever
|
||||
// just proceed as if this is a non-globstar situation
|
||||
if (this.follow)
|
||||
return this._readdir(abs, false, cb)
|
||||
|
||||
var lstatkey = 'lstat\0' + abs
|
||||
var self = this
|
||||
var lstatcb = inflight(lstatkey, lstatcb_)
|
||||
|
||||
if (lstatcb)
|
||||
self.fs.lstat(abs, lstatcb)
|
||||
|
||||
function lstatcb_ (er, lstat) {
|
||||
if (er && er.code === 'ENOENT')
|
||||
return cb()
|
||||
|
||||
var isSym = lstat && lstat.isSymbolicLink()
|
||||
self.symlinks[abs] = isSym
|
||||
|
||||
// If it's not a symlink or a dir, then it's definitely a regular file.
|
||||
// don't bother doing a readdir in that case.
|
||||
if (!isSym && lstat && !lstat.isDirectory()) {
|
||||
self.cache[abs] = 'FILE'
|
||||
cb()
|
||||
} else
|
||||
self._readdir(abs, false, cb)
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._readdir = function (abs, inGlobStar, cb) {
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
cb = inflight('readdir\0'+abs+'\0'+inGlobStar, cb)
|
||||
if (!cb)
|
||||
return
|
||||
|
||||
//console.error('RD %j %j', +inGlobStar, abs)
|
||||
if (inGlobStar && !ownProp(this.symlinks, abs))
|
||||
return this._readdirInGlobStar(abs, cb)
|
||||
|
||||
if (ownProp(this.cache, abs)) {
|
||||
var c = this.cache[abs]
|
||||
if (!c || c === 'FILE')
|
||||
return cb()
|
||||
|
||||
if (Array.isArray(c))
|
||||
return cb(null, c)
|
||||
}
|
||||
|
||||
var self = this
|
||||
self.fs.readdir(abs, readdirCb(this, abs, cb))
|
||||
}
|
||||
|
||||
function readdirCb (self, abs, cb) {
|
||||
return function (er, entries) {
|
||||
if (er)
|
||||
self._readdirError(abs, er, cb)
|
||||
else
|
||||
self._readdirEntries(abs, entries, cb)
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._readdirEntries = function (abs, entries, cb) {
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
// if we haven't asked to stat everything, then just
|
||||
// assume that everything in there exists, so we can avoid
|
||||
// having to stat it a second time.
|
||||
if (!this.mark && !this.stat) {
|
||||
for (var i = 0; i < entries.length; i ++) {
|
||||
var e = entries[i]
|
||||
if (abs === '/')
|
||||
e = abs + e
|
||||
else
|
||||
e = abs + '/' + e
|
||||
this.cache[e] = true
|
||||
}
|
||||
}
|
||||
|
||||
this.cache[abs] = entries
|
||||
return cb(null, entries)
|
||||
}
|
||||
|
||||
Glob.prototype._readdirError = function (f, er, cb) {
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
// handle errors, and cache the information
|
||||
switch (er.code) {
|
||||
case 'ENOTSUP': // https://github.com/isaacs/node-glob/issues/205
|
||||
case 'ENOTDIR': // totally normal. means it *does* exist.
|
||||
var abs = this._makeAbs(f)
|
||||
this.cache[abs] = 'FILE'
|
||||
if (abs === this.cwdAbs) {
|
||||
var error = new Error(er.code + ' invalid cwd ' + this.cwd)
|
||||
error.path = this.cwd
|
||||
error.code = er.code
|
||||
this.emit('error', error)
|
||||
this.abort()
|
||||
}
|
||||
break
|
||||
|
||||
case 'ENOENT': // not terribly unusual
|
||||
case 'ELOOP':
|
||||
case 'ENAMETOOLONG':
|
||||
case 'UNKNOWN':
|
||||
this.cache[this._makeAbs(f)] = false
|
||||
break
|
||||
|
||||
default: // some unusual error. Treat as failure.
|
||||
this.cache[this._makeAbs(f)] = false
|
||||
if (this.strict) {
|
||||
this.emit('error', er)
|
||||
// If the error is handled, then we abort
|
||||
// if not, we threw out of here
|
||||
this.abort()
|
||||
}
|
||||
if (!this.silent)
|
||||
console.error('glob error', er)
|
||||
break
|
||||
}
|
||||
|
||||
return cb()
|
||||
}
|
||||
|
||||
Glob.prototype._processGlobStar = function (prefix, read, abs, remain, index, inGlobStar, cb) {
|
||||
var self = this
|
||||
this._readdir(abs, inGlobStar, function (er, entries) {
|
||||
self._processGlobStar2(prefix, read, abs, remain, index, inGlobStar, entries, cb)
|
||||
})
|
||||
}
|
||||
|
||||
|
||||
Glob.prototype._processGlobStar2 = function (prefix, read, abs, remain, index, inGlobStar, entries, cb) {
|
||||
//console.error('pgs2', prefix, remain[0], entries)
|
||||
|
||||
// no entries means not a dir, so it can never have matches
|
||||
// foo.txt/** doesn't match foo.txt
|
||||
if (!entries)
|
||||
return cb()
|
||||
|
||||
// test without the globstar, and with every child both below
|
||||
// and replacing the globstar.
|
||||
var remainWithoutGlobStar = remain.slice(1)
|
||||
var gspref = prefix ? [ prefix ] : []
|
||||
var noGlobStar = gspref.concat(remainWithoutGlobStar)
|
||||
|
||||
// the noGlobStar pattern exits the inGlobStar state
|
||||
this._process(noGlobStar, index, false, cb)
|
||||
|
||||
var isSym = this.symlinks[abs]
|
||||
var len = entries.length
|
||||
|
||||
// If it's a symlink, and we're in a globstar, then stop
|
||||
if (isSym && inGlobStar)
|
||||
return cb()
|
||||
|
||||
for (var i = 0; i < len; i++) {
|
||||
var e = entries[i]
|
||||
if (e.charAt(0) === '.' && !this.dot)
|
||||
continue
|
||||
|
||||
// these two cases enter the inGlobStar state
|
||||
var instead = gspref.concat(entries[i], remainWithoutGlobStar)
|
||||
this._process(instead, index, true, cb)
|
||||
|
||||
var below = gspref.concat(entries[i], remain)
|
||||
this._process(below, index, true, cb)
|
||||
}
|
||||
|
||||
cb()
|
||||
}
|
||||
|
||||
Glob.prototype._processSimple = function (prefix, index, cb) {
|
||||
// XXX review this. Shouldn't it be doing the mounting etc
|
||||
// before doing stat? kinda weird?
|
||||
var self = this
|
||||
this._stat(prefix, function (er, exists) {
|
||||
self._processSimple2(prefix, index, er, exists, cb)
|
||||
})
|
||||
}
|
||||
Glob.prototype._processSimple2 = function (prefix, index, er, exists, cb) {
|
||||
|
||||
//console.error('ps2', prefix, exists)
|
||||
|
||||
if (!this.matches[index])
|
||||
this.matches[index] = Object.create(null)
|
||||
|
||||
// If it doesn't exist, then just mark the lack of results
|
||||
if (!exists)
|
||||
return cb()
|
||||
|
||||
if (prefix && isAbsolute(prefix) && !this.nomount) {
|
||||
var trail = /[\/\\]$/.test(prefix)
|
||||
if (prefix.charAt(0) === '/') {
|
||||
prefix = path.join(this.root, prefix)
|
||||
} else {
|
||||
prefix = path.resolve(this.root, prefix)
|
||||
if (trail)
|
||||
prefix += '/'
|
||||
}
|
||||
}
|
||||
|
||||
if (process.platform === 'win32')
|
||||
prefix = prefix.replace(/\\/g, '/')
|
||||
|
||||
// Mark this as a match
|
||||
this._emitMatch(index, prefix)
|
||||
cb()
|
||||
}
|
||||
|
||||
// Returns either 'DIR', 'FILE', or false
|
||||
Glob.prototype._stat = function (f, cb) {
|
||||
var abs = this._makeAbs(f)
|
||||
var needDir = f.slice(-1) === '/'
|
||||
|
||||
if (f.length > this.maxLength)
|
||||
return cb()
|
||||
|
||||
if (!this.stat && ownProp(this.cache, abs)) {
|
||||
var c = this.cache[abs]
|
||||
|
||||
if (Array.isArray(c))
|
||||
c = 'DIR'
|
||||
|
||||
// It exists, but maybe not how we need it
|
||||
if (!needDir || c === 'DIR')
|
||||
return cb(null, c)
|
||||
|
||||
if (needDir && c === 'FILE')
|
||||
return cb()
|
||||
|
||||
// otherwise we have to stat, because maybe c=true
|
||||
// if we know it exists, but not what it is.
|
||||
}
|
||||
|
||||
var exists
|
||||
var stat = this.statCache[abs]
|
||||
if (stat !== undefined) {
|
||||
if (stat === false)
|
||||
return cb(null, stat)
|
||||
else {
|
||||
var type = stat.isDirectory() ? 'DIR' : 'FILE'
|
||||
if (needDir && type === 'FILE')
|
||||
return cb()
|
||||
else
|
||||
return cb(null, type, stat)
|
||||
}
|
||||
}
|
||||
|
||||
var self = this
|
||||
var statcb = inflight('stat\0' + abs, lstatcb_)
|
||||
if (statcb)
|
||||
self.fs.lstat(abs, statcb)
|
||||
|
||||
function lstatcb_ (er, lstat) {
|
||||
if (lstat && lstat.isSymbolicLink()) {
|
||||
// If it's a symlink, then treat it as the target, unless
|
||||
// the target does not exist, then treat it as a file.
|
||||
return self.fs.stat(abs, function (er, stat) {
|
||||
if (er)
|
||||
self._stat2(f, abs, null, lstat, cb)
|
||||
else
|
||||
self._stat2(f, abs, er, stat, cb)
|
||||
})
|
||||
} else {
|
||||
self._stat2(f, abs, er, lstat, cb)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._stat2 = function (f, abs, er, stat, cb) {
|
||||
if (er && (er.code === 'ENOENT' || er.code === 'ENOTDIR')) {
|
||||
this.statCache[abs] = false
|
||||
return cb()
|
||||
}
|
||||
|
||||
var needDir = f.slice(-1) === '/'
|
||||
this.statCache[abs] = stat
|
||||
|
||||
if (abs.slice(-1) === '/' && stat && !stat.isDirectory())
|
||||
return cb(null, false, stat)
|
||||
|
||||
var c = true
|
||||
if (stat)
|
||||
c = stat.isDirectory() ? 'DIR' : 'FILE'
|
||||
this.cache[abs] = this.cache[abs] || c
|
||||
|
||||
if (needDir && c === 'FILE')
|
||||
return cb()
|
||||
|
||||
return cb(null, c, stat)
|
||||
}
|
||||
55
electron/node_modules/cacache/node_modules/glob/package.json
generated
vendored
Normal file
55
electron/node_modules/cacache/node_modules/glob/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,55 @@
|
|||
{
|
||||
"author": "Isaac Z. Schlueter <i@izs.me> (http://blog.izs.me/)",
|
||||
"name": "glob",
|
||||
"description": "a little globber",
|
||||
"version": "8.1.0",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/isaacs/node-glob.git"
|
||||
},
|
||||
"main": "glob.js",
|
||||
"files": [
|
||||
"glob.js",
|
||||
"sync.js",
|
||||
"common.js"
|
||||
],
|
||||
"engines": {
|
||||
"node": ">=12"
|
||||
},
|
||||
"dependencies": {
|
||||
"fs.realpath": "^1.0.0",
|
||||
"inflight": "^1.0.4",
|
||||
"inherits": "2",
|
||||
"minimatch": "^5.0.1",
|
||||
"once": "^1.3.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"memfs": "^3.2.0",
|
||||
"mkdirp": "0",
|
||||
"rimraf": "^2.2.8",
|
||||
"tap": "^16.0.1",
|
||||
"tick": "0.0.6"
|
||||
},
|
||||
"tap": {
|
||||
"before": "test/00-setup.js",
|
||||
"after": "test/zz-cleanup.js",
|
||||
"statements": 90,
|
||||
"branches": 90,
|
||||
"functions": 90,
|
||||
"lines": 90,
|
||||
"jobs": 1
|
||||
},
|
||||
"scripts": {
|
||||
"prepublish": "npm run benchclean",
|
||||
"profclean": "rm -f v8.log profile.txt",
|
||||
"test": "tap",
|
||||
"test-regen": "npm run profclean && TEST_REGEN=1 node test/00-setup.js",
|
||||
"bench": "bash benchmark.sh",
|
||||
"prof": "bash prof.sh && cat profile.txt",
|
||||
"benchclean": "node benchclean.js"
|
||||
},
|
||||
"license": "ISC",
|
||||
"funding": {
|
||||
"url": "https://github.com/sponsors/isaacs"
|
||||
}
|
||||
}
|
||||
486
electron/node_modules/cacache/node_modules/glob/sync.js
generated
vendored
Normal file
486
electron/node_modules/cacache/node_modules/glob/sync.js
generated
vendored
Normal file
|
|
@ -0,0 +1,486 @@
|
|||
module.exports = globSync
|
||||
globSync.GlobSync = GlobSync
|
||||
|
||||
var rp = require('fs.realpath')
|
||||
var minimatch = require('minimatch')
|
||||
var Minimatch = minimatch.Minimatch
|
||||
var Glob = require('./glob.js').Glob
|
||||
var util = require('util')
|
||||
var path = require('path')
|
||||
var assert = require('assert')
|
||||
var isAbsolute = require('path').isAbsolute
|
||||
var common = require('./common.js')
|
||||
var setopts = common.setopts
|
||||
var ownProp = common.ownProp
|
||||
var childrenIgnored = common.childrenIgnored
|
||||
var isIgnored = common.isIgnored
|
||||
|
||||
function globSync (pattern, options) {
|
||||
if (typeof options === 'function' || arguments.length === 3)
|
||||
throw new TypeError('callback provided to sync glob\n'+
|
||||
'See: https://github.com/isaacs/node-glob/issues/167')
|
||||
|
||||
return new GlobSync(pattern, options).found
|
||||
}
|
||||
|
||||
function GlobSync (pattern, options) {
|
||||
if (!pattern)
|
||||
throw new Error('must provide pattern')
|
||||
|
||||
if (typeof options === 'function' || arguments.length === 3)
|
||||
throw new TypeError('callback provided to sync glob\n'+
|
||||
'See: https://github.com/isaacs/node-glob/issues/167')
|
||||
|
||||
if (!(this instanceof GlobSync))
|
||||
return new GlobSync(pattern, options)
|
||||
|
||||
setopts(this, pattern, options)
|
||||
|
||||
if (this.noprocess)
|
||||
return this
|
||||
|
||||
var n = this.minimatch.set.length
|
||||
this.matches = new Array(n)
|
||||
for (var i = 0; i < n; i ++) {
|
||||
this._process(this.minimatch.set[i], i, false)
|
||||
}
|
||||
this._finish()
|
||||
}
|
||||
|
||||
GlobSync.prototype._finish = function () {
|
||||
assert.ok(this instanceof GlobSync)
|
||||
if (this.realpath) {
|
||||
var self = this
|
||||
this.matches.forEach(function (matchset, index) {
|
||||
var set = self.matches[index] = Object.create(null)
|
||||
for (var p in matchset) {
|
||||
try {
|
||||
p = self._makeAbs(p)
|
||||
var real = rp.realpathSync(p, self.realpathCache)
|
||||
set[real] = true
|
||||
} catch (er) {
|
||||
if (er.syscall === 'stat')
|
||||
set[self._makeAbs(p)] = true
|
||||
else
|
||||
throw er
|
||||
}
|
||||
}
|
||||
})
|
||||
}
|
||||
common.finish(this)
|
||||
}
|
||||
|
||||
|
||||
GlobSync.prototype._process = function (pattern, index, inGlobStar) {
|
||||
assert.ok(this instanceof GlobSync)
|
||||
|
||||
// Get the first [n] parts of pattern that are all strings.
|
||||
var n = 0
|
||||
while (typeof pattern[n] === 'string') {
|
||||
n ++
|
||||
}
|
||||
// now n is the index of the first one that is *not* a string.
|
||||
|
||||
// See if there's anything else
|
||||
var prefix
|
||||
switch (n) {
|
||||
// if not, then this is rather simple
|
||||
case pattern.length:
|
||||
this._processSimple(pattern.join('/'), index)
|
||||
return
|
||||
|
||||
case 0:
|
||||
// pattern *starts* with some non-trivial item.
|
||||
// going to readdir(cwd), but not include the prefix in matches.
|
||||
prefix = null
|
||||
break
|
||||
|
||||
default:
|
||||
// pattern has some string bits in the front.
|
||||
// whatever it starts with, whether that's 'absolute' like /foo/bar,
|
||||
// or 'relative' like '../baz'
|
||||
prefix = pattern.slice(0, n).join('/')
|
||||
break
|
||||
}
|
||||
|
||||
var remain = pattern.slice(n)
|
||||
|
||||
// get the list of entries.
|
||||
var read
|
||||
if (prefix === null)
|
||||
read = '.'
|
||||
else if (isAbsolute(prefix) ||
|
||||
isAbsolute(pattern.map(function (p) {
|
||||
return typeof p === 'string' ? p : '[*]'
|
||||
}).join('/'))) {
|
||||
if (!prefix || !isAbsolute(prefix))
|
||||
prefix = '/' + prefix
|
||||
read = prefix
|
||||
} else
|
||||
read = prefix
|
||||
|
||||
var abs = this._makeAbs(read)
|
||||
|
||||
//if ignored, skip processing
|
||||
if (childrenIgnored(this, read))
|
||||
return
|
||||
|
||||
var isGlobStar = remain[0] === minimatch.GLOBSTAR
|
||||
if (isGlobStar)
|
||||
this._processGlobStar(prefix, read, abs, remain, index, inGlobStar)
|
||||
else
|
||||
this._processReaddir(prefix, read, abs, remain, index, inGlobStar)
|
||||
}
|
||||
|
||||
|
||||
GlobSync.prototype._processReaddir = function (prefix, read, abs, remain, index, inGlobStar) {
|
||||
var entries = this._readdir(abs, inGlobStar)
|
||||
|
||||
// if the abs isn't a dir, then nothing can match!
|
||||
if (!entries)
|
||||
return
|
||||
|
||||
// It will only match dot entries if it starts with a dot, or if
|
||||
// dot is set. Stuff like @(.foo|.bar) isn't allowed.
|
||||
var pn = remain[0]
|
||||
var negate = !!this.minimatch.negate
|
||||
var rawGlob = pn._glob
|
||||
var dotOk = this.dot || rawGlob.charAt(0) === '.'
|
||||
|
||||
var matchedEntries = []
|
||||
for (var i = 0; i < entries.length; i++) {
|
||||
var e = entries[i]
|
||||
if (e.charAt(0) !== '.' || dotOk) {
|
||||
var m
|
||||
if (negate && !prefix) {
|
||||
m = !e.match(pn)
|
||||
} else {
|
||||
m = e.match(pn)
|
||||
}
|
||||
if (m)
|
||||
matchedEntries.push(e)
|
||||
}
|
||||
}
|
||||
|
||||
var len = matchedEntries.length
|
||||
// If there are no matched entries, then nothing matches.
|
||||
if (len === 0)
|
||||
return
|
||||
|
||||
// if this is the last remaining pattern bit, then no need for
|
||||
// an additional stat *unless* the user has specified mark or
|
||||
// stat explicitly. We know they exist, since readdir returned
|
||||
// them.
|
||||
|
||||
if (remain.length === 1 && !this.mark && !this.stat) {
|
||||
if (!this.matches[index])
|
||||
this.matches[index] = Object.create(null)
|
||||
|
||||
for (var i = 0; i < len; i ++) {
|
||||
var e = matchedEntries[i]
|
||||
if (prefix) {
|
||||
if (prefix.slice(-1) !== '/')
|
||||
e = prefix + '/' + e
|
||||
else
|
||||
e = prefix + e
|
||||
}
|
||||
|
||||
if (e.charAt(0) === '/' && !this.nomount) {
|
||||
e = path.join(this.root, e)
|
||||
}
|
||||
this._emitMatch(index, e)
|
||||
}
|
||||
// This was the last one, and no stats were needed
|
||||
return
|
||||
}
|
||||
|
||||
// now test all matched entries as stand-ins for that part
|
||||
// of the pattern.
|
||||
remain.shift()
|
||||
for (var i = 0; i < len; i ++) {
|
||||
var e = matchedEntries[i]
|
||||
var newPattern
|
||||
if (prefix)
|
||||
newPattern = [prefix, e]
|
||||
else
|
||||
newPattern = [e]
|
||||
this._process(newPattern.concat(remain), index, inGlobStar)
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
GlobSync.prototype._emitMatch = function (index, e) {
|
||||
if (isIgnored(this, e))
|
||||
return
|
||||
|
||||
var abs = this._makeAbs(e)
|
||||
|
||||
if (this.mark)
|
||||
e = this._mark(e)
|
||||
|
||||
if (this.absolute) {
|
||||
e = abs
|
||||
}
|
||||
|
||||
if (this.matches[index][e])
|
||||
return
|
||||
|
||||
if (this.nodir) {
|
||||
var c = this.cache[abs]
|
||||
if (c === 'DIR' || Array.isArray(c))
|
||||
return
|
||||
}
|
||||
|
||||
this.matches[index][e] = true
|
||||
|
||||
if (this.stat)
|
||||
this._stat(e)
|
||||
}
|
||||
|
||||
|
||||
GlobSync.prototype._readdirInGlobStar = function (abs) {
|
||||
// follow all symlinked directories forever
|
||||
// just proceed as if this is a non-globstar situation
|
||||
if (this.follow)
|
||||
return this._readdir(abs, false)
|
||||
|
||||
var entries
|
||||
var lstat
|
||||
var stat
|
||||
try {
|
||||
lstat = this.fs.lstatSync(abs)
|
||||
} catch (er) {
|
||||
if (er.code === 'ENOENT') {
|
||||
// lstat failed, doesn't exist
|
||||
return null
|
||||
}
|
||||
}
|
||||
|
||||
var isSym = lstat && lstat.isSymbolicLink()
|
||||
this.symlinks[abs] = isSym
|
||||
|
||||
// If it's not a symlink or a dir, then it's definitely a regular file.
|
||||
// don't bother doing a readdir in that case.
|
||||
if (!isSym && lstat && !lstat.isDirectory())
|
||||
this.cache[abs] = 'FILE'
|
||||
else
|
||||
entries = this._readdir(abs, false)
|
||||
|
||||
return entries
|
||||
}
|
||||
|
||||
GlobSync.prototype._readdir = function (abs, inGlobStar) {
|
||||
var entries
|
||||
|
||||
if (inGlobStar && !ownProp(this.symlinks, abs))
|
||||
return this._readdirInGlobStar(abs)
|
||||
|
||||
if (ownProp(this.cache, abs)) {
|
||||
var c = this.cache[abs]
|
||||
if (!c || c === 'FILE')
|
||||
return null
|
||||
|
||||
if (Array.isArray(c))
|
||||
return c
|
||||
}
|
||||
|
||||
try {
|
||||
return this._readdirEntries(abs, this.fs.readdirSync(abs))
|
||||
} catch (er) {
|
||||
this._readdirError(abs, er)
|
||||
return null
|
||||
}
|
||||
}
|
||||
|
||||
GlobSync.prototype._readdirEntries = function (abs, entries) {
|
||||
// if we haven't asked to stat everything, then just
|
||||
// assume that everything in there exists, so we can avoid
|
||||
// having to stat it a second time.
|
||||
if (!this.mark && !this.stat) {
|
||||
for (var i = 0; i < entries.length; i ++) {
|
||||
var e = entries[i]
|
||||
if (abs === '/')
|
||||
e = abs + e
|
||||
else
|
||||
e = abs + '/' + e
|
||||
this.cache[e] = true
|
||||
}
|
||||
}
|
||||
|
||||
this.cache[abs] = entries
|
||||
|
||||
// mark and cache dir-ness
|
||||
return entries
|
||||
}
|
||||
|
||||
GlobSync.prototype._readdirError = function (f, er) {
|
||||
// handle errors, and cache the information
|
||||
switch (er.code) {
|
||||
case 'ENOTSUP': // https://github.com/isaacs/node-glob/issues/205
|
||||
case 'ENOTDIR': // totally normal. means it *does* exist.
|
||||
var abs = this._makeAbs(f)
|
||||
this.cache[abs] = 'FILE'
|
||||
if (abs === this.cwdAbs) {
|
||||
var error = new Error(er.code + ' invalid cwd ' + this.cwd)
|
||||
error.path = this.cwd
|
||||
error.code = er.code
|
||||
throw error
|
||||
}
|
||||
break
|
||||
|
||||
case 'ENOENT': // not terribly unusual
|
||||
case 'ELOOP':
|
||||
case 'ENAMETOOLONG':
|
||||
case 'UNKNOWN':
|
||||
this.cache[this._makeAbs(f)] = false
|
||||
break
|
||||
|
||||
default: // some unusual error. Treat as failure.
|
||||
this.cache[this._makeAbs(f)] = false
|
||||
if (this.strict)
|
||||
throw er
|
||||
if (!this.silent)
|
||||
console.error('glob error', er)
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
GlobSync.prototype._processGlobStar = function (prefix, read, abs, remain, index, inGlobStar) {
|
||||
|
||||
var entries = this._readdir(abs, inGlobStar)
|
||||
|
||||
// no entries means not a dir, so it can never have matches
|
||||
// foo.txt/** doesn't match foo.txt
|
||||
if (!entries)
|
||||
return
|
||||
|
||||
// test without the globstar, and with every child both below
|
||||
// and replacing the globstar.
|
||||
var remainWithoutGlobStar = remain.slice(1)
|
||||
var gspref = prefix ? [ prefix ] : []
|
||||
var noGlobStar = gspref.concat(remainWithoutGlobStar)
|
||||
|
||||
// the noGlobStar pattern exits the inGlobStar state
|
||||
this._process(noGlobStar, index, false)
|
||||
|
||||
var len = entries.length
|
||||
var isSym = this.symlinks[abs]
|
||||
|
||||
// If it's a symlink, and we're in a globstar, then stop
|
||||
if (isSym && inGlobStar)
|
||||
return
|
||||
|
||||
for (var i = 0; i < len; i++) {
|
||||
var e = entries[i]
|
||||
if (e.charAt(0) === '.' && !this.dot)
|
||||
continue
|
||||
|
||||
// these two cases enter the inGlobStar state
|
||||
var instead = gspref.concat(entries[i], remainWithoutGlobStar)
|
||||
this._process(instead, index, true)
|
||||
|
||||
var below = gspref.concat(entries[i], remain)
|
||||
this._process(below, index, true)
|
||||
}
|
||||
}
|
||||
|
||||
GlobSync.prototype._processSimple = function (prefix, index) {
|
||||
// XXX review this. Shouldn't it be doing the mounting etc
|
||||
// before doing stat? kinda weird?
|
||||
var exists = this._stat(prefix)
|
||||
|
||||
if (!this.matches[index])
|
||||
this.matches[index] = Object.create(null)
|
||||
|
||||
// If it doesn't exist, then just mark the lack of results
|
||||
if (!exists)
|
||||
return
|
||||
|
||||
if (prefix && isAbsolute(prefix) && !this.nomount) {
|
||||
var trail = /[\/\\]$/.test(prefix)
|
||||
if (prefix.charAt(0) === '/') {
|
||||
prefix = path.join(this.root, prefix)
|
||||
} else {
|
||||
prefix = path.resolve(this.root, prefix)
|
||||
if (trail)
|
||||
prefix += '/'
|
||||
}
|
||||
}
|
||||
|
||||
if (process.platform === 'win32')
|
||||
prefix = prefix.replace(/\\/g, '/')
|
||||
|
||||
// Mark this as a match
|
||||
this._emitMatch(index, prefix)
|
||||
}
|
||||
|
||||
// Returns either 'DIR', 'FILE', or false
|
||||
GlobSync.prototype._stat = function (f) {
|
||||
var abs = this._makeAbs(f)
|
||||
var needDir = f.slice(-1) === '/'
|
||||
|
||||
if (f.length > this.maxLength)
|
||||
return false
|
||||
|
||||
if (!this.stat && ownProp(this.cache, abs)) {
|
||||
var c = this.cache[abs]
|
||||
|
||||
if (Array.isArray(c))
|
||||
c = 'DIR'
|
||||
|
||||
// It exists, but maybe not how we need it
|
||||
if (!needDir || c === 'DIR')
|
||||
return c
|
||||
|
||||
if (needDir && c === 'FILE')
|
||||
return false
|
||||
|
||||
// otherwise we have to stat, because maybe c=true
|
||||
// if we know it exists, but not what it is.
|
||||
}
|
||||
|
||||
var exists
|
||||
var stat = this.statCache[abs]
|
||||
if (!stat) {
|
||||
var lstat
|
||||
try {
|
||||
lstat = this.fs.lstatSync(abs)
|
||||
} catch (er) {
|
||||
if (er && (er.code === 'ENOENT' || er.code === 'ENOTDIR')) {
|
||||
this.statCache[abs] = false
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
if (lstat && lstat.isSymbolicLink()) {
|
||||
try {
|
||||
stat = this.fs.statSync(abs)
|
||||
} catch (er) {
|
||||
stat = lstat
|
||||
}
|
||||
} else {
|
||||
stat = lstat
|
||||
}
|
||||
}
|
||||
|
||||
this.statCache[abs] = stat
|
||||
|
||||
var c = true
|
||||
if (stat)
|
||||
c = stat.isDirectory() ? 'DIR' : 'FILE'
|
||||
|
||||
this.cache[abs] = this.cache[abs] || c
|
||||
|
||||
if (needDir && c === 'FILE')
|
||||
return false
|
||||
|
||||
return c
|
||||
}
|
||||
|
||||
GlobSync.prototype._mark = function (p) {
|
||||
return common.mark(this, p)
|
||||
}
|
||||
|
||||
GlobSync.prototype._makeAbs = function (f) {
|
||||
return common.makeAbs(this, f)
|
||||
}
|
||||
15
electron/node_modules/cacache/node_modules/lru-cache/LICENSE
generated
vendored
Normal file
15
electron/node_modules/cacache/node_modules/lru-cache/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
The ISC License
|
||||
|
||||
Copyright (c) 2010-2023 Isaac Z. Schlueter and Contributors
|
||||
|
||||
Permission to use, copy, modify, and/or distribute this software for any
|
||||
purpose with or without fee is hereby granted, provided that the above
|
||||
copyright notice and this permission notice appear in all copies.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
||||
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
||||
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
||||
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
||||
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR
|
||||
IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
1117
electron/node_modules/cacache/node_modules/lru-cache/README.md
generated
vendored
Normal file
1117
electron/node_modules/cacache/node_modules/lru-cache/README.md
generated
vendored
Normal file
File diff suppressed because it is too large
Load diff
869
electron/node_modules/cacache/node_modules/lru-cache/index.d.ts
generated
vendored
Normal file
869
electron/node_modules/cacache/node_modules/lru-cache/index.d.ts
generated
vendored
Normal file
|
|
@ -0,0 +1,869 @@
|
|||
// Project: https://github.com/isaacs/node-lru-cache
|
||||
// Based initially on @types/lru-cache
|
||||
// https://github.com/DefinitelyTyped/DefinitelyTyped
|
||||
// used under the terms of the MIT License, shown below.
|
||||
//
|
||||
// DefinitelyTyped license:
|
||||
// ------
|
||||
// MIT License
|
||||
//
|
||||
// Copyright (c) Microsoft Corporation.
|
||||
//
|
||||
// Permission is hereby granted, free of charge, to any person obtaining a
|
||||
// copy of this software and associated documentation files (the "Software"),
|
||||
// to deal in the Software without restriction, including without limitation
|
||||
// the rights to use, copy, modify, merge, publish, distribute, sublicense,
|
||||
// and/or sell copies of the Software, and to permit persons to whom the
|
||||
// Software is furnished to do so, subject to the following conditions:
|
||||
//
|
||||
// The above copyright notice and this permission notice shall be included
|
||||
// in all copies or substantial portions of the Software.
|
||||
//
|
||||
// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
||||
// EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
|
||||
// MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
|
||||
// IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
|
||||
// CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
|
||||
// TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
|
||||
// SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE
|
||||
// ------
|
||||
//
|
||||
// Changes by Isaac Z. Schlueter released under the terms found in the
|
||||
// LICENSE file within this project.
|
||||
|
||||
/**
|
||||
* Integer greater than 0, representing some number of milliseconds, or the
|
||||
* time at which a TTL started counting from.
|
||||
*/
|
||||
declare type LRUMilliseconds = number
|
||||
|
||||
/**
|
||||
* An integer greater than 0, reflecting the calculated size of items
|
||||
*/
|
||||
declare type LRUSize = number
|
||||
|
||||
/**
|
||||
* An integer greater than 0, reflecting a number of items
|
||||
*/
|
||||
declare type LRUCount = number
|
||||
|
||||
declare class LRUCache<K, V> implements Iterable<[K, V]> {
|
||||
constructor(options: LRUCache.Options<K, V>)
|
||||
|
||||
/**
|
||||
* Number of items in the cache.
|
||||
* Alias for {@link size}
|
||||
*
|
||||
* @deprecated since 7.0 use {@link size} instead
|
||||
*/
|
||||
public readonly length: LRUCount
|
||||
|
||||
public readonly max: LRUCount
|
||||
public readonly maxSize: LRUSize
|
||||
public readonly maxEntrySize: LRUSize
|
||||
public readonly sizeCalculation:
|
||||
| LRUCache.SizeCalculator<K, V>
|
||||
| undefined
|
||||
public readonly dispose: LRUCache.Disposer<K, V>
|
||||
/**
|
||||
* @since 7.4.0
|
||||
*/
|
||||
public readonly disposeAfter: LRUCache.Disposer<K, V> | null
|
||||
public readonly noDisposeOnSet: boolean
|
||||
public readonly ttl: LRUMilliseconds
|
||||
public readonly ttlResolution: LRUMilliseconds
|
||||
public readonly ttlAutopurge: boolean
|
||||
public readonly allowStale: boolean
|
||||
public readonly updateAgeOnGet: boolean
|
||||
/**
|
||||
* @since 7.11.0
|
||||
*/
|
||||
public readonly noDeleteOnStaleGet: boolean
|
||||
/**
|
||||
* @since 7.6.0
|
||||
*/
|
||||
public readonly fetchMethod: LRUCache.Fetcher<K, V> | null
|
||||
|
||||
/**
|
||||
* The total number of items held in the cache at the current moment.
|
||||
*/
|
||||
public readonly size: LRUCount
|
||||
|
||||
/**
|
||||
* The total size of items in cache when using size tracking.
|
||||
*/
|
||||
public readonly calculatedSize: LRUSize
|
||||
|
||||
/**
|
||||
* Add a value to the cache.
|
||||
*/
|
||||
public set(
|
||||
key: K,
|
||||
value: V,
|
||||
options?: LRUCache.SetOptions<K, V>
|
||||
): this
|
||||
|
||||
/**
|
||||
* Return a value from the cache. Will update the recency of the cache entry
|
||||
* found.
|
||||
*
|
||||
* If the key is not found, {@link get} will return `undefined`. This can be
|
||||
* confusing when setting values specifically to `undefined`, as in
|
||||
* `cache.set(key, undefined)`. Use {@link has} to determine whether a key is
|
||||
* present in the cache at all.
|
||||
*/
|
||||
public get(key: K, options?: LRUCache.GetOptions<V>): V | undefined
|
||||
|
||||
/**
|
||||
* Like {@link get} but doesn't update recency or delete stale items.
|
||||
* Returns `undefined` if the item is stale, unless {@link allowStale} is set
|
||||
* either on the cache or in the options object.
|
||||
*/
|
||||
public peek(key: K, options?: LRUCache.PeekOptions): V | undefined
|
||||
|
||||
/**
|
||||
* Check if a key is in the cache, without updating the recency of use.
|
||||
* Will return false if the item is stale, even though it is technically
|
||||
* in the cache.
|
||||
*
|
||||
* Will not update item age unless {@link updateAgeOnHas} is set in the
|
||||
* options or constructor.
|
||||
*/
|
||||
public has(key: K, options?: LRUCache.HasOptions<V>): boolean
|
||||
|
||||
/**
|
||||
* Deletes a key out of the cache.
|
||||
* Returns true if the key was deleted, false otherwise.
|
||||
*/
|
||||
public delete(key: K): boolean
|
||||
|
||||
/**
|
||||
* Clear the cache entirely, throwing away all values.
|
||||
*/
|
||||
public clear(): void
|
||||
|
||||
/**
|
||||
* Delete any stale entries. Returns true if anything was removed, false
|
||||
* otherwise.
|
||||
*/
|
||||
public purgeStale(): boolean
|
||||
|
||||
/**
|
||||
* Find a value for which the supplied fn method returns a truthy value,
|
||||
* similar to Array.find(). fn is called as fn(value, key, cache).
|
||||
*/
|
||||
public find(
|
||||
callbackFn: (
|
||||
value: V,
|
||||
key: K,
|
||||
cache: this
|
||||
) => boolean | undefined | void,
|
||||
options?: LRUCache.GetOptions<V>
|
||||
): V | undefined
|
||||
|
||||
/**
|
||||
* Call the supplied function on each item in the cache, in order from
|
||||
* most recently used to least recently used. fn is called as
|
||||
* fn(value, key, cache). Does not update age or recenty of use.
|
||||
*/
|
||||
public forEach<T = this>(
|
||||
callbackFn: (this: T, value: V, key: K, cache: this) => void,
|
||||
thisArg?: T
|
||||
): void
|
||||
|
||||
/**
|
||||
* The same as {@link forEach} but items are iterated over in reverse
|
||||
* order. (ie, less recently used items are iterated over first.)
|
||||
*/
|
||||
public rforEach<T = this>(
|
||||
callbackFn: (this: T, value: V, key: K, cache: this) => void,
|
||||
thisArg?: T
|
||||
): void
|
||||
|
||||
/**
|
||||
* Return a generator yielding the keys in the cache,
|
||||
* in order from most recently used to least recently used.
|
||||
*/
|
||||
public keys(): Generator<K, void, void>
|
||||
|
||||
/**
|
||||
* Inverse order version of {@link keys}
|
||||
*
|
||||
* Return a generator yielding the keys in the cache,
|
||||
* in order from least recently used to most recently used.
|
||||
*/
|
||||
public rkeys(): Generator<K, void, void>
|
||||
|
||||
/**
|
||||
* Return a generator yielding the values in the cache,
|
||||
* in order from most recently used to least recently used.
|
||||
*/
|
||||
public values(): Generator<V, void, void>
|
||||
|
||||
/**
|
||||
* Inverse order version of {@link values}
|
||||
*
|
||||
* Return a generator yielding the values in the cache,
|
||||
* in order from least recently used to most recently used.
|
||||
*/
|
||||
public rvalues(): Generator<V, void, void>
|
||||
|
||||
/**
|
||||
* Return a generator yielding `[key, value]` pairs,
|
||||
* in order from most recently used to least recently used.
|
||||
*/
|
||||
public entries(): Generator<[K, V], void, void>
|
||||
|
||||
/**
|
||||
* Inverse order version of {@link entries}
|
||||
*
|
||||
* Return a generator yielding `[key, value]` pairs,
|
||||
* in order from least recently used to most recently used.
|
||||
*/
|
||||
public rentries(): Generator<[K, V], void, void>
|
||||
|
||||
/**
|
||||
* Iterating over the cache itself yields the same results as
|
||||
* {@link entries}
|
||||
*/
|
||||
public [Symbol.iterator](): Generator<[K, V], void, void>
|
||||
|
||||
/**
|
||||
* Return an array of [key, entry] objects which can be passed to
|
||||
* cache.load()
|
||||
*/
|
||||
public dump(): Array<[K, LRUCache.Entry<V>]>
|
||||
|
||||
/**
|
||||
* Reset the cache and load in the items in entries in the order listed.
|
||||
* Note that the shape of the resulting cache may be different if the
|
||||
* same options are not used in both caches.
|
||||
*/
|
||||
public load(
|
||||
cacheEntries: ReadonlyArray<[K, LRUCache.Entry<V>]>
|
||||
): void
|
||||
|
||||
/**
|
||||
* Evict the least recently used item, returning its value or `undefined`
|
||||
* if cache is empty.
|
||||
*/
|
||||
public pop(): V | undefined
|
||||
|
||||
/**
|
||||
* Deletes a key out of the cache.
|
||||
*
|
||||
* @deprecated since 7.0 use delete() instead
|
||||
*/
|
||||
public del(key: K): boolean
|
||||
|
||||
/**
|
||||
* Clear the cache entirely, throwing away all values.
|
||||
*
|
||||
* @deprecated since 7.0 use clear() instead
|
||||
*/
|
||||
public reset(): void
|
||||
|
||||
/**
|
||||
* Manually iterates over the entire cache proactively pruning old entries.
|
||||
*
|
||||
* @deprecated since 7.0 use purgeStale() instead
|
||||
*/
|
||||
public prune(): boolean
|
||||
|
||||
/**
|
||||
* Make an asynchronous cached fetch using the {@link fetchMethod} function.
|
||||
*
|
||||
* If multiple fetches for the same key are issued, then they will all be
|
||||
* coalesced into a single call to fetchMethod.
|
||||
*
|
||||
* Note that this means that handling options such as
|
||||
* {@link allowStaleOnFetchAbort}, {@link signal}, and
|
||||
* {@link allowStaleOnFetchRejection} will be determined by the FIRST fetch()
|
||||
* call for a given key.
|
||||
*
|
||||
* This is a known (fixable) shortcoming which will be addresed on when
|
||||
* someone complains about it, as the fix would involve added complexity and
|
||||
* may not be worth the costs for this edge case.
|
||||
*
|
||||
* since: 7.6.0
|
||||
*/
|
||||
public fetch(
|
||||
key: K,
|
||||
options?: LRUCache.FetchOptions<K, V>
|
||||
): Promise<V>
|
||||
|
||||
/**
|
||||
* since: 7.6.0
|
||||
*/
|
||||
public getRemainingTTL(key: K): LRUMilliseconds
|
||||
}
|
||||
|
||||
declare namespace LRUCache {
|
||||
type DisposeReason = 'evict' | 'set' | 'delete'
|
||||
|
||||
type SizeCalculator<K, V> = (value: V, key: K) => LRUSize
|
||||
type Disposer<K, V> = (
|
||||
value: V,
|
||||
key: K,
|
||||
reason: DisposeReason
|
||||
) => void
|
||||
type Fetcher<K, V> = (
|
||||
key: K,
|
||||
staleValue: V | undefined,
|
||||
options: FetcherOptions<K, V>
|
||||
) => Promise<V | void | undefined> | V | void | undefined
|
||||
|
||||
interface DeprecatedOptions<K, V> {
|
||||
/**
|
||||
* alias for ttl
|
||||
*
|
||||
* @deprecated since 7.0 use options.ttl instead
|
||||
*/
|
||||
maxAge?: LRUMilliseconds
|
||||
|
||||
/**
|
||||
* alias for {@link sizeCalculation}
|
||||
*
|
||||
* @deprecated since 7.0 use {@link sizeCalculation} instead
|
||||
*/
|
||||
length?: SizeCalculator<K, V>
|
||||
|
||||
/**
|
||||
* alias for allowStale
|
||||
*
|
||||
* @deprecated since 7.0 use options.allowStale instead
|
||||
*/
|
||||
stale?: boolean
|
||||
}
|
||||
|
||||
interface LimitedByCount {
|
||||
/**
|
||||
* The number of most recently used items to keep.
|
||||
* Note that we may store fewer items than this if maxSize is hit.
|
||||
*/
|
||||
max: LRUCount
|
||||
}
|
||||
|
||||
type MaybeMaxEntrySizeLimit<K, V> =
|
||||
| {
|
||||
/**
|
||||
* The maximum allowed size for any single item in the cache.
|
||||
*
|
||||
* If a larger item is passed to {@link set} or returned by a
|
||||
* {@link fetchMethod}, then it will not be stored in the cache.
|
||||
*/
|
||||
maxEntrySize: LRUSize
|
||||
sizeCalculation?: SizeCalculator<K, V>
|
||||
}
|
||||
| {}
|
||||
|
||||
interface LimitedBySize<K, V> {
|
||||
/**
|
||||
* If you wish to track item size, you must provide a maxSize
|
||||
* note that we still will only keep up to max *actual items*,
|
||||
* if max is set, so size tracking may cause fewer than max items
|
||||
* to be stored. At the extreme, a single item of maxSize size
|
||||
* will cause everything else in the cache to be dropped when it
|
||||
* is added. Use with caution!
|
||||
*
|
||||
* Note also that size tracking can negatively impact performance,
|
||||
* though for most cases, only minimally.
|
||||
*/
|
||||
maxSize: LRUSize
|
||||
|
||||
/**
|
||||
* Function to calculate size of items. Useful if storing strings or
|
||||
* buffers or other items where memory size depends on the object itself.
|
||||
*
|
||||
* Items larger than {@link maxEntrySize} will not be stored in the cache.
|
||||
*
|
||||
* Note that when {@link maxSize} or {@link maxEntrySize} are set, every
|
||||
* item added MUST have a size specified, either via a `sizeCalculation` in
|
||||
* the constructor, or `sizeCalculation` or {@link size} options to
|
||||
* {@link set}.
|
||||
*/
|
||||
sizeCalculation?: SizeCalculator<K, V>
|
||||
}
|
||||
|
||||
interface LimitedByTTL {
|
||||
/**
|
||||
* Max time in milliseconds for items to live in cache before they are
|
||||
* considered stale. Note that stale items are NOT preemptively removed
|
||||
* by default, and MAY live in the cache, contributing to its LRU max,
|
||||
* long after they have expired.
|
||||
*
|
||||
* Also, as this cache is optimized for LRU/MRU operations, some of
|
||||
* the staleness/TTL checks will reduce performance, as they will incur
|
||||
* overhead by deleting items.
|
||||
*
|
||||
* Must be an integer number of ms, defaults to 0, which means "no TTL"
|
||||
*/
|
||||
ttl: LRUMilliseconds
|
||||
|
||||
/**
|
||||
* Boolean flag to tell the cache to not update the TTL when
|
||||
* setting a new value for an existing key (ie, when updating a value
|
||||
* rather than inserting a new value). Note that the TTL value is
|
||||
* _always_ set (if provided) when adding a new entry into the cache.
|
||||
*
|
||||
* @default false
|
||||
* @since 7.4.0
|
||||
*/
|
||||
noUpdateTTL?: boolean
|
||||
|
||||
/**
|
||||
* Minimum amount of time in ms in which to check for staleness.
|
||||
* Defaults to 1, which means that the current time is checked
|
||||
* at most once per millisecond.
|
||||
*
|
||||
* Set to 0 to check the current time every time staleness is tested.
|
||||
* (This reduces performance, and is theoretically unnecessary.)
|
||||
*
|
||||
* Setting this to a higher value will improve performance somewhat
|
||||
* while using ttl tracking, albeit at the expense of keeping stale
|
||||
* items around a bit longer than their TTLs would indicate.
|
||||
*
|
||||
* @default 1
|
||||
* @since 7.1.0
|
||||
*/
|
||||
ttlResolution?: LRUMilliseconds
|
||||
|
||||
/**
|
||||
* Preemptively remove stale items from the cache.
|
||||
* Note that this may significantly degrade performance,
|
||||
* especially if the cache is storing a large number of items.
|
||||
* It is almost always best to just leave the stale items in
|
||||
* the cache, and let them fall out as new items are added.
|
||||
*
|
||||
* Note that this means that {@link allowStale} is a bit pointless,
|
||||
* as stale items will be deleted almost as soon as they expire.
|
||||
*
|
||||
* Use with caution!
|
||||
*
|
||||
* @default false
|
||||
* @since 7.1.0
|
||||
*/
|
||||
ttlAutopurge?: boolean
|
||||
|
||||
/**
|
||||
* Return stale items from {@link get} before disposing of them.
|
||||
* Return stale values from {@link fetch} while performing a call
|
||||
* to the {@link fetchMethod} in the background.
|
||||
*
|
||||
* @default false
|
||||
*/
|
||||
allowStale?: boolean
|
||||
|
||||
/**
|
||||
* Update the age of items on {@link get}, renewing their TTL
|
||||
*
|
||||
* @default false
|
||||
*/
|
||||
updateAgeOnGet?: boolean
|
||||
|
||||
/**
|
||||
* Do not delete stale items when they are retrieved with {@link get}.
|
||||
* Note that the {@link get} return value will still be `undefined` unless
|
||||
* allowStale is true.
|
||||
*
|
||||
* @default false
|
||||
* @since 7.11.0
|
||||
*/
|
||||
noDeleteOnStaleGet?: boolean
|
||||
|
||||
/**
|
||||
* Update the age of items on {@link has}, renewing their TTL
|
||||
*
|
||||
* @default false
|
||||
*/
|
||||
updateAgeOnHas?: boolean
|
||||
}
|
||||
|
||||
type SafetyBounds<K, V> =
|
||||
| LimitedByCount
|
||||
| LimitedBySize<K, V>
|
||||
| LimitedByTTL
|
||||
|
||||
// options shared by all three of the limiting scenarios
|
||||
interface SharedOptions<K, V> {
|
||||
/**
|
||||
* Function that is called on items when they are dropped from the cache.
|
||||
* This can be handy if you want to close file descriptors or do other
|
||||
* cleanup tasks when items are no longer accessible. Called with `key,
|
||||
* value`. It's called before actually removing the item from the
|
||||
* internal cache, so it is *NOT* safe to re-add them.
|
||||
* Use {@link disposeAfter} if you wish to dispose items after they have
|
||||
* been full removed, when it is safe to add them back to the cache.
|
||||
*/
|
||||
dispose?: Disposer<K, V>
|
||||
|
||||
/**
|
||||
* The same as dispose, but called *after* the entry is completely
|
||||
* removed and the cache is once again in a clean state. It is safe to
|
||||
* add an item right back into the cache at this point.
|
||||
* However, note that it is *very* easy to inadvertently create infinite
|
||||
* recursion this way.
|
||||
*
|
||||
* @since 7.3.0
|
||||
*/
|
||||
disposeAfter?: Disposer<K, V>
|
||||
|
||||
/**
|
||||
* Set to true to suppress calling the dispose() function if the entry
|
||||
* key is still accessible within the cache.
|
||||
* This may be overridden by passing an options object to {@link set}.
|
||||
*
|
||||
* @default false
|
||||
*/
|
||||
noDisposeOnSet?: boolean
|
||||
|
||||
/**
|
||||
* Function that is used to make background asynchronous fetches. Called
|
||||
* with `fetchMethod(key, staleValue, { signal, options, context })`.
|
||||
*
|
||||
* If `fetchMethod` is not provided, then {@link fetch} is
|
||||
* equivalent to `Promise.resolve(cache.get(key))`.
|
||||
*
|
||||
* The `fetchMethod` should ONLY return `undefined` in cases where the
|
||||
* abort controller has sent an abort signal.
|
||||
*
|
||||
* @since 7.6.0
|
||||
*/
|
||||
fetchMethod?: LRUCache.Fetcher<K, V>
|
||||
|
||||
/**
|
||||
* Set to true to suppress the deletion of stale data when a
|
||||
* {@link fetchMethod} throws an error or returns a rejected promise
|
||||
*
|
||||
* This may be overridden in the {@link fetchMethod}.
|
||||
*
|
||||
* @default false
|
||||
* @since 7.10.0
|
||||
*/
|
||||
noDeleteOnFetchRejection?: boolean
|
||||
|
||||
/**
|
||||
* Set to true to allow returning stale data when a {@link fetchMethod}
|
||||
* throws an error or returns a rejected promise. Note that this
|
||||
* differs from using {@link allowStale} in that stale data will
|
||||
* ONLY be returned in the case that the fetch fails, not any other
|
||||
* times.
|
||||
*
|
||||
* This may be overridden in the {@link fetchMethod}.
|
||||
*
|
||||
* @default false
|
||||
* @since 7.16.0
|
||||
*/
|
||||
allowStaleOnFetchRejection?: boolean
|
||||
|
||||
/**
|
||||
*
|
||||
* Set to true to ignore the `abort` event emitted by the `AbortSignal`
|
||||
* object passed to {@link fetchMethod}, and still cache the
|
||||
* resulting resolution value, as long as it is not `undefined`.
|
||||
*
|
||||
* When used on its own, this means aborted {@link fetch} calls are not
|
||||
* immediately resolved or rejected when they are aborted, and instead take
|
||||
* the full time to await.
|
||||
*
|
||||
* When used with {@link allowStaleOnFetchAbort}, aborted {@link fetch}
|
||||
* calls will resolve immediately to their stale cached value or
|
||||
* `undefined`, and will continue to process and eventually update the
|
||||
* cache when they resolve, as long as the resulting value is not
|
||||
* `undefined`, thus supporting a "return stale on timeout while
|
||||
* refreshing" mechanism by passing `AbortSignal.timeout(n)` as the signal.
|
||||
*
|
||||
* **Note**: regardless of this setting, an `abort` event _is still emitted
|
||||
* on the `AbortSignal` object_, so may result in invalid results when
|
||||
* passed to other underlying APIs that use AbortSignals.
|
||||
*
|
||||
* This may be overridden in the {@link fetchMethod} or the call to
|
||||
* {@link fetch}.
|
||||
*
|
||||
* @default false
|
||||
* @since 7.17.0
|
||||
*/
|
||||
ignoreFetchAbort?: boolean
|
||||
|
||||
/**
|
||||
* Set to true to return a stale value from the cache when the
|
||||
* `AbortSignal` passed to the {@link fetchMethod} dispatches an `'abort'`
|
||||
* event, whether user-triggered, or due to internal cache behavior.
|
||||
*
|
||||
* Unless {@link ignoreFetchAbort} is also set, the underlying
|
||||
* {@link fetchMethod} will still be considered canceled, and its return
|
||||
* value will be ignored and not cached.
|
||||
*
|
||||
* This may be overridden in the {@link fetchMethod} or the call to
|
||||
* {@link fetch}.
|
||||
*
|
||||
* @default false
|
||||
* @since 7.17.0
|
||||
*/
|
||||
allowStaleOnFetchAbort?: boolean
|
||||
|
||||
/**
|
||||
* Set to any value in the constructor or {@link fetch} options to
|
||||
* pass arbitrary data to the {@link fetchMethod} in the {@link context}
|
||||
* options field.
|
||||
*
|
||||
* @since 7.12.0
|
||||
*/
|
||||
fetchContext?: any
|
||||
}
|
||||
|
||||
type Options<K, V> = SharedOptions<K, V> &
|
||||
DeprecatedOptions<K, V> &
|
||||
SafetyBounds<K, V> &
|
||||
MaybeMaxEntrySizeLimit<K, V>
|
||||
|
||||
/**
|
||||
* options which override the options set in the LRUCache constructor
|
||||
* when making calling {@link set}.
|
||||
*/
|
||||
interface SetOptions<K, V> {
|
||||
/**
|
||||
* A value for the size of the entry, prevents calls to
|
||||
* {@link sizeCalculation}.
|
||||
*
|
||||
* Items larger than {@link maxEntrySize} will not be stored in the cache.
|
||||
*
|
||||
* Note that when {@link maxSize} or {@link maxEntrySize} are set, every
|
||||
* item added MUST have a size specified, either via a `sizeCalculation` in
|
||||
* the constructor, or {@link sizeCalculation} or `size` options to
|
||||
* {@link set}.
|
||||
*/
|
||||
size?: LRUSize
|
||||
/**
|
||||
* Overrides the {@link sizeCalculation} method set in the constructor.
|
||||
*
|
||||
* Items larger than {@link maxEntrySize} will not be stored in the cache.
|
||||
*
|
||||
* Note that when {@link maxSize} or {@link maxEntrySize} are set, every
|
||||
* item added MUST have a size specified, either via a `sizeCalculation` in
|
||||
* the constructor, or `sizeCalculation` or {@link size} options to
|
||||
* {@link set}.
|
||||
*/
|
||||
sizeCalculation?: SizeCalculator<K, V>
|
||||
ttl?: LRUMilliseconds
|
||||
start?: LRUMilliseconds
|
||||
noDisposeOnSet?: boolean
|
||||
noUpdateTTL?: boolean
|
||||
status?: Status<V>
|
||||
}
|
||||
|
||||
/**
|
||||
* options which override the options set in the LRUCAche constructor
|
||||
* when calling {@link has}.
|
||||
*/
|
||||
interface HasOptions<V> {
|
||||
updateAgeOnHas?: boolean
|
||||
status: Status<V>
|
||||
}
|
||||
|
||||
/**
|
||||
* options which override the options set in the LRUCache constructor
|
||||
* when calling {@link get}.
|
||||
*/
|
||||
interface GetOptions<V> {
|
||||
allowStale?: boolean
|
||||
updateAgeOnGet?: boolean
|
||||
noDeleteOnStaleGet?: boolean
|
||||
status?: Status<V>
|
||||
}
|
||||
|
||||
/**
|
||||
* options which override the options set in the LRUCache constructor
|
||||
* when calling {@link peek}.
|
||||
*/
|
||||
interface PeekOptions {
|
||||
allowStale?: boolean
|
||||
}
|
||||
|
||||
/**
|
||||
* Options object passed to the {@link fetchMethod}
|
||||
*
|
||||
* May be mutated by the {@link fetchMethod} to affect the behavior of the
|
||||
* resulting {@link set} operation on resolution, or in the case of
|
||||
* {@link noDeleteOnFetchRejection}, {@link ignoreFetchAbort}, and
|
||||
* {@link allowStaleOnFetchRejection}, the handling of failure.
|
||||
*/
|
||||
interface FetcherFetchOptions<K, V> {
|
||||
allowStale?: boolean
|
||||
updateAgeOnGet?: boolean
|
||||
noDeleteOnStaleGet?: boolean
|
||||
size?: LRUSize
|
||||
sizeCalculation?: SizeCalculator<K, V>
|
||||
ttl?: LRUMilliseconds
|
||||
noDisposeOnSet?: boolean
|
||||
noUpdateTTL?: boolean
|
||||
noDeleteOnFetchRejection?: boolean
|
||||
allowStaleOnFetchRejection?: boolean
|
||||
ignoreFetchAbort?: boolean
|
||||
allowStaleOnFetchAbort?: boolean
|
||||
status?: Status<V>
|
||||
}
|
||||
|
||||
/**
|
||||
* Status object that may be passed to {@link fetch}, {@link get},
|
||||
* {@link set}, and {@link has}.
|
||||
*/
|
||||
interface Status<V> {
|
||||
/**
|
||||
* The status of a set() operation.
|
||||
*
|
||||
* - add: the item was not found in the cache, and was added
|
||||
* - update: the item was in the cache, with the same value provided
|
||||
* - replace: the item was in the cache, and replaced
|
||||
* - miss: the item was not added to the cache for some reason
|
||||
*/
|
||||
set?: 'add' | 'update' | 'replace' | 'miss'
|
||||
|
||||
/**
|
||||
* the ttl stored for the item, or undefined if ttls are not used.
|
||||
*/
|
||||
ttl?: LRUMilliseconds
|
||||
|
||||
/**
|
||||
* the start time for the item, or undefined if ttls are not used.
|
||||
*/
|
||||
start?: LRUMilliseconds
|
||||
|
||||
/**
|
||||
* The timestamp used for TTL calculation
|
||||
*/
|
||||
now?: LRUMilliseconds
|
||||
|
||||
/**
|
||||
* the remaining ttl for the item, or undefined if ttls are not used.
|
||||
*/
|
||||
remainingTTL?: LRUMilliseconds
|
||||
|
||||
/**
|
||||
* The calculated size for the item, if sizes are used.
|
||||
*/
|
||||
size?: LRUSize
|
||||
|
||||
/**
|
||||
* A flag indicating that the item was not stored, due to exceeding the
|
||||
* {@link maxEntrySize}
|
||||
*/
|
||||
maxEntrySizeExceeded?: true
|
||||
|
||||
/**
|
||||
* The old value, specified in the case of `set:'update'` or
|
||||
* `set:'replace'`
|
||||
*/
|
||||
oldValue?: V
|
||||
|
||||
/**
|
||||
* The results of a {@link has} operation
|
||||
*
|
||||
* - hit: the item was found in the cache
|
||||
* - stale: the item was found in the cache, but is stale
|
||||
* - miss: the item was not found in the cache
|
||||
*/
|
||||
has?: 'hit' | 'stale' | 'miss'
|
||||
|
||||
/**
|
||||
* The status of a {@link fetch} operation.
|
||||
* Note that this can change as the underlying fetch() moves through
|
||||
* various states.
|
||||
*
|
||||
* - inflight: there is another fetch() for this key which is in process
|
||||
* - get: there is no fetchMethod, so {@link get} was called.
|
||||
* - miss: the item is not in cache, and will be fetched.
|
||||
* - hit: the item is in the cache, and was resolved immediately.
|
||||
* - stale: the item is in the cache, but stale.
|
||||
* - refresh: the item is in the cache, and not stale, but
|
||||
* {@link forceRefresh} was specified.
|
||||
*/
|
||||
fetch?: 'get' | 'inflight' | 'miss' | 'hit' | 'stale' | 'refresh'
|
||||
|
||||
/**
|
||||
* The {@link fetchMethod} was called
|
||||
*/
|
||||
fetchDispatched?: true
|
||||
|
||||
/**
|
||||
* The cached value was updated after a successful call to fetchMethod
|
||||
*/
|
||||
fetchUpdated?: true
|
||||
|
||||
/**
|
||||
* The reason for a fetch() rejection. Either the error raised by the
|
||||
* {@link fetchMethod}, or the reason for an AbortSignal.
|
||||
*/
|
||||
fetchError?: Error
|
||||
|
||||
/**
|
||||
* The fetch received an abort signal
|
||||
*/
|
||||
fetchAborted?: true
|
||||
|
||||
/**
|
||||
* The abort signal received was ignored, and the fetch was allowed to
|
||||
* continue.
|
||||
*/
|
||||
fetchAbortIgnored?: true
|
||||
|
||||
/**
|
||||
* The fetchMethod promise resolved successfully
|
||||
*/
|
||||
fetchResolved?: true
|
||||
|
||||
/**
|
||||
* The fetchMethod promise was rejected
|
||||
*/
|
||||
fetchRejected?: true
|
||||
|
||||
/**
|
||||
* The status of a {@link get} operation.
|
||||
*
|
||||
* - fetching: The item is currently being fetched. If a previous value is
|
||||
* present and allowed, that will be returned.
|
||||
* - stale: The item is in the cache, and is stale.
|
||||
* - hit: the item is in the cache
|
||||
* - miss: the item is not in the cache
|
||||
*/
|
||||
get?: 'stale' | 'hit' | 'miss'
|
||||
|
||||
/**
|
||||
* A fetch or get operation returned a stale value.
|
||||
*/
|
||||
returnedStale?: true
|
||||
}
|
||||
|
||||
/**
|
||||
* options which override the options set in the LRUCache constructor
|
||||
* when calling {@link fetch}.
|
||||
*
|
||||
* This is the union of GetOptions and SetOptions, plus
|
||||
* {@link noDeleteOnFetchRejection}, {@link allowStaleOnFetchRejection},
|
||||
* {@link forceRefresh}, and {@link fetchContext}
|
||||
*/
|
||||
interface FetchOptions<K, V> extends FetcherFetchOptions<K, V> {
|
||||
forceRefresh?: boolean
|
||||
fetchContext?: any
|
||||
signal?: AbortSignal
|
||||
status?: Status<V>
|
||||
}
|
||||
|
||||
interface FetcherOptions<K, V> {
|
||||
signal: AbortSignal
|
||||
options: FetcherFetchOptions<K, V>
|
||||
/**
|
||||
* Object provided in the {@link fetchContext} option
|
||||
*/
|
||||
context: any
|
||||
}
|
||||
|
||||
interface Entry<V> {
|
||||
value: V
|
||||
ttl?: LRUMilliseconds
|
||||
size?: LRUSize
|
||||
start?: LRUMilliseconds
|
||||
}
|
||||
}
|
||||
|
||||
export = LRUCache
|
||||
1227
electron/node_modules/cacache/node_modules/lru-cache/index.js
generated
vendored
Normal file
1227
electron/node_modules/cacache/node_modules/lru-cache/index.js
generated
vendored
Normal file
File diff suppressed because it is too large
Load diff
1227
electron/node_modules/cacache/node_modules/lru-cache/index.mjs
generated
vendored
Normal file
1227
electron/node_modules/cacache/node_modules/lru-cache/index.mjs
generated
vendored
Normal file
File diff suppressed because it is too large
Load diff
96
electron/node_modules/cacache/node_modules/lru-cache/package.json
generated
vendored
Normal file
96
electron/node_modules/cacache/node_modules/lru-cache/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,96 @@
|
|||
{
|
||||
"name": "lru-cache",
|
||||
"description": "A cache object that deletes the least-recently-used items.",
|
||||
"version": "7.18.3",
|
||||
"author": "Isaac Z. Schlueter <i@izs.me>",
|
||||
"keywords": [
|
||||
"mru",
|
||||
"lru",
|
||||
"cache"
|
||||
],
|
||||
"sideEffects": false,
|
||||
"scripts": {
|
||||
"build": "npm run prepare",
|
||||
"pretest": "npm run prepare",
|
||||
"presnap": "npm run prepare",
|
||||
"prepare": "node ./scripts/transpile-to-esm.js",
|
||||
"size": "size-limit",
|
||||
"test": "tap",
|
||||
"snap": "tap",
|
||||
"preversion": "npm test",
|
||||
"postversion": "npm publish",
|
||||
"prepublishOnly": "git push origin --follow-tags",
|
||||
"format": "prettier --write .",
|
||||
"typedoc": "typedoc ./index.d.ts"
|
||||
},
|
||||
"type": "commonjs",
|
||||
"main": "./index.js",
|
||||
"module": "./index.mjs",
|
||||
"types": "./index.d.ts",
|
||||
"exports": {
|
||||
".": {
|
||||
"import": {
|
||||
"types": "./index.d.ts",
|
||||
"default": "./index.mjs"
|
||||
},
|
||||
"require": {
|
||||
"types": "./index.d.ts",
|
||||
"default": "./index.js"
|
||||
}
|
||||
},
|
||||
"./package.json": "./package.json"
|
||||
},
|
||||
"repository": "git://github.com/isaacs/node-lru-cache.git",
|
||||
"devDependencies": {
|
||||
"@size-limit/preset-small-lib": "^7.0.8",
|
||||
"@types/node": "^17.0.31",
|
||||
"@types/tap": "^15.0.6",
|
||||
"benchmark": "^2.1.4",
|
||||
"c8": "^7.11.2",
|
||||
"clock-mock": "^1.0.6",
|
||||
"eslint-config-prettier": "^8.5.0",
|
||||
"prettier": "^2.6.2",
|
||||
"size-limit": "^7.0.8",
|
||||
"tap": "^16.3.4",
|
||||
"ts-node": "^10.7.0",
|
||||
"tslib": "^2.4.0",
|
||||
"typedoc": "^0.23.24",
|
||||
"typescript": "^4.6.4"
|
||||
},
|
||||
"license": "ISC",
|
||||
"files": [
|
||||
"index.js",
|
||||
"index.mjs",
|
||||
"index.d.ts"
|
||||
],
|
||||
"engines": {
|
||||
"node": ">=12"
|
||||
},
|
||||
"prettier": {
|
||||
"semi": false,
|
||||
"printWidth": 70,
|
||||
"tabWidth": 2,
|
||||
"useTabs": false,
|
||||
"singleQuote": true,
|
||||
"jsxSingleQuote": false,
|
||||
"bracketSameLine": true,
|
||||
"arrowParens": "avoid",
|
||||
"endOfLine": "lf"
|
||||
},
|
||||
"tap": {
|
||||
"nyc-arg": [
|
||||
"--include=index.js"
|
||||
],
|
||||
"node-arg": [
|
||||
"--expose-gc",
|
||||
"--require",
|
||||
"ts-node/register"
|
||||
],
|
||||
"ts": false
|
||||
},
|
||||
"size-limit": [
|
||||
{
|
||||
"path": "./index.js"
|
||||
}
|
||||
]
|
||||
}
|
||||
15
electron/node_modules/cacache/node_modules/minimatch/LICENSE
generated
vendored
Normal file
15
electron/node_modules/cacache/node_modules/minimatch/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
The ISC License
|
||||
|
||||
Copyright (c) 2011-2023 Isaac Z. Schlueter and Contributors
|
||||
|
||||
Permission to use, copy, modify, and/or distribute this software for any
|
||||
purpose with or without fee is hereby granted, provided that the above
|
||||
copyright notice and this permission notice appear in all copies.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
||||
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
||||
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
||||
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
||||
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR
|
||||
IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
296
electron/node_modules/cacache/node_modules/minimatch/README.md
generated
vendored
Normal file
296
electron/node_modules/cacache/node_modules/minimatch/README.md
generated
vendored
Normal file
|
|
@ -0,0 +1,296 @@
|
|||
# minimatch
|
||||
|
||||
A minimal matching utility.
|
||||
|
||||
[](http://travis-ci.org/isaacs/minimatch)
|
||||
|
||||
|
||||
This is the matching library used internally by npm.
|
||||
|
||||
It works by converting glob expressions into JavaScript `RegExp`
|
||||
objects.
|
||||
|
||||
## Important Security Consideration!
|
||||
|
||||
> [!WARNING]
|
||||
> This library uses JavaScript regular expressions. Please read
|
||||
> the following warning carefully, and be thoughtful about what
|
||||
> you provide to this library in production systems.
|
||||
|
||||
_Any_ library in JavaScript that deals with matching string
|
||||
patterns using regular expressions will be subject to
|
||||
[ReDoS](https://owasp.org/www-community/attacks/Regular_expression_Denial_of_Service_-_ReDoS)
|
||||
if the pattern is generated using untrusted input.
|
||||
|
||||
Efforts have been made to mitigate risk as much as is feasible in
|
||||
such a library, providing maximum recursion depths and so forth,
|
||||
but these measures can only ultimately protect against accidents,
|
||||
not malice. A dedicated attacker can _always_ find patterns that
|
||||
cannot be defended against by a bash-compatible glob pattern
|
||||
matching system that uses JavaScript regular expressions.
|
||||
|
||||
To be extremely clear:
|
||||
|
||||
> [!WARNING]
|
||||
> **If you create a system where you take user input, and use
|
||||
> that input as the source of a Regular Expression pattern, in
|
||||
> this or any extant glob matcher in JavaScript, you will be
|
||||
> pwned.**
|
||||
|
||||
A future version of this library _may_ use a different matching
|
||||
algorithm which does not exhibit backtracking problems. If and
|
||||
when that happens, it will likely be a sweeping change, and those
|
||||
improvements will **not** be backported to legacy versions.
|
||||
|
||||
In the near term, it is not reasonable to continue to play
|
||||
whack-a-mole with security advisories, and so any future ReDoS
|
||||
reports will be considered "working as intended", and resolved
|
||||
entirely by this warning.
|
||||
|
||||
## Usage
|
||||
|
||||
```javascript
|
||||
var minimatch = require("minimatch")
|
||||
|
||||
minimatch("bar.foo", "*.foo") // true!
|
||||
minimatch("bar.foo", "*.bar") // false!
|
||||
minimatch("bar.foo", "*.+(bar|foo)", { debug: true }) // true, and noisy!
|
||||
```
|
||||
|
||||
## Features
|
||||
|
||||
Supports these glob features:
|
||||
|
||||
* Brace Expansion
|
||||
* Extended glob matching
|
||||
* "Globstar" `**` matching
|
||||
|
||||
See:
|
||||
|
||||
* `man sh`
|
||||
* `man bash`
|
||||
* `man 3 fnmatch`
|
||||
* `man 5 gitignore`
|
||||
|
||||
## Windows
|
||||
|
||||
**Please only use forward-slashes in glob expressions.**
|
||||
|
||||
Though windows uses either `/` or `\` as its path separator, only `/`
|
||||
characters are used by this glob implementation. You must use
|
||||
forward-slashes **only** in glob expressions. Back-slashes in patterns
|
||||
will always be interpreted as escape characters, not path separators.
|
||||
|
||||
Note that `\` or `/` _will_ be interpreted as path separators in paths on
|
||||
Windows, and will match against `/` in glob expressions.
|
||||
|
||||
So just always use `/` in patterns.
|
||||
|
||||
## Minimatch Class
|
||||
|
||||
Create a minimatch object by instantiating the `minimatch.Minimatch` class.
|
||||
|
||||
```javascript
|
||||
var Minimatch = require("minimatch").Minimatch
|
||||
var mm = new Minimatch(pattern, options)
|
||||
```
|
||||
|
||||
### Properties
|
||||
|
||||
* `pattern` The original pattern the minimatch object represents.
|
||||
* `options` The options supplied to the constructor.
|
||||
* `set` A 2-dimensional array of regexp or string expressions.
|
||||
Each row in the
|
||||
array corresponds to a brace-expanded pattern. Each item in the row
|
||||
corresponds to a single path-part. For example, the pattern
|
||||
`{a,b/c}/d` would expand to a set of patterns like:
|
||||
|
||||
[ [ a, d ]
|
||||
, [ b, c, d ] ]
|
||||
|
||||
If a portion of the pattern doesn't have any "magic" in it
|
||||
(that is, it's something like `"foo"` rather than `fo*o?`), then it
|
||||
will be left as a string rather than converted to a regular
|
||||
expression.
|
||||
|
||||
* `regexp` Created by the `makeRe` method. A single regular expression
|
||||
expressing the entire pattern. This is useful in cases where you wish
|
||||
to use the pattern somewhat like `fnmatch(3)` with `FNM_PATH` enabled.
|
||||
* `negate` True if the pattern is negated.
|
||||
* `comment` True if the pattern is a comment.
|
||||
* `empty` True if the pattern is `""`.
|
||||
|
||||
### Methods
|
||||
|
||||
* `makeRe` Generate the `regexp` member if necessary, and return it.
|
||||
Will return `false` if the pattern is invalid.
|
||||
* `match(fname)` Return true if the filename matches the pattern, or
|
||||
false otherwise.
|
||||
* `matchOne(fileArray, patternArray, partial)` Take a `/`-split
|
||||
filename, and match it against a single row in the `regExpSet`. This
|
||||
method is mainly for internal use, but is exposed so that it can be
|
||||
used by a glob-walker that needs to avoid excessive filesystem calls.
|
||||
|
||||
All other methods are internal, and will be called as necessary.
|
||||
|
||||
### minimatch(path, pattern, options)
|
||||
|
||||
Main export. Tests a path against the pattern using the options.
|
||||
|
||||
```javascript
|
||||
var isJS = minimatch(file, "*.js", { matchBase: true })
|
||||
```
|
||||
|
||||
### minimatch.filter(pattern, options)
|
||||
|
||||
Returns a function that tests its
|
||||
supplied argument, suitable for use with `Array.filter`. Example:
|
||||
|
||||
```javascript
|
||||
var javascripts = fileList.filter(minimatch.filter("*.js", {matchBase: true}))
|
||||
```
|
||||
|
||||
### minimatch.match(list, pattern, options)
|
||||
|
||||
Match against the list of
|
||||
files, in the style of fnmatch or glob. If nothing is matched, and
|
||||
options.nonull is set, then return a list containing the pattern itself.
|
||||
|
||||
```javascript
|
||||
var javascripts = minimatch.match(fileList, "*.js", {matchBase: true})
|
||||
```
|
||||
|
||||
### minimatch.makeRe(pattern, options)
|
||||
|
||||
Make a regular expression object from the pattern.
|
||||
|
||||
## Options
|
||||
|
||||
All options are `false` by default.
|
||||
|
||||
### debug
|
||||
|
||||
Dump a ton of stuff to stderr.
|
||||
|
||||
### nobrace
|
||||
|
||||
Do not expand `{a,b}` and `{1..3}` brace sets.
|
||||
|
||||
### noglobstar
|
||||
|
||||
Disable `**` matching against multiple folder names.
|
||||
|
||||
### dot
|
||||
|
||||
Allow patterns to match filenames starting with a period, even if
|
||||
the pattern does not explicitly have a period in that spot.
|
||||
|
||||
Note that by default, `a/**/b` will **not** match `a/.d/b`, unless `dot`
|
||||
is set.
|
||||
|
||||
### noext
|
||||
|
||||
Disable "extglob" style patterns like `+(a|b)`.
|
||||
|
||||
### nocase
|
||||
|
||||
Perform a case-insensitive match.
|
||||
|
||||
### nonull
|
||||
|
||||
When a match is not found by `minimatch.match`, return a list containing
|
||||
the pattern itself if this option is set. When not set, an empty list
|
||||
is returned if there are no matches.
|
||||
|
||||
### matchBase
|
||||
|
||||
If set, then patterns without slashes will be matched
|
||||
against the basename of the path if it contains slashes. For example,
|
||||
`a?b` would match the path `/xyz/123/acb`, but not `/xyz/acb/123`.
|
||||
|
||||
### nocomment
|
||||
|
||||
Suppress the behavior of treating `#` at the start of a pattern as a
|
||||
comment.
|
||||
|
||||
### nonegate
|
||||
|
||||
Suppress the behavior of treating a leading `!` character as negation.
|
||||
|
||||
### flipNegate
|
||||
|
||||
Returns from negate expressions the same as if they were not negated.
|
||||
(Ie, true on a hit, false on a miss.)
|
||||
|
||||
### partial
|
||||
|
||||
Compare a partial path to a pattern. As long as the parts of the path that
|
||||
are present are not contradicted by the pattern, it will be treated as a
|
||||
match. This is useful in applications where you're walking through a
|
||||
folder structure, and don't yet have the full path, but want to ensure that
|
||||
you do not walk down paths that can never be a match.
|
||||
|
||||
For example,
|
||||
|
||||
```js
|
||||
minimatch('/a/b', '/a/*/c/d', { partial: true }) // true, might be /a/b/c/d
|
||||
minimatch('/a/b', '/**/d', { partial: true }) // true, might be /a/b/.../d
|
||||
minimatch('/x/y/z', '/a/**/z', { partial: true }) // false, because x !== a
|
||||
```
|
||||
|
||||
### windowsPathsNoEscape
|
||||
|
||||
Use `\\` as a path separator _only_, and _never_ as an escape
|
||||
character. If set, all `\\` characters are replaced with `/` in
|
||||
the pattern. Note that this makes it **impossible** to match
|
||||
against paths containing literal glob pattern characters, but
|
||||
allows matching with patterns constructed using `path.join()` and
|
||||
`path.resolve()` on Windows platforms, mimicking the (buggy!)
|
||||
behavior of earlier versions on Windows. Please use with
|
||||
caution, and be mindful of [the caveat about Windows
|
||||
paths](#windows).
|
||||
|
||||
For legacy reasons, this is also set if
|
||||
`options.allowWindowsEscape` is set to the exact value `false`.
|
||||
|
||||
## Comparisons to other fnmatch/glob implementations
|
||||
|
||||
While strict compliance with the existing standards is a worthwhile
|
||||
goal, some discrepancies exist between minimatch and other
|
||||
implementations, and are intentional.
|
||||
|
||||
If the pattern starts with a `!` character, then it is negated. Set the
|
||||
`nonegate` flag to suppress this behavior, and treat leading `!`
|
||||
characters normally. This is perhaps relevant if you wish to start the
|
||||
pattern with a negative extglob pattern like `!(a|B)`. Multiple `!`
|
||||
characters at the start of a pattern will negate the pattern multiple
|
||||
times.
|
||||
|
||||
If a pattern starts with `#`, then it is treated as a comment, and
|
||||
will not match anything. Use `\#` to match a literal `#` at the
|
||||
start of a line, or set the `nocomment` flag to suppress this behavior.
|
||||
|
||||
The double-star character `**` is supported by default, unless the
|
||||
`noglobstar` flag is set. This is supported in the manner of bsdglob
|
||||
and bash 4.1, where `**` only has special significance if it is the only
|
||||
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
|
||||
`a/**b` will not.
|
||||
|
||||
If an escaped pattern has no matches, and the `nonull` flag is set,
|
||||
then minimatch.match returns the pattern as-provided, rather than
|
||||
interpreting the character escapes. For example,
|
||||
`minimatch.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
|
||||
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
|
||||
that it does not resolve escaped pattern characters.
|
||||
|
||||
If brace expansion is not disabled, then it is performed before any
|
||||
other interpretation of the glob pattern. Thus, a pattern like
|
||||
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
|
||||
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
|
||||
checked for validity. Since those two are valid, matching proceeds.
|
||||
|
||||
Note that `fnmatch(3)` in libc is an extremely naive string comparison
|
||||
matcher, which does not do anything special for slashes. This library is
|
||||
designed to be used in glob searching and file walkers, and so it does do
|
||||
special things with `/`. Thus, `foo*` will not match `foo/bar` in this
|
||||
library, even though it would in `fnmatch(3)`.
|
||||
35
electron/node_modules/cacache/node_modules/minimatch/changelog.md
generated
vendored
Normal file
35
electron/node_modules/cacache/node_modules/minimatch/changelog.md
generated
vendored
Normal file
|
|
@ -0,0 +1,35 @@
|
|||
# change log
|
||||
|
||||
## 5.1
|
||||
|
||||
- use windowsPathNoEscape/allowWindowsEscape opts
|
||||
- make character classes more faithful to bash glob behavior
|
||||
- fix handling of escapes
|
||||
- treat invalid character classes as non-matching pattern
|
||||
rather than escaped literals
|
||||
|
||||
## 5.0
|
||||
|
||||
- brace-expansion: ignore only blocks that begins with $
|
||||
- Expect exclusively forward slash as path sep, same as node-glob
|
||||
|
||||
## 4.2
|
||||
|
||||
- makeRe: globstar should match zero+ path portions
|
||||
- Fix bug with escaped '@' in patterns
|
||||
|
||||
## 4.1
|
||||
|
||||
- treat `nocase:true` as always having magic
|
||||
- expose GLOBSTAR marker
|
||||
|
||||
## 4.0
|
||||
|
||||
- Update to modern JS syntax
|
||||
- Add `allowWindowsEscape` option
|
||||
|
||||
## 3.x
|
||||
|
||||
- Added basic redos protection
|
||||
- Handle unfinished `!(` extglob patterns
|
||||
- Add `partial: true` option
|
||||
4
electron/node_modules/cacache/node_modules/minimatch/lib/path.js
generated
vendored
Normal file
4
electron/node_modules/cacache/node_modules/minimatch/lib/path.js
generated
vendored
Normal file
|
|
@ -0,0 +1,4 @@
|
|||
const isWindows = typeof process === 'object' &&
|
||||
process &&
|
||||
process.platform === 'win32'
|
||||
module.exports = isWindows ? { sep: '\\' } : { sep: '/' }
|
||||
996
electron/node_modules/cacache/node_modules/minimatch/minimatch.js
generated
vendored
Normal file
996
electron/node_modules/cacache/node_modules/minimatch/minimatch.js
generated
vendored
Normal file
|
|
@ -0,0 +1,996 @@
|
|||
const minimatch = module.exports = (p, pattern, options = {}) => {
|
||||
assertValidPattern(pattern)
|
||||
|
||||
// shortcut: comments match nothing.
|
||||
if (!options.nocomment && pattern.charAt(0) === '#') {
|
||||
return false
|
||||
}
|
||||
|
||||
return new Minimatch(pattern, options).match(p)
|
||||
}
|
||||
|
||||
module.exports = minimatch
|
||||
|
||||
const path = require('./lib/path.js')
|
||||
minimatch.sep = path.sep
|
||||
|
||||
const GLOBSTAR = Symbol('globstar **')
|
||||
minimatch.GLOBSTAR = GLOBSTAR
|
||||
const expand = require('brace-expansion')
|
||||
|
||||
const plTypes = {
|
||||
'!': { open: '(?:(?!(?:', close: '))[^/]*?)'},
|
||||
'?': { open: '(?:', close: ')?' },
|
||||
'+': { open: '(?:', close: ')+' },
|
||||
'*': { open: '(?:', close: ')*' },
|
||||
'@': { open: '(?:', close: ')' }
|
||||
}
|
||||
|
||||
// any single thing other than /
|
||||
// don't need to escape / when using new RegExp()
|
||||
const qmark = '[^/]'
|
||||
|
||||
// * => any number of characters
|
||||
const star = qmark + '*?'
|
||||
|
||||
// ** when dots are allowed. Anything goes, except .. and .
|
||||
// not (^ or / followed by one or two dots followed by $ or /),
|
||||
// followed by anything, any number of times.
|
||||
const twoStarDot = '(?:(?!(?:\\\/|^)(?:\\.{1,2})($|\\\/)).)*?'
|
||||
|
||||
// not a ^ or / followed by a dot,
|
||||
// followed by anything, any number of times.
|
||||
const twoStarNoDot = '(?:(?!(?:\\\/|^)\\.).)*?'
|
||||
|
||||
// "abc" -> { a:true, b:true, c:true }
|
||||
const charSet = s => s.split('').reduce((set, c) => {
|
||||
set[c] = true
|
||||
return set
|
||||
}, {})
|
||||
|
||||
// characters that need to be escaped in RegExp.
|
||||
const reSpecials = charSet('().*{}+?[]^$\\!')
|
||||
|
||||
// characters that indicate we have to add the pattern start
|
||||
const addPatternStartSet = charSet('[.(')
|
||||
|
||||
// normalizes slashes.
|
||||
const slashSplit = /\/+/
|
||||
|
||||
minimatch.filter = (pattern, options = {}) =>
|
||||
(p, i, list) => minimatch(p, pattern, options)
|
||||
|
||||
const ext = (a, b = {}) => {
|
||||
const t = {}
|
||||
Object.keys(a).forEach(k => t[k] = a[k])
|
||||
Object.keys(b).forEach(k => t[k] = b[k])
|
||||
return t
|
||||
}
|
||||
|
||||
minimatch.defaults = def => {
|
||||
if (!def || typeof def !== 'object' || !Object.keys(def).length) {
|
||||
return minimatch
|
||||
}
|
||||
|
||||
const orig = minimatch
|
||||
|
||||
const m = (p, pattern, options) => orig(p, pattern, ext(def, options))
|
||||
m.Minimatch = class Minimatch extends orig.Minimatch {
|
||||
constructor (pattern, options) {
|
||||
super(pattern, ext(def, options))
|
||||
}
|
||||
}
|
||||
m.Minimatch.defaults = options => orig.defaults(ext(def, options)).Minimatch
|
||||
m.filter = (pattern, options) => orig.filter(pattern, ext(def, options))
|
||||
m.defaults = options => orig.defaults(ext(def, options))
|
||||
m.makeRe = (pattern, options) => orig.makeRe(pattern, ext(def, options))
|
||||
m.braceExpand = (pattern, options) => orig.braceExpand(pattern, ext(def, options))
|
||||
m.match = (list, pattern, options) => orig.match(list, pattern, ext(def, options))
|
||||
|
||||
return m
|
||||
}
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
// Brace expansion:
|
||||
// a{b,c}d -> abd acd
|
||||
// a{b,}c -> abc ac
|
||||
// a{0..3}d -> a0d a1d a2d a3d
|
||||
// a{b,c{d,e}f}g -> abg acdfg acefg
|
||||
// a{b,c}d{e,f}g -> abdeg acdeg abdeg abdfg
|
||||
//
|
||||
// Invalid sets are not expanded.
|
||||
// a{2..}b -> a{2..}b
|
||||
// a{b}c -> a{b}c
|
||||
minimatch.braceExpand = (pattern, options) => braceExpand(pattern, options)
|
||||
|
||||
const braceExpand = (pattern, options = {}) => {
|
||||
assertValidPattern(pattern)
|
||||
|
||||
// Thanks to Yeting Li <https://github.com/yetingli> for
|
||||
// improving this regexp to avoid a ReDOS vulnerability.
|
||||
if (options.nobrace || !/\{(?:(?!\{).)*\}/.test(pattern)) {
|
||||
// shortcut. no need to expand.
|
||||
return [pattern]
|
||||
}
|
||||
|
||||
return expand(pattern)
|
||||
}
|
||||
|
||||
const MAX_PATTERN_LENGTH = 1024 * 64
|
||||
const assertValidPattern = pattern => {
|
||||
if (typeof pattern !== 'string') {
|
||||
throw new TypeError('invalid pattern')
|
||||
}
|
||||
|
||||
if (pattern.length > MAX_PATTERN_LENGTH) {
|
||||
throw new TypeError('pattern is too long')
|
||||
}
|
||||
}
|
||||
|
||||
// parse a component of the expanded set.
|
||||
// At this point, no pattern may contain "/" in it
|
||||
// so we're going to return a 2d array, where each entry is the full
|
||||
// pattern, split on '/', and then turned into a regular expression.
|
||||
// A regexp is made at the end which joins each array with an
|
||||
// escaped /, and another full one which joins each regexp with |.
|
||||
//
|
||||
// Following the lead of Bash 4.1, note that "**" only has special meaning
|
||||
// when it is the *only* thing in a path portion. Otherwise, any series
|
||||
// of * is equivalent to a single *. Globstar behavior is enabled by
|
||||
// default, and can be disabled by setting options.noglobstar.
|
||||
const SUBPARSE = Symbol('subparse')
|
||||
|
||||
minimatch.makeRe = (pattern, options) =>
|
||||
new Minimatch(pattern, options || {}).makeRe()
|
||||
|
||||
minimatch.match = (list, pattern, options = {}) => {
|
||||
const mm = new Minimatch(pattern, options)
|
||||
list = list.filter(f => mm.match(f))
|
||||
if (mm.options.nonull && !list.length) {
|
||||
list.push(pattern)
|
||||
}
|
||||
return list
|
||||
}
|
||||
|
||||
// replace stuff like \* with *
|
||||
const globUnescape = s => s.replace(/\\(.)/g, '$1')
|
||||
const charUnescape = s => s.replace(/\\([^-\]])/g, '$1')
|
||||
const regExpEscape = s => s.replace(/[-[\]{}()*+?.,\\^$|#\s]/g, '\\$&')
|
||||
const braExpEscape = s => s.replace(/[[\]\\]/g, '\\$&')
|
||||
|
||||
class Minimatch {
|
||||
constructor (pattern, options) {
|
||||
assertValidPattern(pattern)
|
||||
|
||||
if (!options) options = {}
|
||||
|
||||
this.options = options
|
||||
this.maxGlobstarRecursion = options.maxGlobstarRecursion !== undefined
|
||||
? options.maxGlobstarRecursion : 200
|
||||
this.set = []
|
||||
this.pattern = pattern
|
||||
this.windowsPathsNoEscape = !!options.windowsPathsNoEscape ||
|
||||
options.allowWindowsEscape === false
|
||||
if (this.windowsPathsNoEscape) {
|
||||
this.pattern = this.pattern.replace(/\\/g, '/')
|
||||
}
|
||||
this.regexp = null
|
||||
this.negate = false
|
||||
this.comment = false
|
||||
this.empty = false
|
||||
this.partial = !!options.partial
|
||||
|
||||
// make the set of regexps etc.
|
||||
this.make()
|
||||
}
|
||||
|
||||
debug () {}
|
||||
|
||||
make () {
|
||||
const pattern = this.pattern
|
||||
const options = this.options
|
||||
|
||||
// empty patterns and comments match nothing.
|
||||
if (!options.nocomment && pattern.charAt(0) === '#') {
|
||||
this.comment = true
|
||||
return
|
||||
}
|
||||
if (!pattern) {
|
||||
this.empty = true
|
||||
return
|
||||
}
|
||||
|
||||
// step 1: figure out negation, etc.
|
||||
this.parseNegate()
|
||||
|
||||
// step 2: expand braces
|
||||
let set = this.globSet = this.braceExpand()
|
||||
|
||||
if (options.debug) this.debug = (...args) => console.error(...args)
|
||||
|
||||
this.debug(this.pattern, set)
|
||||
|
||||
// step 3: now we have a set, so turn each one into a series of path-portion
|
||||
// matching patterns.
|
||||
// These will be regexps, except in the case of "**", which is
|
||||
// set to the GLOBSTAR object for globstar behavior,
|
||||
// and will not contain any / characters
|
||||
set = this.globParts = set.map(s => s.split(slashSplit))
|
||||
|
||||
this.debug(this.pattern, set)
|
||||
|
||||
// glob --> regexps
|
||||
set = set.map((s, si, set) => s.map(this.parse, this))
|
||||
|
||||
this.debug(this.pattern, set)
|
||||
|
||||
// filter out everything that didn't compile properly.
|
||||
set = set.filter(s => s.indexOf(false) === -1)
|
||||
|
||||
this.debug(this.pattern, set)
|
||||
|
||||
this.set = set
|
||||
}
|
||||
|
||||
parseNegate () {
|
||||
if (this.options.nonegate) return
|
||||
|
||||
const pattern = this.pattern
|
||||
let negate = false
|
||||
let negateOffset = 0
|
||||
|
||||
for (let i = 0; i < pattern.length && pattern.charAt(i) === '!'; i++) {
|
||||
negate = !negate
|
||||
negateOffset++
|
||||
}
|
||||
|
||||
if (negateOffset) this.pattern = pattern.slice(negateOffset)
|
||||
this.negate = negate
|
||||
}
|
||||
|
||||
// set partial to true to test if, for example,
|
||||
// "/a/b" matches the start of "/*/b/*/d"
|
||||
// Partial means, if you run out of file before you run
|
||||
// out of pattern, then that's fine, as long as all
|
||||
// the parts match.
|
||||
matchOne (file, pattern, partial) {
|
||||
if (pattern.indexOf(GLOBSTAR) !== -1) {
|
||||
return this._matchGlobstar(file, pattern, partial, 0, 0)
|
||||
}
|
||||
return this._matchOne(file, pattern, partial, 0, 0)
|
||||
}
|
||||
|
||||
_matchGlobstar (file, pattern, partial, fileIndex, patternIndex) {
|
||||
// find first globstar from patternIndex
|
||||
let firstgs = -1
|
||||
for (let i = patternIndex; i < pattern.length; i++) {
|
||||
if (pattern[i] === GLOBSTAR) { firstgs = i; break }
|
||||
}
|
||||
|
||||
// find last globstar
|
||||
let lastgs = -1
|
||||
for (let i = pattern.length - 1; i >= 0; i--) {
|
||||
if (pattern[i] === GLOBSTAR) { lastgs = i; break }
|
||||
}
|
||||
|
||||
const head = pattern.slice(patternIndex, firstgs)
|
||||
const body = partial ? pattern.slice(firstgs + 1) : pattern.slice(firstgs + 1, lastgs)
|
||||
const tail = partial ? [] : pattern.slice(lastgs + 1)
|
||||
|
||||
// check the head
|
||||
if (head.length) {
|
||||
const fileHead = file.slice(fileIndex, fileIndex + head.length)
|
||||
if (!this._matchOne(fileHead, head, partial, 0, 0)) {
|
||||
return false
|
||||
}
|
||||
fileIndex += head.length
|
||||
}
|
||||
|
||||
// check the tail
|
||||
let fileTailMatch = 0
|
||||
if (tail.length) {
|
||||
if (tail.length + fileIndex > file.length) return false
|
||||
|
||||
const tailStart = file.length - tail.length
|
||||
if (this._matchOne(file, tail, partial, tailStart, 0)) {
|
||||
fileTailMatch = tail.length
|
||||
} else {
|
||||
// affordance for stuff like a/**/* matching a/b/
|
||||
if (file[file.length - 1] !== '' ||
|
||||
fileIndex + tail.length === file.length) {
|
||||
return false
|
||||
}
|
||||
if (!this._matchOne(file, tail, partial, tailStart - 1, 0)) {
|
||||
return false
|
||||
}
|
||||
fileTailMatch = tail.length + 1
|
||||
}
|
||||
}
|
||||
|
||||
// if body is empty (single ** between head and tail)
|
||||
if (!body.length) {
|
||||
let sawSome = !!fileTailMatch
|
||||
for (let i = fileIndex; i < file.length - fileTailMatch; i++) {
|
||||
const f = String(file[i])
|
||||
sawSome = true
|
||||
if (f === '.' || f === '..' ||
|
||||
(!this.options.dot && f.charAt(0) === '.')) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return partial || sawSome
|
||||
}
|
||||
|
||||
// split body into segments at each GLOBSTAR
|
||||
const bodySegments = [[[], 0]]
|
||||
let currentBody = bodySegments[0]
|
||||
let nonGsParts = 0
|
||||
const nonGsPartsSums = [0]
|
||||
for (const b of body) {
|
||||
if (b === GLOBSTAR) {
|
||||
nonGsPartsSums.push(nonGsParts)
|
||||
currentBody = [[], 0]
|
||||
bodySegments.push(currentBody)
|
||||
} else {
|
||||
currentBody[0].push(b)
|
||||
nonGsParts++
|
||||
}
|
||||
}
|
||||
|
||||
let idx = bodySegments.length - 1
|
||||
const fileLength = file.length - fileTailMatch
|
||||
for (const b of bodySegments) {
|
||||
b[1] = fileLength - (nonGsPartsSums[idx--] + b[0].length)
|
||||
}
|
||||
|
||||
return !!this._matchGlobStarBodySections(
|
||||
file, bodySegments, fileIndex, 0, partial, 0, !!fileTailMatch
|
||||
)
|
||||
}
|
||||
|
||||
// return false for "nope, not matching"
|
||||
// return null for "not matching, cannot keep trying"
|
||||
_matchGlobStarBodySections (
|
||||
file, bodySegments, fileIndex, bodyIndex, partial, globStarDepth, sawTail
|
||||
) {
|
||||
const bs = bodySegments[bodyIndex]
|
||||
if (!bs) {
|
||||
// just make sure there are no bad dots
|
||||
for (let i = fileIndex; i < file.length; i++) {
|
||||
sawTail = true
|
||||
const f = file[i]
|
||||
if (f === '.' || f === '..' ||
|
||||
(!this.options.dot && f.charAt(0) === '.')) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return sawTail
|
||||
}
|
||||
|
||||
const [body, after] = bs
|
||||
while (fileIndex <= after) {
|
||||
const m = this._matchOne(
|
||||
file.slice(0, fileIndex + body.length),
|
||||
body,
|
||||
partial,
|
||||
fileIndex,
|
||||
0
|
||||
)
|
||||
// if limit exceeded, no match. intentional false negative,
|
||||
// acceptable break in correctness for security.
|
||||
if (m && globStarDepth < this.maxGlobstarRecursion) {
|
||||
const sub = this._matchGlobStarBodySections(
|
||||
file, bodySegments,
|
||||
fileIndex + body.length, bodyIndex + 1,
|
||||
partial, globStarDepth + 1, sawTail
|
||||
)
|
||||
if (sub !== false) {
|
||||
return sub
|
||||
}
|
||||
}
|
||||
const f = file[fileIndex]
|
||||
if (f === '.' || f === '..' ||
|
||||
(!this.options.dot && f.charAt(0) === '.')) {
|
||||
return false
|
||||
}
|
||||
fileIndex++
|
||||
}
|
||||
return partial || null
|
||||
}
|
||||
|
||||
_matchOne (file, pattern, partial, fileIndex, patternIndex) {
|
||||
let fi, pi, fl, pl
|
||||
for (
|
||||
fi = fileIndex, pi = patternIndex, fl = file.length, pl = pattern.length
|
||||
; (fi < fl) && (pi < pl)
|
||||
; fi++, pi++
|
||||
) {
|
||||
this.debug('matchOne loop')
|
||||
const p = pattern[pi]
|
||||
const f = file[fi]
|
||||
|
||||
this.debug(pattern, p, f)
|
||||
|
||||
// should be impossible.
|
||||
// some invalid regexp stuff in the set.
|
||||
/* istanbul ignore if */
|
||||
if (p === false || p === GLOBSTAR) return false
|
||||
|
||||
// something other than **
|
||||
// non-magic patterns just have to match exactly
|
||||
// patterns with magic have been turned into regexps.
|
||||
let hit
|
||||
if (typeof p === 'string') {
|
||||
hit = f === p
|
||||
this.debug('string match', p, f, hit)
|
||||
} else {
|
||||
hit = f.match(p)
|
||||
this.debug('pattern match', p, f, hit)
|
||||
}
|
||||
|
||||
if (!hit) return false
|
||||
}
|
||||
|
||||
// now either we fell off the end of the pattern, or we're done.
|
||||
if (fi === fl && pi === pl) {
|
||||
// ran out of pattern and filename at the same time.
|
||||
// an exact hit!
|
||||
return true
|
||||
} else if (fi === fl) {
|
||||
// ran out of file, but still had pattern left.
|
||||
// this is ok if we're doing the match as part of
|
||||
// a glob fs traversal.
|
||||
return partial
|
||||
} else /* istanbul ignore else */ if (pi === pl) {
|
||||
// ran out of pattern, still have file left.
|
||||
// this is only acceptable if we're on the very last
|
||||
// empty segment of a file with a trailing slash.
|
||||
// a/* should match a/b/
|
||||
return (fi === fl - 1) && (file[fi] === '')
|
||||
}
|
||||
|
||||
// should be unreachable.
|
||||
/* istanbul ignore next */
|
||||
throw new Error('wtf?')
|
||||
}
|
||||
|
||||
braceExpand () {
|
||||
return braceExpand(this.pattern, this.options)
|
||||
}
|
||||
|
||||
parse (pattern, isSub) {
|
||||
assertValidPattern(pattern)
|
||||
|
||||
const options = this.options
|
||||
|
||||
// shortcuts
|
||||
if (pattern === '**') {
|
||||
if (!options.noglobstar)
|
||||
return GLOBSTAR
|
||||
else
|
||||
pattern = '*'
|
||||
}
|
||||
if (pattern === '') return ''
|
||||
|
||||
let re = ''
|
||||
let hasMagic = false
|
||||
let escaping = false
|
||||
// ? => one single character
|
||||
const patternListStack = []
|
||||
const negativeLists = []
|
||||
let stateChar
|
||||
let inClass = false
|
||||
let reClassStart = -1
|
||||
let classStart = -1
|
||||
let cs
|
||||
let pl
|
||||
let sp
|
||||
// . and .. never match anything that doesn't start with .,
|
||||
// even when options.dot is set. However, if the pattern
|
||||
// starts with ., then traversal patterns can match.
|
||||
let dotTravAllowed = pattern.charAt(0) === '.'
|
||||
let dotFileAllowed = options.dot || dotTravAllowed
|
||||
const patternStart = () =>
|
||||
dotTravAllowed
|
||||
? ''
|
||||
: dotFileAllowed
|
||||
? '(?!(?:^|\\/)\\.{1,2}(?:$|\\/))'
|
||||
: '(?!\\.)'
|
||||
const subPatternStart = (p) =>
|
||||
p.charAt(0) === '.'
|
||||
? ''
|
||||
: options.dot
|
||||
? '(?!(?:^|\\/)\\.{1,2}(?:$|\\/))'
|
||||
: '(?!\\.)'
|
||||
|
||||
|
||||
const clearStateChar = () => {
|
||||
if (stateChar) {
|
||||
// we had some state-tracking character
|
||||
// that wasn't consumed by this pass.
|
||||
switch (stateChar) {
|
||||
case '*':
|
||||
re += star
|
||||
hasMagic = true
|
||||
break
|
||||
case '?':
|
||||
re += qmark
|
||||
hasMagic = true
|
||||
break
|
||||
default:
|
||||
re += '\\' + stateChar
|
||||
break
|
||||
}
|
||||
this.debug('clearStateChar %j %j', stateChar, re)
|
||||
stateChar = false
|
||||
}
|
||||
}
|
||||
|
||||
for (let i = 0, c; (i < pattern.length) && (c = pattern.charAt(i)); i++) {
|
||||
this.debug('%s\t%s %s %j', pattern, i, re, c)
|
||||
|
||||
// skip over any that are escaped.
|
||||
if (escaping) {
|
||||
/* istanbul ignore next - completely not allowed, even escaped. */
|
||||
if (c === '/') {
|
||||
return false
|
||||
}
|
||||
|
||||
if (reSpecials[c]) {
|
||||
re += '\\'
|
||||
}
|
||||
re += c
|
||||
escaping = false
|
||||
continue
|
||||
}
|
||||
|
||||
switch (c) {
|
||||
/* istanbul ignore next */
|
||||
case '/': {
|
||||
// Should already be path-split by now.
|
||||
return false
|
||||
}
|
||||
|
||||
case '\\':
|
||||
if (inClass && pattern.charAt(i + 1) === '-') {
|
||||
re += c
|
||||
continue
|
||||
}
|
||||
|
||||
clearStateChar()
|
||||
escaping = true
|
||||
continue
|
||||
|
||||
// the various stateChar values
|
||||
// for the "extglob" stuff.
|
||||
case '?':
|
||||
case '*':
|
||||
case '+':
|
||||
case '@':
|
||||
case '!':
|
||||
this.debug('%s\t%s %s %j <-- stateChar', pattern, i, re, c)
|
||||
|
||||
// all of those are literals inside a class, except that
|
||||
// the glob [!a] means [^a] in regexp
|
||||
if (inClass) {
|
||||
this.debug(' in class')
|
||||
if (c === '!' && i === classStart + 1) c = '^'
|
||||
re += c
|
||||
continue
|
||||
}
|
||||
|
||||
// coalesce consecutive non-globstar * characters
|
||||
if (c === '*' && stateChar === '*') continue
|
||||
|
||||
// if we already have a stateChar, then it means
|
||||
// that there was something like ** or +? in there.
|
||||
// Handle the stateChar, then proceed with this one.
|
||||
this.debug('call clearStateChar %j', stateChar)
|
||||
clearStateChar()
|
||||
stateChar = c
|
||||
// if extglob is disabled, then +(asdf|foo) isn't a thing.
|
||||
// just clear the statechar *now*, rather than even diving into
|
||||
// the patternList stuff.
|
||||
if (options.noext) clearStateChar()
|
||||
continue
|
||||
|
||||
case '(': {
|
||||
if (inClass) {
|
||||
re += '('
|
||||
continue
|
||||
}
|
||||
|
||||
if (!stateChar) {
|
||||
re += '\\('
|
||||
continue
|
||||
}
|
||||
|
||||
const plEntry = {
|
||||
type: stateChar,
|
||||
start: i - 1,
|
||||
reStart: re.length,
|
||||
open: plTypes[stateChar].open,
|
||||
close: plTypes[stateChar].close,
|
||||
}
|
||||
this.debug(this.pattern, '\t', plEntry)
|
||||
patternListStack.push(plEntry)
|
||||
// negation is (?:(?!(?:js)(?:<rest>))[^/]*)
|
||||
re += plEntry.open
|
||||
// next entry starts with a dot maybe?
|
||||
if (plEntry.start === 0 && plEntry.type !== '!') {
|
||||
dotTravAllowed = true
|
||||
re += subPatternStart(pattern.slice(i + 1))
|
||||
}
|
||||
this.debug('plType %j %j', stateChar, re)
|
||||
stateChar = false
|
||||
continue
|
||||
}
|
||||
|
||||
case ')': {
|
||||
const plEntry = patternListStack[patternListStack.length - 1]
|
||||
if (inClass || !plEntry) {
|
||||
re += '\\)'
|
||||
continue
|
||||
}
|
||||
patternListStack.pop()
|
||||
|
||||
// closing an extglob
|
||||
clearStateChar()
|
||||
hasMagic = true
|
||||
pl = plEntry
|
||||
// negation is (?:(?!js)[^/]*)
|
||||
// The others are (?:<pattern>)<type>
|
||||
re += pl.close
|
||||
if (pl.type === '!') {
|
||||
negativeLists.push(Object.assign(pl, { reEnd: re.length }))
|
||||
}
|
||||
continue
|
||||
}
|
||||
|
||||
case '|': {
|
||||
const plEntry = patternListStack[patternListStack.length - 1]
|
||||
if (inClass || !plEntry) {
|
||||
re += '\\|'
|
||||
continue
|
||||
}
|
||||
|
||||
clearStateChar()
|
||||
re += '|'
|
||||
// next subpattern can start with a dot?
|
||||
if (plEntry.start === 0 && plEntry.type !== '!') {
|
||||
dotTravAllowed = true
|
||||
re += subPatternStart(pattern.slice(i + 1))
|
||||
}
|
||||
continue
|
||||
}
|
||||
|
||||
// these are mostly the same in regexp and glob
|
||||
case '[':
|
||||
// swallow any state-tracking char before the [
|
||||
clearStateChar()
|
||||
|
||||
if (inClass) {
|
||||
re += '\\' + c
|
||||
continue
|
||||
}
|
||||
|
||||
inClass = true
|
||||
classStart = i
|
||||
reClassStart = re.length
|
||||
re += c
|
||||
continue
|
||||
|
||||
case ']':
|
||||
// a right bracket shall lose its special
|
||||
// meaning and represent itself in
|
||||
// a bracket expression if it occurs
|
||||
// first in the list. -- POSIX.2 2.8.3.2
|
||||
if (i === classStart + 1 || !inClass) {
|
||||
re += '\\' + c
|
||||
continue
|
||||
}
|
||||
|
||||
// split where the last [ was, make sure we don't have
|
||||
// an invalid re. if so, re-walk the contents of the
|
||||
// would-be class to re-translate any characters that
|
||||
// were passed through as-is
|
||||
// TODO: It would probably be faster to determine this
|
||||
// without a try/catch and a new RegExp, but it's tricky
|
||||
// to do safely. For now, this is safe and works.
|
||||
cs = pattern.substring(classStart + 1, i)
|
||||
try {
|
||||
RegExp('[' + braExpEscape(charUnescape(cs)) + ']')
|
||||
// looks good, finish up the class.
|
||||
re += c
|
||||
} catch (er) {
|
||||
// out of order ranges in JS are errors, but in glob syntax,
|
||||
// they're just a range that matches nothing.
|
||||
re = re.substring(0, reClassStart) + '(?:$.)' // match nothing ever
|
||||
}
|
||||
hasMagic = true
|
||||
inClass = false
|
||||
continue
|
||||
|
||||
default:
|
||||
// swallow any state char that wasn't consumed
|
||||
clearStateChar()
|
||||
|
||||
if (reSpecials[c] && !(c === '^' && inClass)) {
|
||||
re += '\\'
|
||||
}
|
||||
|
||||
re += c
|
||||
break
|
||||
|
||||
} // switch
|
||||
} // for
|
||||
|
||||
// handle the case where we left a class open.
|
||||
// "[abc" is valid, equivalent to "\[abc"
|
||||
if (inClass) {
|
||||
// split where the last [ was, and escape it
|
||||
// this is a huge pita. We now have to re-walk
|
||||
// the contents of the would-be class to re-translate
|
||||
// any characters that were passed through as-is
|
||||
cs = pattern.slice(classStart + 1)
|
||||
sp = this.parse(cs, SUBPARSE)
|
||||
re = re.substring(0, reClassStart) + '\\[' + sp[0]
|
||||
hasMagic = hasMagic || sp[1]
|
||||
}
|
||||
|
||||
// handle the case where we had a +( thing at the *end*
|
||||
// of the pattern.
|
||||
// each pattern list stack adds 3 chars, and we need to go through
|
||||
// and escape any | chars that were passed through as-is for the regexp.
|
||||
// Go through and escape them, taking care not to double-escape any
|
||||
// | chars that were already escaped.
|
||||
for (pl = patternListStack.pop(); pl; pl = patternListStack.pop()) {
|
||||
let tail
|
||||
tail = re.slice(pl.reStart + pl.open.length)
|
||||
this.debug('setting tail', re, pl)
|
||||
// maybe some even number of \, then maybe 1 \, followed by a |
|
||||
tail = tail.replace(/((?:\\{2}){0,64})(\\?)\|/g, (_, $1, $2) => {
|
||||
/* istanbul ignore else - should already be done */
|
||||
if (!$2) {
|
||||
// the | isn't already escaped, so escape it.
|
||||
$2 = '\\'
|
||||
}
|
||||
|
||||
// need to escape all those slashes *again*, without escaping the
|
||||
// one that we need for escaping the | character. As it works out,
|
||||
// escaping an even number of slashes can be done by simply repeating
|
||||
// it exactly after itself. That's why this trick works.
|
||||
//
|
||||
// I am sorry that you have to see this.
|
||||
return $1 + $1 + $2 + '|'
|
||||
})
|
||||
|
||||
this.debug('tail=%j\n %s', tail, tail, pl, re)
|
||||
const t = pl.type === '*' ? star
|
||||
: pl.type === '?' ? qmark
|
||||
: '\\' + pl.type
|
||||
|
||||
hasMagic = true
|
||||
re = re.slice(0, pl.reStart) + t + '\\(' + tail
|
||||
}
|
||||
|
||||
// handle trailing things that only matter at the very end.
|
||||
clearStateChar()
|
||||
if (escaping) {
|
||||
// trailing \\
|
||||
re += '\\\\'
|
||||
}
|
||||
|
||||
// only need to apply the nodot start if the re starts with
|
||||
// something that could conceivably capture a dot
|
||||
const addPatternStart = addPatternStartSet[re.charAt(0)]
|
||||
|
||||
// Hack to work around lack of negative lookbehind in JS
|
||||
// A pattern like: *.!(x).!(y|z) needs to ensure that a name
|
||||
// like 'a.xyz.yz' doesn't match. So, the first negative
|
||||
// lookahead, has to look ALL the way ahead, to the end of
|
||||
// the pattern.
|
||||
for (let n = negativeLists.length - 1; n > -1; n--) {
|
||||
const nl = negativeLists[n]
|
||||
|
||||
const nlBefore = re.slice(0, nl.reStart)
|
||||
const nlFirst = re.slice(nl.reStart, nl.reEnd - 8)
|
||||
let nlAfter = re.slice(nl.reEnd)
|
||||
const nlLast = re.slice(nl.reEnd - 8, nl.reEnd) + nlAfter
|
||||
|
||||
// Handle nested stuff like *(*.js|!(*.json)), where open parens
|
||||
// mean that we should *not* include the ) in the bit that is considered
|
||||
// "after" the negated section.
|
||||
const closeParensBefore = nlBefore.split(')').length
|
||||
const openParensBefore = nlBefore.split('(').length - closeParensBefore
|
||||
let cleanAfter = nlAfter
|
||||
for (let i = 0; i < openParensBefore; i++) {
|
||||
cleanAfter = cleanAfter.replace(/\)[+*?]?/, '')
|
||||
}
|
||||
nlAfter = cleanAfter
|
||||
|
||||
const dollar = nlAfter === '' && isSub !== SUBPARSE ? '(?:$|\\/)' : ''
|
||||
|
||||
re = nlBefore + nlFirst + nlAfter + dollar + nlLast
|
||||
}
|
||||
|
||||
// if the re is not "" at this point, then we need to make sure
|
||||
// it doesn't match against an empty path part.
|
||||
// Otherwise a/* will match a/, which it should not.
|
||||
if (re !== '' && hasMagic) {
|
||||
re = '(?=.)' + re
|
||||
}
|
||||
|
||||
if (addPatternStart) {
|
||||
re = patternStart() + re
|
||||
}
|
||||
|
||||
// parsing just a piece of a larger pattern.
|
||||
if (isSub === SUBPARSE) {
|
||||
return [re, hasMagic]
|
||||
}
|
||||
|
||||
// if it's nocase, and the lcase/uppercase don't match, it's magic
|
||||
if (options.nocase && !hasMagic) {
|
||||
hasMagic = pattern.toUpperCase() !== pattern.toLowerCase()
|
||||
}
|
||||
|
||||
// skip the regexp for non-magical patterns
|
||||
// unescape anything in it, though, so that it'll be
|
||||
// an exact match against a file etc.
|
||||
if (!hasMagic) {
|
||||
return globUnescape(pattern)
|
||||
}
|
||||
|
||||
const flags = options.nocase ? 'i' : ''
|
||||
try {
|
||||
return Object.assign(new RegExp('^' + re + '$', flags), {
|
||||
_glob: pattern,
|
||||
_src: re,
|
||||
})
|
||||
} catch (er) /* istanbul ignore next - should be impossible */ {
|
||||
// If it was an invalid regular expression, then it can't match
|
||||
// anything. This trick looks for a character after the end of
|
||||
// the string, which is of course impossible, except in multi-line
|
||||
// mode, but it's not a /m regex.
|
||||
return new RegExp('$.')
|
||||
}
|
||||
}
|
||||
|
||||
makeRe () {
|
||||
if (this.regexp || this.regexp === false) return this.regexp
|
||||
|
||||
// at this point, this.set is a 2d array of partial
|
||||
// pattern strings, or "**".
|
||||
//
|
||||
// It's better to use .match(). This function shouldn't
|
||||
// be used, really, but it's pretty convenient sometimes,
|
||||
// when you just want to work with a regex.
|
||||
const set = this.set
|
||||
|
||||
if (!set.length) {
|
||||
this.regexp = false
|
||||
return this.regexp
|
||||
}
|
||||
const options = this.options
|
||||
|
||||
const twoStar = options.noglobstar ? star
|
||||
: options.dot ? twoStarDot
|
||||
: twoStarNoDot
|
||||
const flags = options.nocase ? 'i' : ''
|
||||
|
||||
// coalesce globstars and regexpify non-globstar patterns
|
||||
// if it's the only item, then we just do one twoStar
|
||||
// if it's the first, and there are more, prepend (\/|twoStar\/)? to next
|
||||
// if it's the last, append (\/twoStar|) to previous
|
||||
// if it's in the middle, append (\/|\/twoStar\/) to previous
|
||||
// then filter out GLOBSTAR symbols
|
||||
let re = set.map(pattern => {
|
||||
pattern = pattern.map(p =>
|
||||
typeof p === 'string' ? regExpEscape(p)
|
||||
: p === GLOBSTAR ? GLOBSTAR
|
||||
: p._src
|
||||
).reduce((set, p) => {
|
||||
if (!(set[set.length - 1] === GLOBSTAR && p === GLOBSTAR)) {
|
||||
set.push(p)
|
||||
}
|
||||
return set
|
||||
}, [])
|
||||
pattern.forEach((p, i) => {
|
||||
if (p !== GLOBSTAR || pattern[i-1] === GLOBSTAR) {
|
||||
return
|
||||
}
|
||||
if (i === 0) {
|
||||
if (pattern.length > 1) {
|
||||
pattern[i+1] = '(?:\\\/|' + twoStar + '\\\/)?' + pattern[i+1]
|
||||
} else {
|
||||
pattern[i] = twoStar
|
||||
}
|
||||
} else if (i === pattern.length - 1) {
|
||||
pattern[i-1] += '(?:\\\/|' + twoStar + ')?'
|
||||
} else {
|
||||
pattern[i-1] += '(?:\\\/|\\\/' + twoStar + '\\\/)' + pattern[i+1]
|
||||
pattern[i+1] = GLOBSTAR
|
||||
}
|
||||
})
|
||||
return pattern.filter(p => p !== GLOBSTAR).join('/')
|
||||
}).join('|')
|
||||
|
||||
// must match entire pattern
|
||||
// ending in a * or ** will make it less strict.
|
||||
re = '^(?:' + re + ')$'
|
||||
|
||||
// can match anything, as long as it's not this.
|
||||
if (this.negate) re = '^(?!' + re + ').*$'
|
||||
|
||||
try {
|
||||
this.regexp = new RegExp(re, flags)
|
||||
} catch (ex) /* istanbul ignore next - should be impossible */ {
|
||||
this.regexp = false
|
||||
}
|
||||
return this.regexp
|
||||
}
|
||||
|
||||
match (f, partial = this.partial) {
|
||||
this.debug('match', f, this.pattern)
|
||||
// short-circuit in the case of busted things.
|
||||
// comments, etc.
|
||||
if (this.comment) return false
|
||||
if (this.empty) return f === ''
|
||||
|
||||
if (f === '/' && partial) return true
|
||||
|
||||
const options = this.options
|
||||
|
||||
// windows: need to use /, not \
|
||||
if (path.sep !== '/') {
|
||||
f = f.split(path.sep).join('/')
|
||||
}
|
||||
|
||||
// treat the test path as a set of pathparts.
|
||||
f = f.split(slashSplit)
|
||||
this.debug(this.pattern, 'split', f)
|
||||
|
||||
// just ONE of the pattern sets in this.set needs to match
|
||||
// in order for it to be valid. If negating, then just one
|
||||
// match means that we have failed.
|
||||
// Either way, return on the first hit.
|
||||
|
||||
const set = this.set
|
||||
this.debug(this.pattern, 'set', set)
|
||||
|
||||
// Find the basename of the path by looking for the last non-empty segment
|
||||
let filename
|
||||
for (let i = f.length - 1; i >= 0; i--) {
|
||||
filename = f[i]
|
||||
if (filename) break
|
||||
}
|
||||
|
||||
for (let i = 0; i < set.length; i++) {
|
||||
const pattern = set[i]
|
||||
let file = f
|
||||
if (options.matchBase && pattern.length === 1) {
|
||||
file = [filename]
|
||||
}
|
||||
const hit = this.matchOne(file, pattern, partial)
|
||||
if (hit) {
|
||||
if (options.flipNegate) return true
|
||||
return !this.negate
|
||||
}
|
||||
}
|
||||
|
||||
// didn't get any hits. this is success if it's a negative
|
||||
// pattern, failure otherwise.
|
||||
if (options.flipNegate) return false
|
||||
return this.negate
|
||||
}
|
||||
|
||||
static defaults (def) {
|
||||
return minimatch.defaults(def).Minimatch
|
||||
}
|
||||
}
|
||||
|
||||
minimatch.Minimatch = Minimatch
|
||||
35
electron/node_modules/cacache/node_modules/minimatch/package.json
generated
vendored
Normal file
35
electron/node_modules/cacache/node_modules/minimatch/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,35 @@
|
|||
{
|
||||
"author": "Isaac Z. Schlueter <i@izs.me> (http://blog.izs.me)",
|
||||
"name": "minimatch",
|
||||
"description": "a glob matcher in javascript",
|
||||
"publishConfig": {
|
||||
"tag": "legacy-v5"
|
||||
},
|
||||
"version": "5.1.9",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/isaacs/minimatch.git"
|
||||
},
|
||||
"main": "minimatch.js",
|
||||
"scripts": {
|
||||
"test": "tap",
|
||||
"snap": "tap",
|
||||
"preversion": "npm test",
|
||||
"postversion": "npm publish",
|
||||
"prepublishOnly": "git push origin --follow-tags"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=10"
|
||||
},
|
||||
"dependencies": {
|
||||
"brace-expansion": "^2.0.1"
|
||||
},
|
||||
"devDependencies": {
|
||||
"tap": "^16.3.2"
|
||||
},
|
||||
"license": "ISC",
|
||||
"files": [
|
||||
"minimatch.js",
|
||||
"lib"
|
||||
]
|
||||
}
|
||||
15
electron/node_modules/cacache/node_modules/mkdirp/CHANGELOG.md
generated
vendored
Normal file
15
electron/node_modules/cacache/node_modules/mkdirp/CHANGELOG.md
generated
vendored
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
# Changers Lorgs!
|
||||
|
||||
## 1.0
|
||||
|
||||
Full rewrite. Essentially a brand new module.
|
||||
|
||||
- Return a promise instead of taking a callback.
|
||||
- Use native `fs.mkdir(path, { recursive: true })` when available.
|
||||
- Drop support for outdated Node.js versions. (Technically still works on
|
||||
Node.js v8, but only 10 and above are officially supported.)
|
||||
|
||||
## 0.x
|
||||
|
||||
Original and most widely used recursive directory creation implementation
|
||||
in JavaScript, dating back to 2010.
|
||||
21
electron/node_modules/cacache/node_modules/mkdirp/LICENSE
generated
vendored
Normal file
21
electron/node_modules/cacache/node_modules/mkdirp/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
Copyright James Halliday (mail@substack.net) and Isaac Z. Schlueter (i@izs.me)
|
||||
|
||||
This project is free software released under the MIT license:
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||
THE SOFTWARE.
|
||||
68
electron/node_modules/cacache/node_modules/mkdirp/bin/cmd.js
generated
vendored
Executable file
68
electron/node_modules/cacache/node_modules/mkdirp/bin/cmd.js
generated
vendored
Executable file
|
|
@ -0,0 +1,68 @@
|
|||
#!/usr/bin/env node
|
||||
|
||||
const usage = () => `
|
||||
usage: mkdirp [DIR1,DIR2..] {OPTIONS}
|
||||
|
||||
Create each supplied directory including any necessary parent directories
|
||||
that don't yet exist.
|
||||
|
||||
If the directory already exists, do nothing.
|
||||
|
||||
OPTIONS are:
|
||||
|
||||
-m<mode> If a directory needs to be created, set the mode as an octal
|
||||
--mode=<mode> permission string.
|
||||
|
||||
-v --version Print the mkdirp version number
|
||||
|
||||
-h --help Print this helpful banner
|
||||
|
||||
-p --print Print the first directories created for each path provided
|
||||
|
||||
--manual Use manual implementation, even if native is available
|
||||
`
|
||||
|
||||
const dirs = []
|
||||
const opts = {}
|
||||
let print = false
|
||||
let dashdash = false
|
||||
let manual = false
|
||||
for (const arg of process.argv.slice(2)) {
|
||||
if (dashdash)
|
||||
dirs.push(arg)
|
||||
else if (arg === '--')
|
||||
dashdash = true
|
||||
else if (arg === '--manual')
|
||||
manual = true
|
||||
else if (/^-h/.test(arg) || /^--help/.test(arg)) {
|
||||
console.log(usage())
|
||||
process.exit(0)
|
||||
} else if (arg === '-v' || arg === '--version') {
|
||||
console.log(require('../package.json').version)
|
||||
process.exit(0)
|
||||
} else if (arg === '-p' || arg === '--print') {
|
||||
print = true
|
||||
} else if (/^-m/.test(arg) || /^--mode=/.test(arg)) {
|
||||
const mode = parseInt(arg.replace(/^(-m|--mode=)/, ''), 8)
|
||||
if (isNaN(mode)) {
|
||||
console.error(`invalid mode argument: ${arg}\nMust be an octal number.`)
|
||||
process.exit(1)
|
||||
}
|
||||
opts.mode = mode
|
||||
} else
|
||||
dirs.push(arg)
|
||||
}
|
||||
|
||||
const mkdirp = require('../')
|
||||
const impl = manual ? mkdirp.manual : mkdirp
|
||||
if (dirs.length === 0)
|
||||
console.error(usage())
|
||||
|
||||
Promise.all(dirs.map(dir => impl(dir, opts)))
|
||||
.then(made => print ? made.forEach(m => m && console.log(m)) : null)
|
||||
.catch(er => {
|
||||
console.error(er.message)
|
||||
if (er.code)
|
||||
console.error(' code: ' + er.code)
|
||||
process.exit(1)
|
||||
})
|
||||
31
electron/node_modules/cacache/node_modules/mkdirp/index.js
generated
vendored
Normal file
31
electron/node_modules/cacache/node_modules/mkdirp/index.js
generated
vendored
Normal file
|
|
@ -0,0 +1,31 @@
|
|||
const optsArg = require('./lib/opts-arg.js')
|
||||
const pathArg = require('./lib/path-arg.js')
|
||||
|
||||
const {mkdirpNative, mkdirpNativeSync} = require('./lib/mkdirp-native.js')
|
||||
const {mkdirpManual, mkdirpManualSync} = require('./lib/mkdirp-manual.js')
|
||||
const {useNative, useNativeSync} = require('./lib/use-native.js')
|
||||
|
||||
|
||||
const mkdirp = (path, opts) => {
|
||||
path = pathArg(path)
|
||||
opts = optsArg(opts)
|
||||
return useNative(opts)
|
||||
? mkdirpNative(path, opts)
|
||||
: mkdirpManual(path, opts)
|
||||
}
|
||||
|
||||
const mkdirpSync = (path, opts) => {
|
||||
path = pathArg(path)
|
||||
opts = optsArg(opts)
|
||||
return useNativeSync(opts)
|
||||
? mkdirpNativeSync(path, opts)
|
||||
: mkdirpManualSync(path, opts)
|
||||
}
|
||||
|
||||
mkdirp.sync = mkdirpSync
|
||||
mkdirp.native = (path, opts) => mkdirpNative(pathArg(path), optsArg(opts))
|
||||
mkdirp.manual = (path, opts) => mkdirpManual(pathArg(path), optsArg(opts))
|
||||
mkdirp.nativeSync = (path, opts) => mkdirpNativeSync(pathArg(path), optsArg(opts))
|
||||
mkdirp.manualSync = (path, opts) => mkdirpManualSync(pathArg(path), optsArg(opts))
|
||||
|
||||
module.exports = mkdirp
|
||||
29
electron/node_modules/cacache/node_modules/mkdirp/lib/find-made.js
generated
vendored
Normal file
29
electron/node_modules/cacache/node_modules/mkdirp/lib/find-made.js
generated
vendored
Normal file
|
|
@ -0,0 +1,29 @@
|
|||
const {dirname} = require('path')
|
||||
|
||||
const findMade = (opts, parent, path = undefined) => {
|
||||
// we never want the 'made' return value to be a root directory
|
||||
if (path === parent)
|
||||
return Promise.resolve()
|
||||
|
||||
return opts.statAsync(parent).then(
|
||||
st => st.isDirectory() ? path : undefined, // will fail later
|
||||
er => er.code === 'ENOENT'
|
||||
? findMade(opts, dirname(parent), parent)
|
||||
: undefined
|
||||
)
|
||||
}
|
||||
|
||||
const findMadeSync = (opts, parent, path = undefined) => {
|
||||
if (path === parent)
|
||||
return undefined
|
||||
|
||||
try {
|
||||
return opts.statSync(parent).isDirectory() ? path : undefined
|
||||
} catch (er) {
|
||||
return er.code === 'ENOENT'
|
||||
? findMadeSync(opts, dirname(parent), parent)
|
||||
: undefined
|
||||
}
|
||||
}
|
||||
|
||||
module.exports = {findMade, findMadeSync}
|
||||
64
electron/node_modules/cacache/node_modules/mkdirp/lib/mkdirp-manual.js
generated
vendored
Normal file
64
electron/node_modules/cacache/node_modules/mkdirp/lib/mkdirp-manual.js
generated
vendored
Normal file
|
|
@ -0,0 +1,64 @@
|
|||
const {dirname} = require('path')
|
||||
|
||||
const mkdirpManual = (path, opts, made) => {
|
||||
opts.recursive = false
|
||||
const parent = dirname(path)
|
||||
if (parent === path) {
|
||||
return opts.mkdirAsync(path, opts).catch(er => {
|
||||
// swallowed by recursive implementation on posix systems
|
||||
// any other error is a failure
|
||||
if (er.code !== 'EISDIR')
|
||||
throw er
|
||||
})
|
||||
}
|
||||
|
||||
return opts.mkdirAsync(path, opts).then(() => made || path, er => {
|
||||
if (er.code === 'ENOENT')
|
||||
return mkdirpManual(parent, opts)
|
||||
.then(made => mkdirpManual(path, opts, made))
|
||||
if (er.code !== 'EEXIST' && er.code !== 'EROFS')
|
||||
throw er
|
||||
return opts.statAsync(path).then(st => {
|
||||
if (st.isDirectory())
|
||||
return made
|
||||
else
|
||||
throw er
|
||||
}, () => { throw er })
|
||||
})
|
||||
}
|
||||
|
||||
const mkdirpManualSync = (path, opts, made) => {
|
||||
const parent = dirname(path)
|
||||
opts.recursive = false
|
||||
|
||||
if (parent === path) {
|
||||
try {
|
||||
return opts.mkdirSync(path, opts)
|
||||
} catch (er) {
|
||||
// swallowed by recursive implementation on posix systems
|
||||
// any other error is a failure
|
||||
if (er.code !== 'EISDIR')
|
||||
throw er
|
||||
else
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
try {
|
||||
opts.mkdirSync(path, opts)
|
||||
return made || path
|
||||
} catch (er) {
|
||||
if (er.code === 'ENOENT')
|
||||
return mkdirpManualSync(path, opts, mkdirpManualSync(parent, opts, made))
|
||||
if (er.code !== 'EEXIST' && er.code !== 'EROFS')
|
||||
throw er
|
||||
try {
|
||||
if (!opts.statSync(path).isDirectory())
|
||||
throw er
|
||||
} catch (_) {
|
||||
throw er
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
module.exports = {mkdirpManual, mkdirpManualSync}
|
||||
39
electron/node_modules/cacache/node_modules/mkdirp/lib/mkdirp-native.js
generated
vendored
Normal file
39
electron/node_modules/cacache/node_modules/mkdirp/lib/mkdirp-native.js
generated
vendored
Normal file
|
|
@ -0,0 +1,39 @@
|
|||
const {dirname} = require('path')
|
||||
const {findMade, findMadeSync} = require('./find-made.js')
|
||||
const {mkdirpManual, mkdirpManualSync} = require('./mkdirp-manual.js')
|
||||
|
||||
const mkdirpNative = (path, opts) => {
|
||||
opts.recursive = true
|
||||
const parent = dirname(path)
|
||||
if (parent === path)
|
||||
return opts.mkdirAsync(path, opts)
|
||||
|
||||
return findMade(opts, path).then(made =>
|
||||
opts.mkdirAsync(path, opts).then(() => made)
|
||||
.catch(er => {
|
||||
if (er.code === 'ENOENT')
|
||||
return mkdirpManual(path, opts)
|
||||
else
|
||||
throw er
|
||||
}))
|
||||
}
|
||||
|
||||
const mkdirpNativeSync = (path, opts) => {
|
||||
opts.recursive = true
|
||||
const parent = dirname(path)
|
||||
if (parent === path)
|
||||
return opts.mkdirSync(path, opts)
|
||||
|
||||
const made = findMadeSync(opts, path)
|
||||
try {
|
||||
opts.mkdirSync(path, opts)
|
||||
return made
|
||||
} catch (er) {
|
||||
if (er.code === 'ENOENT')
|
||||
return mkdirpManualSync(path, opts)
|
||||
else
|
||||
throw er
|
||||
}
|
||||
}
|
||||
|
||||
module.exports = {mkdirpNative, mkdirpNativeSync}
|
||||
23
electron/node_modules/cacache/node_modules/mkdirp/lib/opts-arg.js
generated
vendored
Normal file
23
electron/node_modules/cacache/node_modules/mkdirp/lib/opts-arg.js
generated
vendored
Normal file
|
|
@ -0,0 +1,23 @@
|
|||
const { promisify } = require('util')
|
||||
const fs = require('fs')
|
||||
const optsArg = opts => {
|
||||
if (!opts)
|
||||
opts = { mode: 0o777, fs }
|
||||
else if (typeof opts === 'object')
|
||||
opts = { mode: 0o777, fs, ...opts }
|
||||
else if (typeof opts === 'number')
|
||||
opts = { mode: opts, fs }
|
||||
else if (typeof opts === 'string')
|
||||
opts = { mode: parseInt(opts, 8), fs }
|
||||
else
|
||||
throw new TypeError('invalid options argument')
|
||||
|
||||
opts.mkdir = opts.mkdir || opts.fs.mkdir || fs.mkdir
|
||||
opts.mkdirAsync = promisify(opts.mkdir)
|
||||
opts.stat = opts.stat || opts.fs.stat || fs.stat
|
||||
opts.statAsync = promisify(opts.stat)
|
||||
opts.statSync = opts.statSync || opts.fs.statSync || fs.statSync
|
||||
opts.mkdirSync = opts.mkdirSync || opts.fs.mkdirSync || fs.mkdirSync
|
||||
return opts
|
||||
}
|
||||
module.exports = optsArg
|
||||
29
electron/node_modules/cacache/node_modules/mkdirp/lib/path-arg.js
generated
vendored
Normal file
29
electron/node_modules/cacache/node_modules/mkdirp/lib/path-arg.js
generated
vendored
Normal file
|
|
@ -0,0 +1,29 @@
|
|||
const platform = process.env.__TESTING_MKDIRP_PLATFORM__ || process.platform
|
||||
const { resolve, parse } = require('path')
|
||||
const pathArg = path => {
|
||||
if (/\0/.test(path)) {
|
||||
// simulate same failure that node raises
|
||||
throw Object.assign(
|
||||
new TypeError('path must be a string without null bytes'),
|
||||
{
|
||||
path,
|
||||
code: 'ERR_INVALID_ARG_VALUE',
|
||||
}
|
||||
)
|
||||
}
|
||||
|
||||
path = resolve(path)
|
||||
if (platform === 'win32') {
|
||||
const badWinChars = /[*|"<>?:]/
|
||||
const {root} = parse(path)
|
||||
if (badWinChars.test(path.substr(root.length))) {
|
||||
throw Object.assign(new Error('Illegal characters in path.'), {
|
||||
path,
|
||||
code: 'EINVAL',
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
return path
|
||||
}
|
||||
module.exports = pathArg
|
||||
10
electron/node_modules/cacache/node_modules/mkdirp/lib/use-native.js
generated
vendored
Normal file
10
electron/node_modules/cacache/node_modules/mkdirp/lib/use-native.js
generated
vendored
Normal file
|
|
@ -0,0 +1,10 @@
|
|||
const fs = require('fs')
|
||||
|
||||
const version = process.env.__TESTING_MKDIRP_NODE_VERSION__ || process.version
|
||||
const versArr = version.replace(/^v/, '').split('.')
|
||||
const hasNative = +versArr[0] > 10 || +versArr[0] === 10 && +versArr[1] >= 12
|
||||
|
||||
const useNative = !hasNative ? () => false : opts => opts.mkdir === fs.mkdir
|
||||
const useNativeSync = !hasNative ? () => false : opts => opts.mkdirSync === fs.mkdirSync
|
||||
|
||||
module.exports = {useNative, useNativeSync}
|
||||
44
electron/node_modules/cacache/node_modules/mkdirp/package.json
generated
vendored
Normal file
44
electron/node_modules/cacache/node_modules/mkdirp/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,44 @@
|
|||
{
|
||||
"name": "mkdirp",
|
||||
"description": "Recursively mkdir, like `mkdir -p`",
|
||||
"version": "1.0.4",
|
||||
"main": "index.js",
|
||||
"keywords": [
|
||||
"mkdir",
|
||||
"directory",
|
||||
"make dir",
|
||||
"make",
|
||||
"dir",
|
||||
"recursive",
|
||||
"native"
|
||||
],
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "https://github.com/isaacs/node-mkdirp.git"
|
||||
},
|
||||
"scripts": {
|
||||
"test": "tap",
|
||||
"snap": "tap",
|
||||
"preversion": "npm test",
|
||||
"postversion": "npm publish",
|
||||
"postpublish": "git push origin --follow-tags"
|
||||
},
|
||||
"tap": {
|
||||
"check-coverage": true,
|
||||
"coverage-map": "map.js"
|
||||
},
|
||||
"devDependencies": {
|
||||
"require-inject": "^1.4.4",
|
||||
"tap": "^14.10.7"
|
||||
},
|
||||
"bin": "bin/cmd.js",
|
||||
"license": "MIT",
|
||||
"engines": {
|
||||
"node": ">=10"
|
||||
},
|
||||
"files": [
|
||||
"bin",
|
||||
"lib",
|
||||
"index.js"
|
||||
]
|
||||
}
|
||||
266
electron/node_modules/cacache/node_modules/mkdirp/readme.markdown
generated
vendored
Normal file
266
electron/node_modules/cacache/node_modules/mkdirp/readme.markdown
generated
vendored
Normal file
|
|
@ -0,0 +1,266 @@
|
|||
# mkdirp
|
||||
|
||||
Like `mkdir -p`, but in Node.js!
|
||||
|
||||
Now with a modern API and no\* bugs!
|
||||
|
||||
<small>\* may contain some bugs</small>
|
||||
|
||||
# example
|
||||
|
||||
## pow.js
|
||||
|
||||
```js
|
||||
const mkdirp = require('mkdirp')
|
||||
|
||||
// return value is a Promise resolving to the first directory created
|
||||
mkdirp('/tmp/foo/bar/baz').then(made =>
|
||||
console.log(`made directories, starting with ${made}`))
|
||||
```
|
||||
|
||||
Output (where `/tmp/foo` already exists)
|
||||
|
||||
```
|
||||
made directories, starting with /tmp/foo/bar
|
||||
```
|
||||
|
||||
Or, if you don't have time to wait around for promises:
|
||||
|
||||
```js
|
||||
const mkdirp = require('mkdirp')
|
||||
|
||||
// return value is the first directory created
|
||||
const made = mkdirp.sync('/tmp/foo/bar/baz')
|
||||
console.log(`made directories, starting with ${made}`)
|
||||
```
|
||||
|
||||
And now /tmp/foo/bar/baz exists, huzzah!
|
||||
|
||||
# methods
|
||||
|
||||
```js
|
||||
const mkdirp = require('mkdirp')
|
||||
```
|
||||
|
||||
## mkdirp(dir, [opts]) -> Promise<String | undefined>
|
||||
|
||||
Create a new directory and any necessary subdirectories at `dir` with octal
|
||||
permission string `opts.mode`. If `opts` is a string or number, it will be
|
||||
treated as the `opts.mode`.
|
||||
|
||||
If `opts.mode` isn't specified, it defaults to `0o777 &
|
||||
(~process.umask())`.
|
||||
|
||||
Promise resolves to first directory `made` that had to be created, or
|
||||
`undefined` if everything already exists. Promise rejects if any errors
|
||||
are encountered. Note that, in the case of promise rejection, some
|
||||
directories _may_ have been created, as recursive directory creation is not
|
||||
an atomic operation.
|
||||
|
||||
You can optionally pass in an alternate `fs` implementation by passing in
|
||||
`opts.fs`. Your implementation should have `opts.fs.mkdir(path, opts, cb)`
|
||||
and `opts.fs.stat(path, cb)`.
|
||||
|
||||
You can also override just one or the other of `mkdir` and `stat` by
|
||||
passing in `opts.stat` or `opts.mkdir`, or providing an `fs` option that
|
||||
only overrides one of these.
|
||||
|
||||
## mkdirp.sync(dir, opts) -> String|null
|
||||
|
||||
Synchronously create a new directory and any necessary subdirectories at
|
||||
`dir` with octal permission string `opts.mode`. If `opts` is a string or
|
||||
number, it will be treated as the `opts.mode`.
|
||||
|
||||
If `opts.mode` isn't specified, it defaults to `0o777 &
|
||||
(~process.umask())`.
|
||||
|
||||
Returns the first directory that had to be created, or undefined if
|
||||
everything already exists.
|
||||
|
||||
You can optionally pass in an alternate `fs` implementation by passing in
|
||||
`opts.fs`. Your implementation should have `opts.fs.mkdirSync(path, mode)`
|
||||
and `opts.fs.statSync(path)`.
|
||||
|
||||
You can also override just one or the other of `mkdirSync` and `statSync`
|
||||
by passing in `opts.statSync` or `opts.mkdirSync`, or providing an `fs`
|
||||
option that only overrides one of these.
|
||||
|
||||
## mkdirp.manual, mkdirp.manualSync
|
||||
|
||||
Use the manual implementation (not the native one). This is the default
|
||||
when the native implementation is not available or the stat/mkdir
|
||||
implementation is overridden.
|
||||
|
||||
## mkdirp.native, mkdirp.nativeSync
|
||||
|
||||
Use the native implementation (not the manual one). This is the default
|
||||
when the native implementation is available and stat/mkdir are not
|
||||
overridden.
|
||||
|
||||
# implementation
|
||||
|
||||
On Node.js v10.12.0 and above, use the native `fs.mkdir(p,
|
||||
{recursive:true})` option, unless `fs.mkdir`/`fs.mkdirSync` has been
|
||||
overridden by an option.
|
||||
|
||||
## native implementation
|
||||
|
||||
- If the path is a root directory, then pass it to the underlying
|
||||
implementation and return the result/error. (In this case, it'll either
|
||||
succeed or fail, but we aren't actually creating any dirs.)
|
||||
- Walk up the path statting each directory, to find the first path that
|
||||
will be created, `made`.
|
||||
- Call `fs.mkdir(path, { recursive: true })` (or `fs.mkdirSync`)
|
||||
- If error, raise it to the caller.
|
||||
- Return `made`.
|
||||
|
||||
## manual implementation
|
||||
|
||||
- Call underlying `fs.mkdir` implementation, with `recursive: false`
|
||||
- If error:
|
||||
- If path is a root directory, raise to the caller and do not handle it
|
||||
- If ENOENT, mkdirp parent dir, store result as `made`
|
||||
- stat(path)
|
||||
- If error, raise original `mkdir` error
|
||||
- If directory, return `made`
|
||||
- Else, raise original `mkdir` error
|
||||
- else
|
||||
- return `undefined` if a root dir, or `made` if set, or `path`
|
||||
|
||||
## windows vs unix caveat
|
||||
|
||||
On Windows file systems, attempts to create a root directory (ie, a drive
|
||||
letter or root UNC path) will fail. If the root directory exists, then it
|
||||
will fail with `EPERM`. If the root directory does not exist, then it will
|
||||
fail with `ENOENT`.
|
||||
|
||||
On posix file systems, attempts to create a root directory (in recursive
|
||||
mode) will succeed silently, as it is treated like just another directory
|
||||
that already exists. (In non-recursive mode, of course, it fails with
|
||||
`EEXIST`.)
|
||||
|
||||
In order to preserve this system-specific behavior (and because it's not as
|
||||
if we can create the parent of a root directory anyway), attempts to create
|
||||
a root directory are passed directly to the `fs` implementation, and any
|
||||
errors encountered are not handled.
|
||||
|
||||
## native error caveat
|
||||
|
||||
The native implementation (as of at least Node.js v13.4.0) does not provide
|
||||
appropriate errors in some cases (see
|
||||
[nodejs/node#31481](https://github.com/nodejs/node/issues/31481) and
|
||||
[nodejs/node#28015](https://github.com/nodejs/node/issues/28015)).
|
||||
|
||||
In order to work around this issue, the native implementation will fall
|
||||
back to the manual implementation if an `ENOENT` error is encountered.
|
||||
|
||||
# choosing a recursive mkdir implementation
|
||||
|
||||
There are a few to choose from! Use the one that suits your needs best :D
|
||||
|
||||
## use `fs.mkdir(path, {recursive: true}, cb)` if:
|
||||
|
||||
- You wish to optimize performance even at the expense of other factors.
|
||||
- You don't need to know the first dir created.
|
||||
- You are ok with getting `ENOENT` as the error when some other problem is
|
||||
the actual cause.
|
||||
- You can limit your platforms to Node.js v10.12 and above.
|
||||
- You're ok with using callbacks instead of promises.
|
||||
- You don't need/want a CLI.
|
||||
- You don't need to override the `fs` methods in use.
|
||||
|
||||
## use this module (mkdirp 1.x) if:
|
||||
|
||||
- You need to know the first directory that was created.
|
||||
- You wish to use the native implementation if available, but fall back
|
||||
when it's not.
|
||||
- You prefer promise-returning APIs to callback-taking APIs.
|
||||
- You want more useful error messages than the native recursive mkdir
|
||||
provides (at least as of Node.js v13.4), and are ok with re-trying on
|
||||
`ENOENT` to achieve this.
|
||||
- You need (or at least, are ok with) a CLI.
|
||||
- You need to override the `fs` methods in use.
|
||||
|
||||
## use [`make-dir`](http://npm.im/make-dir) if:
|
||||
|
||||
- You do not need to know the first dir created (and wish to save a few
|
||||
`stat` calls when using the native implementation for this reason).
|
||||
- You wish to use the native implementation if available, but fall back
|
||||
when it's not.
|
||||
- You prefer promise-returning APIs to callback-taking APIs.
|
||||
- You are ok with occasionally getting `ENOENT` errors for failures that
|
||||
are actually related to something other than a missing file system entry.
|
||||
- You don't need/want a CLI.
|
||||
- You need to override the `fs` methods in use.
|
||||
|
||||
## use mkdirp 0.x if:
|
||||
|
||||
- You need to know the first directory that was created.
|
||||
- You need (or at least, are ok with) a CLI.
|
||||
- You need to override the `fs` methods in use.
|
||||
- You're ok with using callbacks instead of promises.
|
||||
- You are not running on Windows, where the root-level ENOENT errors can
|
||||
lead to infinite regress.
|
||||
- You think vinyl just sounds warmer and richer for some weird reason.
|
||||
- You are supporting truly ancient Node.js versions, before even the advent
|
||||
of a `Promise` language primitive. (Please don't. You deserve better.)
|
||||
|
||||
# cli
|
||||
|
||||
This package also ships with a `mkdirp` command.
|
||||
|
||||
```
|
||||
$ mkdirp -h
|
||||
|
||||
usage: mkdirp [DIR1,DIR2..] {OPTIONS}
|
||||
|
||||
Create each supplied directory including any necessary parent directories
|
||||
that don't yet exist.
|
||||
|
||||
If the directory already exists, do nothing.
|
||||
|
||||
OPTIONS are:
|
||||
|
||||
-m<mode> If a directory needs to be created, set the mode as an octal
|
||||
--mode=<mode> permission string.
|
||||
|
||||
-v --version Print the mkdirp version number
|
||||
|
||||
-h --help Print this helpful banner
|
||||
|
||||
-p --print Print the first directories created for each path provided
|
||||
|
||||
--manual Use manual implementation, even if native is available
|
||||
```
|
||||
|
||||
# install
|
||||
|
||||
With [npm](http://npmjs.org) do:
|
||||
|
||||
```
|
||||
npm install mkdirp
|
||||
```
|
||||
|
||||
to get the library locally, or
|
||||
|
||||
```
|
||||
npm install -g mkdirp
|
||||
```
|
||||
|
||||
to get the command everywhere, or
|
||||
|
||||
```
|
||||
npx mkdirp ...
|
||||
```
|
||||
|
||||
to run the command without installing it globally.
|
||||
|
||||
# platform support
|
||||
|
||||
This module works on node v8, but only v10 and above are officially
|
||||
supported, as Node v8 reached its LTS end of life 2020-01-01, which is in
|
||||
the past, as of this writing.
|
||||
|
||||
# license
|
||||
|
||||
MIT
|
||||
65
electron/node_modules/cacache/node_modules/rimraf/CHANGELOG.md
generated
vendored
Normal file
65
electron/node_modules/cacache/node_modules/rimraf/CHANGELOG.md
generated
vendored
Normal file
|
|
@ -0,0 +1,65 @@
|
|||
# v3.0
|
||||
|
||||
- Add `--preserve-root` option to executable (default true)
|
||||
- Drop support for Node.js below version 6
|
||||
|
||||
# v2.7
|
||||
|
||||
- Make `glob` an optional dependency
|
||||
|
||||
# 2.6
|
||||
|
||||
- Retry on EBUSY on non-windows platforms as well
|
||||
- Make `rimraf.sync` 10000% more reliable on Windows
|
||||
|
||||
# 2.5
|
||||
|
||||
- Handle Windows EPERM when lstat-ing read-only dirs
|
||||
- Add glob option to pass options to glob
|
||||
|
||||
# 2.4
|
||||
|
||||
- Add EPERM to delay/retry loop
|
||||
- Add `disableGlob` option
|
||||
|
||||
# 2.3
|
||||
|
||||
- Make maxBusyTries and emfileWait configurable
|
||||
- Handle weird SunOS unlink-dir issue
|
||||
- Glob the CLI arg for better Windows support
|
||||
|
||||
# 2.2
|
||||
|
||||
- Handle ENOENT properly on Windows
|
||||
- Allow overriding fs methods
|
||||
- Treat EPERM as indicative of non-empty dir
|
||||
- Remove optional graceful-fs dep
|
||||
- Consistently return null error instead of undefined on success
|
||||
- win32: Treat ENOTEMPTY the same as EBUSY
|
||||
- Add `rimraf` binary
|
||||
|
||||
# 2.1
|
||||
|
||||
- Fix SunOS error code for a non-empty directory
|
||||
- Try rmdir before readdir
|
||||
- Treat EISDIR like EPERM
|
||||
- Remove chmod
|
||||
- Remove lstat polyfill, node 0.7 is not supported
|
||||
|
||||
# 2.0
|
||||
|
||||
- Fix myGid call to check process.getgid
|
||||
- Simplify the EBUSY backoff logic.
|
||||
- Use fs.lstat in node >= 0.7.9
|
||||
- Remove gently option
|
||||
- remove fiber implementation
|
||||
- Delete files that are marked read-only
|
||||
|
||||
# 1.0
|
||||
|
||||
- Allow ENOENT in sync method
|
||||
- Throw when no callback is provided
|
||||
- Make opts.gently an absolute path
|
||||
- use 'stat' if 'lstat' is not available
|
||||
- Consistent error naming, and rethrow non-ENOENT stat errors
|
||||
- add fiber implementation
|
||||
15
electron/node_modules/cacache/node_modules/rimraf/LICENSE
generated
vendored
Normal file
15
electron/node_modules/cacache/node_modules/rimraf/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
The ISC License
|
||||
|
||||
Copyright (c) Isaac Z. Schlueter and Contributors
|
||||
|
||||
Permission to use, copy, modify, and/or distribute this software for any
|
||||
purpose with or without fee is hereby granted, provided that the above
|
||||
copyright notice and this permission notice appear in all copies.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
||||
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
||||
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
||||
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
||||
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR
|
||||
IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
101
electron/node_modules/cacache/node_modules/rimraf/README.md
generated
vendored
Normal file
101
electron/node_modules/cacache/node_modules/rimraf/README.md
generated
vendored
Normal file
|
|
@ -0,0 +1,101 @@
|
|||
[](https://travis-ci.org/isaacs/rimraf) [](https://david-dm.org/isaacs/rimraf) [](https://david-dm.org/isaacs/rimraf#info=devDependencies)
|
||||
|
||||
The [UNIX command](http://en.wikipedia.org/wiki/Rm_(Unix)) `rm -rf` for node.
|
||||
|
||||
Install with `npm install rimraf`, or just drop rimraf.js somewhere.
|
||||
|
||||
## API
|
||||
|
||||
`rimraf(f, [opts], callback)`
|
||||
|
||||
The first parameter will be interpreted as a globbing pattern for files. If you
|
||||
want to disable globbing you can do so with `opts.disableGlob` (defaults to
|
||||
`false`). This might be handy, for instance, if you have filenames that contain
|
||||
globbing wildcard characters.
|
||||
|
||||
The callback will be called with an error if there is one. Certain
|
||||
errors are handled for you:
|
||||
|
||||
* Windows: `EBUSY` and `ENOTEMPTY` - rimraf will back off a maximum of
|
||||
`opts.maxBusyTries` times before giving up, adding 100ms of wait
|
||||
between each attempt. The default `maxBusyTries` is 3.
|
||||
* `ENOENT` - If the file doesn't exist, rimraf will return
|
||||
successfully, since your desired outcome is already the case.
|
||||
* `EMFILE` - Since `readdir` requires opening a file descriptor, it's
|
||||
possible to hit `EMFILE` if too many file descriptors are in use.
|
||||
In the sync case, there's nothing to be done for this. But in the
|
||||
async case, rimraf will gradually back off with timeouts up to
|
||||
`opts.emfileWait` ms, which defaults to 1000.
|
||||
|
||||
## options
|
||||
|
||||
* unlink, chmod, stat, lstat, rmdir, readdir,
|
||||
unlinkSync, chmodSync, statSync, lstatSync, rmdirSync, readdirSync
|
||||
|
||||
In order to use a custom file system library, you can override
|
||||
specific fs functions on the options object.
|
||||
|
||||
If any of these functions are present on the options object, then
|
||||
the supplied function will be used instead of the default fs
|
||||
method.
|
||||
|
||||
Sync methods are only relevant for `rimraf.sync()`, of course.
|
||||
|
||||
For example:
|
||||
|
||||
```javascript
|
||||
var myCustomFS = require('some-custom-fs')
|
||||
|
||||
rimraf('some-thing', myCustomFS, callback)
|
||||
```
|
||||
|
||||
* maxBusyTries
|
||||
|
||||
If an `EBUSY`, `ENOTEMPTY`, or `EPERM` error code is encountered
|
||||
on Windows systems, then rimraf will retry with a linear backoff
|
||||
wait of 100ms longer on each try. The default maxBusyTries is 3.
|
||||
|
||||
Only relevant for async usage.
|
||||
|
||||
* emfileWait
|
||||
|
||||
If an `EMFILE` error is encountered, then rimraf will retry
|
||||
repeatedly with a linear backoff of 1ms longer on each try, until
|
||||
the timeout counter hits this max. The default limit is 1000.
|
||||
|
||||
If you repeatedly encounter `EMFILE` errors, then consider using
|
||||
[graceful-fs](http://npm.im/graceful-fs) in your program.
|
||||
|
||||
Only relevant for async usage.
|
||||
|
||||
* glob
|
||||
|
||||
Set to `false` to disable [glob](http://npm.im/glob) pattern
|
||||
matching.
|
||||
|
||||
Set to an object to pass options to the glob module. The default
|
||||
glob options are `{ nosort: true, silent: true }`.
|
||||
|
||||
Glob version 6 is used in this module.
|
||||
|
||||
Relevant for both sync and async usage.
|
||||
|
||||
* disableGlob
|
||||
|
||||
Set to any non-falsey value to disable globbing entirely.
|
||||
(Equivalent to setting `glob: false`.)
|
||||
|
||||
## rimraf.sync
|
||||
|
||||
It can remove stuff synchronously, too. But that's not so good. Use
|
||||
the async API. It's better.
|
||||
|
||||
## CLI
|
||||
|
||||
If installed with `npm install rimraf -g` it can be used as a global
|
||||
command `rimraf <path> [<path> ...]` which is useful for cross platform support.
|
||||
|
||||
## mkdirp
|
||||
|
||||
If you need to create a directory recursively, check out
|
||||
[mkdirp](https://github.com/substack/node-mkdirp).
|
||||
68
electron/node_modules/cacache/node_modules/rimraf/bin.js
generated
vendored
Executable file
68
electron/node_modules/cacache/node_modules/rimraf/bin.js
generated
vendored
Executable file
|
|
@ -0,0 +1,68 @@
|
|||
#!/usr/bin/env node
|
||||
|
||||
const rimraf = require('./')
|
||||
|
||||
const path = require('path')
|
||||
|
||||
const isRoot = arg => /^(\/|[a-zA-Z]:\\)$/.test(path.resolve(arg))
|
||||
const filterOutRoot = arg => {
|
||||
const ok = preserveRoot === false || !isRoot(arg)
|
||||
if (!ok) {
|
||||
console.error(`refusing to remove ${arg}`)
|
||||
console.error('Set --no-preserve-root to allow this')
|
||||
}
|
||||
return ok
|
||||
}
|
||||
|
||||
let help = false
|
||||
let dashdash = false
|
||||
let noglob = false
|
||||
let preserveRoot = true
|
||||
const args = process.argv.slice(2).filter(arg => {
|
||||
if (dashdash)
|
||||
return !!arg
|
||||
else if (arg === '--')
|
||||
dashdash = true
|
||||
else if (arg === '--no-glob' || arg === '-G')
|
||||
noglob = true
|
||||
else if (arg === '--glob' || arg === '-g')
|
||||
noglob = false
|
||||
else if (arg.match(/^(-+|\/)(h(elp)?|\?)$/))
|
||||
help = true
|
||||
else if (arg === '--preserve-root')
|
||||
preserveRoot = true
|
||||
else if (arg === '--no-preserve-root')
|
||||
preserveRoot = false
|
||||
else
|
||||
return !!arg
|
||||
}).filter(arg => !preserveRoot || filterOutRoot(arg))
|
||||
|
||||
const go = n => {
|
||||
if (n >= args.length)
|
||||
return
|
||||
const options = noglob ? { glob: false } : {}
|
||||
rimraf(args[n], options, er => {
|
||||
if (er)
|
||||
throw er
|
||||
go(n+1)
|
||||
})
|
||||
}
|
||||
|
||||
if (help || args.length === 0) {
|
||||
// If they didn't ask for help, then this is not a "success"
|
||||
const log = help ? console.log : console.error
|
||||
log('Usage: rimraf <path> [<path> ...]')
|
||||
log('')
|
||||
log(' Deletes all files and folders at "path" recursively.')
|
||||
log('')
|
||||
log('Options:')
|
||||
log('')
|
||||
log(' -h, --help Display this usage info')
|
||||
log(' -G, --no-glob Do not expand glob patterns in arguments')
|
||||
log(' -g, --glob Expand glob patterns in arguments (default)')
|
||||
log(' --preserve-root Do not remove \'/\' (default)')
|
||||
log(' --no-preserve-root Do not treat \'/\' specially')
|
||||
log(' -- Stop parsing flags')
|
||||
process.exit(help ? 0 : 1)
|
||||
} else
|
||||
go(0)
|
||||
21
electron/node_modules/cacache/node_modules/rimraf/node_modules/brace-expansion/LICENSE
generated
vendored
Normal file
21
electron/node_modules/cacache/node_modules/rimraf/node_modules/brace-expansion/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
MIT License
|
||||
|
||||
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
129
electron/node_modules/cacache/node_modules/rimraf/node_modules/brace-expansion/README.md
generated
vendored
Normal file
129
electron/node_modules/cacache/node_modules/rimraf/node_modules/brace-expansion/README.md
generated
vendored
Normal file
|
|
@ -0,0 +1,129 @@
|
|||
# brace-expansion
|
||||
|
||||
[Brace expansion](https://www.gnu.org/software/bash/manual/html_node/Brace-Expansion.html),
|
||||
as known from sh/bash, in JavaScript.
|
||||
|
||||
[](http://travis-ci.org/juliangruber/brace-expansion)
|
||||
[](https://www.npmjs.org/package/brace-expansion)
|
||||
[](https://greenkeeper.io/)
|
||||
|
||||
[](https://ci.testling.com/juliangruber/brace-expansion)
|
||||
|
||||
## Example
|
||||
|
||||
```js
|
||||
var expand = require('brace-expansion');
|
||||
|
||||
expand('file-{a,b,c}.jpg')
|
||||
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
|
||||
|
||||
expand('-v{,,}')
|
||||
// => ['-v', '-v', '-v']
|
||||
|
||||
expand('file{0..2}.jpg')
|
||||
// => ['file0.jpg', 'file1.jpg', 'file2.jpg']
|
||||
|
||||
expand('file-{a..c}.jpg')
|
||||
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
|
||||
|
||||
expand('file{2..0}.jpg')
|
||||
// => ['file2.jpg', 'file1.jpg', 'file0.jpg']
|
||||
|
||||
expand('file{0..4..2}.jpg')
|
||||
// => ['file0.jpg', 'file2.jpg', 'file4.jpg']
|
||||
|
||||
expand('file-{a..e..2}.jpg')
|
||||
// => ['file-a.jpg', 'file-c.jpg', 'file-e.jpg']
|
||||
|
||||
expand('file{00..10..5}.jpg')
|
||||
// => ['file00.jpg', 'file05.jpg', 'file10.jpg']
|
||||
|
||||
expand('{{A..C},{a..c}}')
|
||||
// => ['A', 'B', 'C', 'a', 'b', 'c']
|
||||
|
||||
expand('ppp{,config,oe{,conf}}')
|
||||
// => ['ppp', 'pppconfig', 'pppoe', 'pppoeconf']
|
||||
```
|
||||
|
||||
## API
|
||||
|
||||
```js
|
||||
var expand = require('brace-expansion');
|
||||
```
|
||||
|
||||
### var expanded = expand(str)
|
||||
|
||||
Return an array of all possible and valid expansions of `str`. If none are
|
||||
found, `[str]` is returned.
|
||||
|
||||
Valid expansions are:
|
||||
|
||||
```js
|
||||
/^(.*,)+(.+)?$/
|
||||
// {a,b,...}
|
||||
```
|
||||
|
||||
A comma separated list of options, like `{a,b}` or `{a,{b,c}}` or `{,a,}`.
|
||||
|
||||
```js
|
||||
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
|
||||
// {x..y[..incr]}
|
||||
```
|
||||
|
||||
A numeric sequence from `x` to `y` inclusive, with optional increment.
|
||||
If `x` or `y` start with a leading `0`, all the numbers will be padded
|
||||
to have equal length. Negative numbers and backwards iteration work too.
|
||||
|
||||
```js
|
||||
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
|
||||
// {x..y[..incr]}
|
||||
```
|
||||
|
||||
An alphabetic sequence from `x` to `y` inclusive, with optional increment.
|
||||
`x` and `y` must be exactly one character, and if given, `incr` must be a
|
||||
number.
|
||||
|
||||
For compatibility reasons, the string `${` is not eligible for brace expansion.
|
||||
|
||||
## Installation
|
||||
|
||||
With [npm](https://npmjs.org) do:
|
||||
|
||||
```bash
|
||||
npm install brace-expansion
|
||||
```
|
||||
|
||||
## Contributors
|
||||
|
||||
- [Julian Gruber](https://github.com/juliangruber)
|
||||
- [Isaac Z. Schlueter](https://github.com/isaacs)
|
||||
|
||||
## Sponsors
|
||||
|
||||
This module is proudly supported by my [Sponsors](https://github.com/juliangruber/sponsors)!
|
||||
|
||||
Do you want to support modules like this to improve their quality, stability and weigh in on new features? Then please consider donating to my [Patreon](https://www.patreon.com/juliangruber). Not sure how much of my modules you're using? Try [feross/thanks](https://github.com/feross/thanks)!
|
||||
|
||||
## License
|
||||
|
||||
(MIT)
|
||||
|
||||
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy of
|
||||
this software and associated documentation files (the "Software"), to deal in
|
||||
the Software without restriction, including without limitation the rights to
|
||||
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
||||
of the Software, and to permit persons to whom the Software is furnished to do
|
||||
so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
203
electron/node_modules/cacache/node_modules/rimraf/node_modules/brace-expansion/index.js
generated
vendored
Normal file
203
electron/node_modules/cacache/node_modules/rimraf/node_modules/brace-expansion/index.js
generated
vendored
Normal file
|
|
@ -0,0 +1,203 @@
|
|||
var concatMap = require('concat-map');
|
||||
var balanced = require('balanced-match');
|
||||
|
||||
module.exports = expandTop;
|
||||
|
||||
var escSlash = '\0SLASH'+Math.random()+'\0';
|
||||
var escOpen = '\0OPEN'+Math.random()+'\0';
|
||||
var escClose = '\0CLOSE'+Math.random()+'\0';
|
||||
var escComma = '\0COMMA'+Math.random()+'\0';
|
||||
var escPeriod = '\0PERIOD'+Math.random()+'\0';
|
||||
|
||||
function numeric(str) {
|
||||
return parseInt(str, 10) == str
|
||||
? parseInt(str, 10)
|
||||
: str.charCodeAt(0);
|
||||
}
|
||||
|
||||
function escapeBraces(str) {
|
||||
return str.split('\\\\').join(escSlash)
|
||||
.split('\\{').join(escOpen)
|
||||
.split('\\}').join(escClose)
|
||||
.split('\\,').join(escComma)
|
||||
.split('\\.').join(escPeriod);
|
||||
}
|
||||
|
||||
function unescapeBraces(str) {
|
||||
return str.split(escSlash).join('\\')
|
||||
.split(escOpen).join('{')
|
||||
.split(escClose).join('}')
|
||||
.split(escComma).join(',')
|
||||
.split(escPeriod).join('.');
|
||||
}
|
||||
|
||||
|
||||
// Basically just str.split(","), but handling cases
|
||||
// where we have nested braced sections, which should be
|
||||
// treated as individual members, like {a,{b,c},d}
|
||||
function parseCommaParts(str) {
|
||||
if (!str)
|
||||
return [''];
|
||||
|
||||
var parts = [];
|
||||
var m = balanced('{', '}', str);
|
||||
|
||||
if (!m)
|
||||
return str.split(',');
|
||||
|
||||
var pre = m.pre;
|
||||
var body = m.body;
|
||||
var post = m.post;
|
||||
var p = pre.split(',');
|
||||
|
||||
p[p.length-1] += '{' + body + '}';
|
||||
var postParts = parseCommaParts(post);
|
||||
if (post.length) {
|
||||
p[p.length-1] += postParts.shift();
|
||||
p.push.apply(p, postParts);
|
||||
}
|
||||
|
||||
parts.push.apply(parts, p);
|
||||
|
||||
return parts;
|
||||
}
|
||||
|
||||
function expandTop(str, options) {
|
||||
if (!str)
|
||||
return [];
|
||||
|
||||
options = options || {};
|
||||
var max = options.max == null ? Infinity : options.max;
|
||||
|
||||
// I don't know why Bash 4.3 does this, but it does.
|
||||
// Anything starting with {} will have the first two bytes preserved
|
||||
// but *only* at the top level, so {},a}b will not expand to anything,
|
||||
// but a{},b}c will be expanded to [a}c,abc].
|
||||
// One could argue that this is a bug in Bash, but since the goal of
|
||||
// this module is to match Bash's rules, we escape a leading {}
|
||||
if (str.substr(0, 2) === '{}') {
|
||||
str = '\\{\\}' + str.substr(2);
|
||||
}
|
||||
|
||||
return expand(escapeBraces(str), max, true).map(unescapeBraces);
|
||||
}
|
||||
|
||||
function identity(e) {
|
||||
return e;
|
||||
}
|
||||
|
||||
function embrace(str) {
|
||||
return '{' + str + '}';
|
||||
}
|
||||
function isPadded(el) {
|
||||
return /^-?0\d/.test(el);
|
||||
}
|
||||
|
||||
function lte(i, y) {
|
||||
return i <= y;
|
||||
}
|
||||
function gte(i, y) {
|
||||
return i >= y;
|
||||
}
|
||||
|
||||
function expand(str, max, isTop) {
|
||||
var expansions = [];
|
||||
|
||||
var m = balanced('{', '}', str);
|
||||
if (!m || /\$$/.test(m.pre)) return [str];
|
||||
|
||||
var isNumericSequence = /^-?\d+\.\.-?\d+(?:\.\.-?\d+)?$/.test(m.body);
|
||||
var isAlphaSequence = /^[a-zA-Z]\.\.[a-zA-Z](?:\.\.-?\d+)?$/.test(m.body);
|
||||
var isSequence = isNumericSequence || isAlphaSequence;
|
||||
var isOptions = m.body.indexOf(',') >= 0;
|
||||
if (!isSequence && !isOptions) {
|
||||
// {a},b}
|
||||
if (m.post.match(/,(?!,).*\}/)) {
|
||||
str = m.pre + '{' + m.body + escClose + m.post;
|
||||
return expand(str, max, true);
|
||||
}
|
||||
return [str];
|
||||
}
|
||||
|
||||
var n;
|
||||
if (isSequence) {
|
||||
n = m.body.split(/\.\./);
|
||||
} else {
|
||||
n = parseCommaParts(m.body);
|
||||
if (n.length === 1) {
|
||||
// x{{a,b}}y ==> x{a}y x{b}y
|
||||
n = expand(n[0], max, false).map(embrace);
|
||||
if (n.length === 1) {
|
||||
var post = m.post.length
|
||||
? expand(m.post, max, false)
|
||||
: [''];
|
||||
return post.map(function(p) {
|
||||
return m.pre + n[0] + p;
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// at this point, n is the parts, and we know it's not a comma set
|
||||
// with a single entry.
|
||||
|
||||
// no need to expand pre, since it is guaranteed to be free of brace-sets
|
||||
var pre = m.pre;
|
||||
var post = m.post.length
|
||||
? expand(m.post, max, false)
|
||||
: [''];
|
||||
|
||||
var N;
|
||||
|
||||
if (isSequence) {
|
||||
var x = numeric(n[0]);
|
||||
var y = numeric(n[1]);
|
||||
var width = Math.max(n[0].length, n[1].length)
|
||||
var incr = n.length == 3
|
||||
? Math.max(Math.abs(numeric(n[2])), 1)
|
||||
: 1;
|
||||
var test = lte;
|
||||
var reverse = y < x;
|
||||
if (reverse) {
|
||||
incr *= -1;
|
||||
test = gte;
|
||||
}
|
||||
var pad = n.some(isPadded);
|
||||
|
||||
N = [];
|
||||
|
||||
for (var i = x; test(i, y); i += incr) {
|
||||
var c;
|
||||
if (isAlphaSequence) {
|
||||
c = String.fromCharCode(i);
|
||||
if (c === '\\')
|
||||
c = '';
|
||||
} else {
|
||||
c = String(i);
|
||||
if (pad) {
|
||||
var need = width - c.length;
|
||||
if (need > 0) {
|
||||
var z = new Array(need + 1).join('0');
|
||||
if (i < 0)
|
||||
c = '-' + z + c.slice(1);
|
||||
else
|
||||
c = z + c;
|
||||
}
|
||||
}
|
||||
}
|
||||
N.push(c);
|
||||
}
|
||||
} else {
|
||||
N = concatMap(n, function(el) { return expand(el, max, false) });
|
||||
}
|
||||
|
||||
for (var j = 0; j < N.length; j++) {
|
||||
for (var k = 0; k < post.length && expansions.length < max; k++) {
|
||||
var expansion = pre + N[j] + post[k];
|
||||
if (!isTop || isSequence || expansion)
|
||||
expansions.push(expansion);
|
||||
}
|
||||
}
|
||||
|
||||
return expansions;
|
||||
}
|
||||
50
electron/node_modules/cacache/node_modules/rimraf/node_modules/brace-expansion/package.json
generated
vendored
Normal file
50
electron/node_modules/cacache/node_modules/rimraf/node_modules/brace-expansion/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,50 @@
|
|||
{
|
||||
"name": "brace-expansion",
|
||||
"description": "Brace expansion as known from sh/bash",
|
||||
"version": "1.1.14",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/juliangruber/brace-expansion.git"
|
||||
},
|
||||
"homepage": "https://github.com/juliangruber/brace-expansion",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "tape test/*.js",
|
||||
"gentest": "bash test/generate.sh",
|
||||
"bench": "matcha test/perf/bench.js"
|
||||
},
|
||||
"dependencies": {
|
||||
"balanced-match": "^1.0.0",
|
||||
"concat-map": "0.0.1"
|
||||
},
|
||||
"devDependencies": {
|
||||
"matcha": "^0.7.0",
|
||||
"tape": "^4.6.0"
|
||||
},
|
||||
"keywords": [],
|
||||
"author": {
|
||||
"name": "Julian Gruber",
|
||||
"email": "mail@juliangruber.com",
|
||||
"url": "http://juliangruber.com"
|
||||
},
|
||||
"license": "MIT",
|
||||
"testling": {
|
||||
"files": "test/*.js",
|
||||
"browsers": [
|
||||
"ie/8..latest",
|
||||
"firefox/20..latest",
|
||||
"firefox/nightly",
|
||||
"chrome/25..latest",
|
||||
"chrome/canary",
|
||||
"opera/12..latest",
|
||||
"opera/next",
|
||||
"safari/5.1..latest",
|
||||
"ipad/6.0..latest",
|
||||
"iphone/6.0..latest",
|
||||
"android-browser/4.2..latest"
|
||||
]
|
||||
},
|
||||
"publishConfig": {
|
||||
"tag": "1.x"
|
||||
}
|
||||
}
|
||||
21
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/LICENSE
generated
vendored
Normal file
21
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
The ISC License
|
||||
|
||||
Copyright (c) Isaac Z. Schlueter and Contributors
|
||||
|
||||
Permission to use, copy, modify, and/or distribute this software for any
|
||||
purpose with or without fee is hereby granted, provided that the above
|
||||
copyright notice and this permission notice appear in all copies.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
||||
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
||||
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
||||
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
||||
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR
|
||||
IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
|
||||
## Glob Logo
|
||||
|
||||
Glob's logo created by Tanya Brassie <http://tanyabrassie.com/>, licensed
|
||||
under a Creative Commons Attribution-ShareAlike 4.0 International License
|
||||
https://creativecommons.org/licenses/by-sa/4.0/
|
||||
378
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/README.md
generated
vendored
Normal file
378
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/README.md
generated
vendored
Normal file
|
|
@ -0,0 +1,378 @@
|
|||
# Glob
|
||||
|
||||
Match files using the patterns the shell uses, like stars and stuff.
|
||||
|
||||
[](https://travis-ci.org/isaacs/node-glob/) [](https://ci.appveyor.com/project/isaacs/node-glob) [](https://coveralls.io/github/isaacs/node-glob?branch=master)
|
||||
|
||||
This is a glob implementation in JavaScript. It uses the `minimatch`
|
||||
library to do its matching.
|
||||
|
||||

|
||||
|
||||
## Usage
|
||||
|
||||
Install with npm
|
||||
|
||||
```
|
||||
npm i glob
|
||||
```
|
||||
|
||||
```javascript
|
||||
var glob = require("glob")
|
||||
|
||||
// options is optional
|
||||
glob("**/*.js", options, function (er, files) {
|
||||
// files is an array of filenames.
|
||||
// If the `nonull` option is set, and nothing
|
||||
// was found, then files is ["**/*.js"]
|
||||
// er is an error object or null.
|
||||
})
|
||||
```
|
||||
|
||||
## Glob Primer
|
||||
|
||||
"Globs" are the patterns you type when you do stuff like `ls *.js` on
|
||||
the command line, or put `build/*` in a `.gitignore` file.
|
||||
|
||||
Before parsing the path part patterns, braced sections are expanded
|
||||
into a set. Braced sections start with `{` and end with `}`, with any
|
||||
number of comma-delimited sections within. Braced sections may contain
|
||||
slash characters, so `a{/b/c,bcd}` would expand into `a/b/c` and `abcd`.
|
||||
|
||||
The following characters have special magic meaning when used in a
|
||||
path portion:
|
||||
|
||||
* `*` Matches 0 or more characters in a single path portion
|
||||
* `?` Matches 1 character
|
||||
* `[...]` Matches a range of characters, similar to a RegExp range.
|
||||
If the first character of the range is `!` or `^` then it matches
|
||||
any character not in the range.
|
||||
* `!(pattern|pattern|pattern)` Matches anything that does not match
|
||||
any of the patterns provided.
|
||||
* `?(pattern|pattern|pattern)` Matches zero or one occurrence of the
|
||||
patterns provided.
|
||||
* `+(pattern|pattern|pattern)` Matches one or more occurrences of the
|
||||
patterns provided.
|
||||
* `*(a|b|c)` Matches zero or more occurrences of the patterns provided
|
||||
* `@(pattern|pat*|pat?erN)` Matches exactly one of the patterns
|
||||
provided
|
||||
* `**` If a "globstar" is alone in a path portion, then it matches
|
||||
zero or more directories and subdirectories searching for matches.
|
||||
It does not crawl symlinked directories.
|
||||
|
||||
### Dots
|
||||
|
||||
If a file or directory path portion has a `.` as the first character,
|
||||
then it will not match any glob pattern unless that pattern's
|
||||
corresponding path part also has a `.` as its first character.
|
||||
|
||||
For example, the pattern `a/.*/c` would match the file at `a/.b/c`.
|
||||
However the pattern `a/*/c` would not, because `*` does not start with
|
||||
a dot character.
|
||||
|
||||
You can make glob treat dots as normal characters by setting
|
||||
`dot:true` in the options.
|
||||
|
||||
### Basename Matching
|
||||
|
||||
If you set `matchBase:true` in the options, and the pattern has no
|
||||
slashes in it, then it will seek for any file anywhere in the tree
|
||||
with a matching basename. For example, `*.js` would match
|
||||
`test/simple/basic.js`.
|
||||
|
||||
### Empty Sets
|
||||
|
||||
If no matching files are found, then an empty array is returned. This
|
||||
differs from the shell, where the pattern itself is returned. For
|
||||
example:
|
||||
|
||||
$ echo a*s*d*f
|
||||
a*s*d*f
|
||||
|
||||
To get the bash-style behavior, set the `nonull:true` in the options.
|
||||
|
||||
### See Also:
|
||||
|
||||
* `man sh`
|
||||
* `man bash` (Search for "Pattern Matching")
|
||||
* `man 3 fnmatch`
|
||||
* `man 5 gitignore`
|
||||
* [minimatch documentation](https://github.com/isaacs/minimatch)
|
||||
|
||||
## glob.hasMagic(pattern, [options])
|
||||
|
||||
Returns `true` if there are any special characters in the pattern, and
|
||||
`false` otherwise.
|
||||
|
||||
Note that the options affect the results. If `noext:true` is set in
|
||||
the options object, then `+(a|b)` will not be considered a magic
|
||||
pattern. If the pattern has a brace expansion, like `a/{b/c,x/y}`
|
||||
then that is considered magical, unless `nobrace:true` is set in the
|
||||
options.
|
||||
|
||||
## glob(pattern, [options], cb)
|
||||
|
||||
* `pattern` `{String}` Pattern to be matched
|
||||
* `options` `{Object}`
|
||||
* `cb` `{Function}`
|
||||
* `err` `{Error | null}`
|
||||
* `matches` `{Array<String>}` filenames found matching the pattern
|
||||
|
||||
Perform an asynchronous glob search.
|
||||
|
||||
## glob.sync(pattern, [options])
|
||||
|
||||
* `pattern` `{String}` Pattern to be matched
|
||||
* `options` `{Object}`
|
||||
* return: `{Array<String>}` filenames found matching the pattern
|
||||
|
||||
Perform a synchronous glob search.
|
||||
|
||||
## Class: glob.Glob
|
||||
|
||||
Create a Glob object by instantiating the `glob.Glob` class.
|
||||
|
||||
```javascript
|
||||
var Glob = require("glob").Glob
|
||||
var mg = new Glob(pattern, options, cb)
|
||||
```
|
||||
|
||||
It's an EventEmitter, and starts walking the filesystem to find matches
|
||||
immediately.
|
||||
|
||||
### new glob.Glob(pattern, [options], [cb])
|
||||
|
||||
* `pattern` `{String}` pattern to search for
|
||||
* `options` `{Object}`
|
||||
* `cb` `{Function}` Called when an error occurs, or matches are found
|
||||
* `err` `{Error | null}`
|
||||
* `matches` `{Array<String>}` filenames found matching the pattern
|
||||
|
||||
Note that if the `sync` flag is set in the options, then matches will
|
||||
be immediately available on the `g.found` member.
|
||||
|
||||
### Properties
|
||||
|
||||
* `minimatch` The minimatch object that the glob uses.
|
||||
* `options` The options object passed in.
|
||||
* `aborted` Boolean which is set to true when calling `abort()`. There
|
||||
is no way at this time to continue a glob search after aborting, but
|
||||
you can re-use the statCache to avoid having to duplicate syscalls.
|
||||
* `cache` Convenience object. Each field has the following possible
|
||||
values:
|
||||
* `false` - Path does not exist
|
||||
* `true` - Path exists
|
||||
* `'FILE'` - Path exists, and is not a directory
|
||||
* `'DIR'` - Path exists, and is a directory
|
||||
* `[file, entries, ...]` - Path exists, is a directory, and the
|
||||
array value is the results of `fs.readdir`
|
||||
* `statCache` Cache of `fs.stat` results, to prevent statting the same
|
||||
path multiple times.
|
||||
* `symlinks` A record of which paths are symbolic links, which is
|
||||
relevant in resolving `**` patterns.
|
||||
* `realpathCache` An optional object which is passed to `fs.realpath`
|
||||
to minimize unnecessary syscalls. It is stored on the instantiated
|
||||
Glob object, and may be re-used.
|
||||
|
||||
### Events
|
||||
|
||||
* `end` When the matching is finished, this is emitted with all the
|
||||
matches found. If the `nonull` option is set, and no match was found,
|
||||
then the `matches` list contains the original pattern. The matches
|
||||
are sorted, unless the `nosort` flag is set.
|
||||
* `match` Every time a match is found, this is emitted with the specific
|
||||
thing that matched. It is not deduplicated or resolved to a realpath.
|
||||
* `error` Emitted when an unexpected error is encountered, or whenever
|
||||
any fs error occurs if `options.strict` is set.
|
||||
* `abort` When `abort()` is called, this event is raised.
|
||||
|
||||
### Methods
|
||||
|
||||
* `pause` Temporarily stop the search
|
||||
* `resume` Resume the search
|
||||
* `abort` Stop the search forever
|
||||
|
||||
### Options
|
||||
|
||||
All the options that can be passed to Minimatch can also be passed to
|
||||
Glob to change pattern matching behavior. Also, some have been added,
|
||||
or have glob-specific ramifications.
|
||||
|
||||
All options are false by default, unless otherwise noted.
|
||||
|
||||
All options are added to the Glob object, as well.
|
||||
|
||||
If you are running many `glob` operations, you can pass a Glob object
|
||||
as the `options` argument to a subsequent operation to shortcut some
|
||||
`stat` and `readdir` calls. At the very least, you may pass in shared
|
||||
`symlinks`, `statCache`, `realpathCache`, and `cache` options, so that
|
||||
parallel glob operations will be sped up by sharing information about
|
||||
the filesystem.
|
||||
|
||||
* `cwd` The current working directory in which to search. Defaults
|
||||
to `process.cwd()`.
|
||||
* `root` The place where patterns starting with `/` will be mounted
|
||||
onto. Defaults to `path.resolve(options.cwd, "/")` (`/` on Unix
|
||||
systems, and `C:\` or some such on Windows.)
|
||||
* `dot` Include `.dot` files in normal matches and `globstar` matches.
|
||||
Note that an explicit dot in a portion of the pattern will always
|
||||
match dot files.
|
||||
* `nomount` By default, a pattern starting with a forward-slash will be
|
||||
"mounted" onto the root setting, so that a valid filesystem path is
|
||||
returned. Set this flag to disable that behavior.
|
||||
* `mark` Add a `/` character to directory matches. Note that this
|
||||
requires additional stat calls.
|
||||
* `nosort` Don't sort the results.
|
||||
* `stat` Set to true to stat *all* results. This reduces performance
|
||||
somewhat, and is completely unnecessary, unless `readdir` is presumed
|
||||
to be an untrustworthy indicator of file existence.
|
||||
* `silent` When an unusual error is encountered when attempting to
|
||||
read a directory, a warning will be printed to stderr. Set the
|
||||
`silent` option to true to suppress these warnings.
|
||||
* `strict` When an unusual error is encountered when attempting to
|
||||
read a directory, the process will just continue on in search of
|
||||
other matches. Set the `strict` option to raise an error in these
|
||||
cases.
|
||||
* `cache` See `cache` property above. Pass in a previously generated
|
||||
cache object to save some fs calls.
|
||||
* `statCache` A cache of results of filesystem information, to prevent
|
||||
unnecessary stat calls. While it should not normally be necessary
|
||||
to set this, you may pass the statCache from one glob() call to the
|
||||
options object of another, if you know that the filesystem will not
|
||||
change between calls. (See "Race Conditions" below.)
|
||||
* `symlinks` A cache of known symbolic links. You may pass in a
|
||||
previously generated `symlinks` object to save `lstat` calls when
|
||||
resolving `**` matches.
|
||||
* `sync` DEPRECATED: use `glob.sync(pattern, opts)` instead.
|
||||
* `nounique` In some cases, brace-expanded patterns can result in the
|
||||
same file showing up multiple times in the result set. By default,
|
||||
this implementation prevents duplicates in the result set. Set this
|
||||
flag to disable that behavior.
|
||||
* `nonull` Set to never return an empty set, instead returning a set
|
||||
containing the pattern itself. This is the default in glob(3).
|
||||
* `debug` Set to enable debug logging in minimatch and glob.
|
||||
* `nobrace` Do not expand `{a,b}` and `{1..3}` brace sets.
|
||||
* `noglobstar` Do not match `**` against multiple filenames. (Ie,
|
||||
treat it as a normal `*` instead.)
|
||||
* `noext` Do not match `+(a|b)` "extglob" patterns.
|
||||
* `nocase` Perform a case-insensitive match. Note: on
|
||||
case-insensitive filesystems, non-magic patterns will match by
|
||||
default, since `stat` and `readdir` will not raise errors.
|
||||
* `matchBase` Perform a basename-only match if the pattern does not
|
||||
contain any slash characters. That is, `*.js` would be treated as
|
||||
equivalent to `**/*.js`, matching all js files in all directories.
|
||||
* `nodir` Do not match directories, only files. (Note: to match
|
||||
*only* directories, simply put a `/` at the end of the pattern.)
|
||||
* `ignore` Add a pattern or an array of glob patterns to exclude matches.
|
||||
Note: `ignore` patterns are *always* in `dot:true` mode, regardless
|
||||
of any other settings.
|
||||
* `follow` Follow symlinked directories when expanding `**` patterns.
|
||||
Note that this can result in a lot of duplicate references in the
|
||||
presence of cyclic links.
|
||||
* `realpath` Set to true to call `fs.realpath` on all of the results.
|
||||
In the case of a symlink that cannot be resolved, the full absolute
|
||||
path to the matched entry is returned (though it will usually be a
|
||||
broken symlink)
|
||||
* `absolute` Set to true to always receive absolute paths for matched
|
||||
files. Unlike `realpath`, this also affects the values returned in
|
||||
the `match` event.
|
||||
* `fs` File-system object with Node's `fs` API. By default, the built-in
|
||||
`fs` module will be used. Set to a volume provided by a library like
|
||||
`memfs` to avoid using the "real" file-system.
|
||||
|
||||
## Comparisons to other fnmatch/glob implementations
|
||||
|
||||
While strict compliance with the existing standards is a worthwhile
|
||||
goal, some discrepancies exist between node-glob and other
|
||||
implementations, and are intentional.
|
||||
|
||||
The double-star character `**` is supported by default, unless the
|
||||
`noglobstar` flag is set. This is supported in the manner of bsdglob
|
||||
and bash 4.3, where `**` only has special significance if it is the only
|
||||
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
|
||||
`a/**b` will not.
|
||||
|
||||
Note that symlinked directories are not crawled as part of a `**`,
|
||||
though their contents may match against subsequent portions of the
|
||||
pattern. This prevents infinite loops and duplicates and the like.
|
||||
|
||||
If an escaped pattern has no matches, and the `nonull` flag is set,
|
||||
then glob returns the pattern as-provided, rather than
|
||||
interpreting the character escapes. For example,
|
||||
`glob.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
|
||||
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
|
||||
that it does not resolve escaped pattern characters.
|
||||
|
||||
If brace expansion is not disabled, then it is performed before any
|
||||
other interpretation of the glob pattern. Thus, a pattern like
|
||||
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
|
||||
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
|
||||
checked for validity. Since those two are valid, matching proceeds.
|
||||
|
||||
### Comments and Negation
|
||||
|
||||
Previously, this module let you mark a pattern as a "comment" if it
|
||||
started with a `#` character, or a "negated" pattern if it started
|
||||
with a `!` character.
|
||||
|
||||
These options were deprecated in version 5, and removed in version 6.
|
||||
|
||||
To specify things that should not match, use the `ignore` option.
|
||||
|
||||
## Windows
|
||||
|
||||
**Please only use forward-slashes in glob expressions.**
|
||||
|
||||
Though windows uses either `/` or `\` as its path separator, only `/`
|
||||
characters are used by this glob implementation. You must use
|
||||
forward-slashes **only** in glob expressions. Back-slashes will always
|
||||
be interpreted as escape characters, not path separators.
|
||||
|
||||
Results from absolute patterns such as `/foo/*` are mounted onto the
|
||||
root setting using `path.join`. On windows, this will by default result
|
||||
in `/foo/*` matching `C:\foo\bar.txt`.
|
||||
|
||||
## Race Conditions
|
||||
|
||||
Glob searching, by its very nature, is susceptible to race conditions,
|
||||
since it relies on directory walking and such.
|
||||
|
||||
As a result, it is possible that a file that exists when glob looks for
|
||||
it may have been deleted or modified by the time it returns the result.
|
||||
|
||||
As part of its internal implementation, this program caches all stat
|
||||
and readdir calls that it makes, in order to cut down on system
|
||||
overhead. However, this also makes it even more susceptible to races,
|
||||
especially if the cache or statCache objects are reused between glob
|
||||
calls.
|
||||
|
||||
Users are thus advised not to use a glob result as a guarantee of
|
||||
filesystem state in the face of rapid changes. For the vast majority
|
||||
of operations, this is never a problem.
|
||||
|
||||
## Glob Logo
|
||||
Glob's logo was created by [Tanya Brassie](http://tanyabrassie.com/). Logo files can be found [here](https://github.com/isaacs/node-glob/tree/master/logo).
|
||||
|
||||
The logo is licensed under a [Creative Commons Attribution-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-sa/4.0/).
|
||||
|
||||
## Contributing
|
||||
|
||||
Any change to behavior (including bugfixes) must come with a test.
|
||||
|
||||
Patches that fail tests or reduce performance will be rejected.
|
||||
|
||||
```
|
||||
# to run tests
|
||||
npm test
|
||||
|
||||
# to re-generate test fixtures
|
||||
npm run test-regen
|
||||
|
||||
# to benchmark against bash/zsh
|
||||
npm run bench
|
||||
|
||||
# to profile javascript
|
||||
npm run prof
|
||||
```
|
||||
|
||||

|
||||
238
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/common.js
generated
vendored
Normal file
238
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/common.js
generated
vendored
Normal file
|
|
@ -0,0 +1,238 @@
|
|||
exports.setopts = setopts
|
||||
exports.ownProp = ownProp
|
||||
exports.makeAbs = makeAbs
|
||||
exports.finish = finish
|
||||
exports.mark = mark
|
||||
exports.isIgnored = isIgnored
|
||||
exports.childrenIgnored = childrenIgnored
|
||||
|
||||
function ownProp (obj, field) {
|
||||
return Object.prototype.hasOwnProperty.call(obj, field)
|
||||
}
|
||||
|
||||
var fs = require("fs")
|
||||
var path = require("path")
|
||||
var minimatch = require("minimatch")
|
||||
var isAbsolute = require("path-is-absolute")
|
||||
var Minimatch = minimatch.Minimatch
|
||||
|
||||
function alphasort (a, b) {
|
||||
return a.localeCompare(b, 'en')
|
||||
}
|
||||
|
||||
function setupIgnores (self, options) {
|
||||
self.ignore = options.ignore || []
|
||||
|
||||
if (!Array.isArray(self.ignore))
|
||||
self.ignore = [self.ignore]
|
||||
|
||||
if (self.ignore.length) {
|
||||
self.ignore = self.ignore.map(ignoreMap)
|
||||
}
|
||||
}
|
||||
|
||||
// ignore patterns are always in dot:true mode.
|
||||
function ignoreMap (pattern) {
|
||||
var gmatcher = null
|
||||
if (pattern.slice(-3) === '/**') {
|
||||
var gpattern = pattern.replace(/(\/\*\*)+$/, '')
|
||||
gmatcher = new Minimatch(gpattern, { dot: true })
|
||||
}
|
||||
|
||||
return {
|
||||
matcher: new Minimatch(pattern, { dot: true }),
|
||||
gmatcher: gmatcher
|
||||
}
|
||||
}
|
||||
|
||||
function setopts (self, pattern, options) {
|
||||
if (!options)
|
||||
options = {}
|
||||
|
||||
// base-matching: just use globstar for that.
|
||||
if (options.matchBase && -1 === pattern.indexOf("/")) {
|
||||
if (options.noglobstar) {
|
||||
throw new Error("base matching requires globstar")
|
||||
}
|
||||
pattern = "**/" + pattern
|
||||
}
|
||||
|
||||
self.silent = !!options.silent
|
||||
self.pattern = pattern
|
||||
self.strict = options.strict !== false
|
||||
self.realpath = !!options.realpath
|
||||
self.realpathCache = options.realpathCache || Object.create(null)
|
||||
self.follow = !!options.follow
|
||||
self.dot = !!options.dot
|
||||
self.mark = !!options.mark
|
||||
self.nodir = !!options.nodir
|
||||
if (self.nodir)
|
||||
self.mark = true
|
||||
self.sync = !!options.sync
|
||||
self.nounique = !!options.nounique
|
||||
self.nonull = !!options.nonull
|
||||
self.nosort = !!options.nosort
|
||||
self.nocase = !!options.nocase
|
||||
self.stat = !!options.stat
|
||||
self.noprocess = !!options.noprocess
|
||||
self.absolute = !!options.absolute
|
||||
self.fs = options.fs || fs
|
||||
|
||||
self.maxLength = options.maxLength || Infinity
|
||||
self.cache = options.cache || Object.create(null)
|
||||
self.statCache = options.statCache || Object.create(null)
|
||||
self.symlinks = options.symlinks || Object.create(null)
|
||||
|
||||
setupIgnores(self, options)
|
||||
|
||||
self.changedCwd = false
|
||||
var cwd = process.cwd()
|
||||
if (!ownProp(options, "cwd"))
|
||||
self.cwd = cwd
|
||||
else {
|
||||
self.cwd = path.resolve(options.cwd)
|
||||
self.changedCwd = self.cwd !== cwd
|
||||
}
|
||||
|
||||
self.root = options.root || path.resolve(self.cwd, "/")
|
||||
self.root = path.resolve(self.root)
|
||||
if (process.platform === "win32")
|
||||
self.root = self.root.replace(/\\/g, "/")
|
||||
|
||||
// TODO: is an absolute `cwd` supposed to be resolved against `root`?
|
||||
// e.g. { cwd: '/test', root: __dirname } === path.join(__dirname, '/test')
|
||||
self.cwdAbs = isAbsolute(self.cwd) ? self.cwd : makeAbs(self, self.cwd)
|
||||
if (process.platform === "win32")
|
||||
self.cwdAbs = self.cwdAbs.replace(/\\/g, "/")
|
||||
self.nomount = !!options.nomount
|
||||
|
||||
// disable comments and negation in Minimatch.
|
||||
// Note that they are not supported in Glob itself anyway.
|
||||
options.nonegate = true
|
||||
options.nocomment = true
|
||||
// always treat \ in patterns as escapes, not path separators
|
||||
options.allowWindowsEscape = false
|
||||
|
||||
self.minimatch = new Minimatch(pattern, options)
|
||||
self.options = self.minimatch.options
|
||||
}
|
||||
|
||||
function finish (self) {
|
||||
var nou = self.nounique
|
||||
var all = nou ? [] : Object.create(null)
|
||||
|
||||
for (var i = 0, l = self.matches.length; i < l; i ++) {
|
||||
var matches = self.matches[i]
|
||||
if (!matches || Object.keys(matches).length === 0) {
|
||||
if (self.nonull) {
|
||||
// do like the shell, and spit out the literal glob
|
||||
var literal = self.minimatch.globSet[i]
|
||||
if (nou)
|
||||
all.push(literal)
|
||||
else
|
||||
all[literal] = true
|
||||
}
|
||||
} else {
|
||||
// had matches
|
||||
var m = Object.keys(matches)
|
||||
if (nou)
|
||||
all.push.apply(all, m)
|
||||
else
|
||||
m.forEach(function (m) {
|
||||
all[m] = true
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
if (!nou)
|
||||
all = Object.keys(all)
|
||||
|
||||
if (!self.nosort)
|
||||
all = all.sort(alphasort)
|
||||
|
||||
// at *some* point we statted all of these
|
||||
if (self.mark) {
|
||||
for (var i = 0; i < all.length; i++) {
|
||||
all[i] = self._mark(all[i])
|
||||
}
|
||||
if (self.nodir) {
|
||||
all = all.filter(function (e) {
|
||||
var notDir = !(/\/$/.test(e))
|
||||
var c = self.cache[e] || self.cache[makeAbs(self, e)]
|
||||
if (notDir && c)
|
||||
notDir = c !== 'DIR' && !Array.isArray(c)
|
||||
return notDir
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
if (self.ignore.length)
|
||||
all = all.filter(function(m) {
|
||||
return !isIgnored(self, m)
|
||||
})
|
||||
|
||||
self.found = all
|
||||
}
|
||||
|
||||
function mark (self, p) {
|
||||
var abs = makeAbs(self, p)
|
||||
var c = self.cache[abs]
|
||||
var m = p
|
||||
if (c) {
|
||||
var isDir = c === 'DIR' || Array.isArray(c)
|
||||
var slash = p.slice(-1) === '/'
|
||||
|
||||
if (isDir && !slash)
|
||||
m += '/'
|
||||
else if (!isDir && slash)
|
||||
m = m.slice(0, -1)
|
||||
|
||||
if (m !== p) {
|
||||
var mabs = makeAbs(self, m)
|
||||
self.statCache[mabs] = self.statCache[abs]
|
||||
self.cache[mabs] = self.cache[abs]
|
||||
}
|
||||
}
|
||||
|
||||
return m
|
||||
}
|
||||
|
||||
// lotta situps...
|
||||
function makeAbs (self, f) {
|
||||
var abs = f
|
||||
if (f.charAt(0) === '/') {
|
||||
abs = path.join(self.root, f)
|
||||
} else if (isAbsolute(f) || f === '') {
|
||||
abs = f
|
||||
} else if (self.changedCwd) {
|
||||
abs = path.resolve(self.cwd, f)
|
||||
} else {
|
||||
abs = path.resolve(f)
|
||||
}
|
||||
|
||||
if (process.platform === 'win32')
|
||||
abs = abs.replace(/\\/g, '/')
|
||||
|
||||
return abs
|
||||
}
|
||||
|
||||
|
||||
// Return true, if pattern ends with globstar '**', for the accompanying parent directory.
|
||||
// Ex:- If node_modules/** is the pattern, add 'node_modules' to ignore list along with it's contents
|
||||
function isIgnored (self, path) {
|
||||
if (!self.ignore.length)
|
||||
return false
|
||||
|
||||
return self.ignore.some(function(item) {
|
||||
return item.matcher.match(path) || !!(item.gmatcher && item.gmatcher.match(path))
|
||||
})
|
||||
}
|
||||
|
||||
function childrenIgnored (self, path) {
|
||||
if (!self.ignore.length)
|
||||
return false
|
||||
|
||||
return self.ignore.some(function(item) {
|
||||
return !!(item.gmatcher && item.gmatcher.match(path))
|
||||
})
|
||||
}
|
||||
790
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/glob.js
generated
vendored
Normal file
790
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/glob.js
generated
vendored
Normal file
|
|
@ -0,0 +1,790 @@
|
|||
// Approach:
|
||||
//
|
||||
// 1. Get the minimatch set
|
||||
// 2. For each pattern in the set, PROCESS(pattern, false)
|
||||
// 3. Store matches per-set, then uniq them
|
||||
//
|
||||
// PROCESS(pattern, inGlobStar)
|
||||
// Get the first [n] items from pattern that are all strings
|
||||
// Join these together. This is PREFIX.
|
||||
// If there is no more remaining, then stat(PREFIX) and
|
||||
// add to matches if it succeeds. END.
|
||||
//
|
||||
// If inGlobStar and PREFIX is symlink and points to dir
|
||||
// set ENTRIES = []
|
||||
// else readdir(PREFIX) as ENTRIES
|
||||
// If fail, END
|
||||
//
|
||||
// with ENTRIES
|
||||
// If pattern[n] is GLOBSTAR
|
||||
// // handle the case where the globstar match is empty
|
||||
// // by pruning it out, and testing the resulting pattern
|
||||
// PROCESS(pattern[0..n] + pattern[n+1 .. $], false)
|
||||
// // handle other cases.
|
||||
// for ENTRY in ENTRIES (not dotfiles)
|
||||
// // attach globstar + tail onto the entry
|
||||
// // Mark that this entry is a globstar match
|
||||
// PROCESS(pattern[0..n] + ENTRY + pattern[n .. $], true)
|
||||
//
|
||||
// else // not globstar
|
||||
// for ENTRY in ENTRIES (not dotfiles, unless pattern[n] is dot)
|
||||
// Test ENTRY against pattern[n]
|
||||
// If fails, continue
|
||||
// If passes, PROCESS(pattern[0..n] + item + pattern[n+1 .. $])
|
||||
//
|
||||
// Caveat:
|
||||
// Cache all stats and readdirs results to minimize syscall. Since all
|
||||
// we ever care about is existence and directory-ness, we can just keep
|
||||
// `true` for files, and [children,...] for directories, or `false` for
|
||||
// things that don't exist.
|
||||
|
||||
module.exports = glob
|
||||
|
||||
var rp = require('fs.realpath')
|
||||
var minimatch = require('minimatch')
|
||||
var Minimatch = minimatch.Minimatch
|
||||
var inherits = require('inherits')
|
||||
var EE = require('events').EventEmitter
|
||||
var path = require('path')
|
||||
var assert = require('assert')
|
||||
var isAbsolute = require('path-is-absolute')
|
||||
var globSync = require('./sync.js')
|
||||
var common = require('./common.js')
|
||||
var setopts = common.setopts
|
||||
var ownProp = common.ownProp
|
||||
var inflight = require('inflight')
|
||||
var util = require('util')
|
||||
var childrenIgnored = common.childrenIgnored
|
||||
var isIgnored = common.isIgnored
|
||||
|
||||
var once = require('once')
|
||||
|
||||
function glob (pattern, options, cb) {
|
||||
if (typeof options === 'function') cb = options, options = {}
|
||||
if (!options) options = {}
|
||||
|
||||
if (options.sync) {
|
||||
if (cb)
|
||||
throw new TypeError('callback provided to sync glob')
|
||||
return globSync(pattern, options)
|
||||
}
|
||||
|
||||
return new Glob(pattern, options, cb)
|
||||
}
|
||||
|
||||
glob.sync = globSync
|
||||
var GlobSync = glob.GlobSync = globSync.GlobSync
|
||||
|
||||
// old api surface
|
||||
glob.glob = glob
|
||||
|
||||
function extend (origin, add) {
|
||||
if (add === null || typeof add !== 'object') {
|
||||
return origin
|
||||
}
|
||||
|
||||
var keys = Object.keys(add)
|
||||
var i = keys.length
|
||||
while (i--) {
|
||||
origin[keys[i]] = add[keys[i]]
|
||||
}
|
||||
return origin
|
||||
}
|
||||
|
||||
glob.hasMagic = function (pattern, options_) {
|
||||
var options = extend({}, options_)
|
||||
options.noprocess = true
|
||||
|
||||
var g = new Glob(pattern, options)
|
||||
var set = g.minimatch.set
|
||||
|
||||
if (!pattern)
|
||||
return false
|
||||
|
||||
if (set.length > 1)
|
||||
return true
|
||||
|
||||
for (var j = 0; j < set[0].length; j++) {
|
||||
if (typeof set[0][j] !== 'string')
|
||||
return true
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
glob.Glob = Glob
|
||||
inherits(Glob, EE)
|
||||
function Glob (pattern, options, cb) {
|
||||
if (typeof options === 'function') {
|
||||
cb = options
|
||||
options = null
|
||||
}
|
||||
|
||||
if (options && options.sync) {
|
||||
if (cb)
|
||||
throw new TypeError('callback provided to sync glob')
|
||||
return new GlobSync(pattern, options)
|
||||
}
|
||||
|
||||
if (!(this instanceof Glob))
|
||||
return new Glob(pattern, options, cb)
|
||||
|
||||
setopts(this, pattern, options)
|
||||
this._didRealPath = false
|
||||
|
||||
// process each pattern in the minimatch set
|
||||
var n = this.minimatch.set.length
|
||||
|
||||
// The matches are stored as {<filename>: true,...} so that
|
||||
// duplicates are automagically pruned.
|
||||
// Later, we do an Object.keys() on these.
|
||||
// Keep them as a list so we can fill in when nonull is set.
|
||||
this.matches = new Array(n)
|
||||
|
||||
if (typeof cb === 'function') {
|
||||
cb = once(cb)
|
||||
this.on('error', cb)
|
||||
this.on('end', function (matches) {
|
||||
cb(null, matches)
|
||||
})
|
||||
}
|
||||
|
||||
var self = this
|
||||
this._processing = 0
|
||||
|
||||
this._emitQueue = []
|
||||
this._processQueue = []
|
||||
this.paused = false
|
||||
|
||||
if (this.noprocess)
|
||||
return this
|
||||
|
||||
if (n === 0)
|
||||
return done()
|
||||
|
||||
var sync = true
|
||||
for (var i = 0; i < n; i ++) {
|
||||
this._process(this.minimatch.set[i], i, false, done)
|
||||
}
|
||||
sync = false
|
||||
|
||||
function done () {
|
||||
--self._processing
|
||||
if (self._processing <= 0) {
|
||||
if (sync) {
|
||||
process.nextTick(function () {
|
||||
self._finish()
|
||||
})
|
||||
} else {
|
||||
self._finish()
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._finish = function () {
|
||||
assert(this instanceof Glob)
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
if (this.realpath && !this._didRealpath)
|
||||
return this._realpath()
|
||||
|
||||
common.finish(this)
|
||||
this.emit('end', this.found)
|
||||
}
|
||||
|
||||
Glob.prototype._realpath = function () {
|
||||
if (this._didRealpath)
|
||||
return
|
||||
|
||||
this._didRealpath = true
|
||||
|
||||
var n = this.matches.length
|
||||
if (n === 0)
|
||||
return this._finish()
|
||||
|
||||
var self = this
|
||||
for (var i = 0; i < this.matches.length; i++)
|
||||
this._realpathSet(i, next)
|
||||
|
||||
function next () {
|
||||
if (--n === 0)
|
||||
self._finish()
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._realpathSet = function (index, cb) {
|
||||
var matchset = this.matches[index]
|
||||
if (!matchset)
|
||||
return cb()
|
||||
|
||||
var found = Object.keys(matchset)
|
||||
var self = this
|
||||
var n = found.length
|
||||
|
||||
if (n === 0)
|
||||
return cb()
|
||||
|
||||
var set = this.matches[index] = Object.create(null)
|
||||
found.forEach(function (p, i) {
|
||||
// If there's a problem with the stat, then it means that
|
||||
// one or more of the links in the realpath couldn't be
|
||||
// resolved. just return the abs value in that case.
|
||||
p = self._makeAbs(p)
|
||||
rp.realpath(p, self.realpathCache, function (er, real) {
|
||||
if (!er)
|
||||
set[real] = true
|
||||
else if (er.syscall === 'stat')
|
||||
set[p] = true
|
||||
else
|
||||
self.emit('error', er) // srsly wtf right here
|
||||
|
||||
if (--n === 0) {
|
||||
self.matches[index] = set
|
||||
cb()
|
||||
}
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
Glob.prototype._mark = function (p) {
|
||||
return common.mark(this, p)
|
||||
}
|
||||
|
||||
Glob.prototype._makeAbs = function (f) {
|
||||
return common.makeAbs(this, f)
|
||||
}
|
||||
|
||||
Glob.prototype.abort = function () {
|
||||
this.aborted = true
|
||||
this.emit('abort')
|
||||
}
|
||||
|
||||
Glob.prototype.pause = function () {
|
||||
if (!this.paused) {
|
||||
this.paused = true
|
||||
this.emit('pause')
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype.resume = function () {
|
||||
if (this.paused) {
|
||||
this.emit('resume')
|
||||
this.paused = false
|
||||
if (this._emitQueue.length) {
|
||||
var eq = this._emitQueue.slice(0)
|
||||
this._emitQueue.length = 0
|
||||
for (var i = 0; i < eq.length; i ++) {
|
||||
var e = eq[i]
|
||||
this._emitMatch(e[0], e[1])
|
||||
}
|
||||
}
|
||||
if (this._processQueue.length) {
|
||||
var pq = this._processQueue.slice(0)
|
||||
this._processQueue.length = 0
|
||||
for (var i = 0; i < pq.length; i ++) {
|
||||
var p = pq[i]
|
||||
this._processing--
|
||||
this._process(p[0], p[1], p[2], p[3])
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._process = function (pattern, index, inGlobStar, cb) {
|
||||
assert(this instanceof Glob)
|
||||
assert(typeof cb === 'function')
|
||||
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
this._processing++
|
||||
if (this.paused) {
|
||||
this._processQueue.push([pattern, index, inGlobStar, cb])
|
||||
return
|
||||
}
|
||||
|
||||
//console.error('PROCESS %d', this._processing, pattern)
|
||||
|
||||
// Get the first [n] parts of pattern that are all strings.
|
||||
var n = 0
|
||||
while (typeof pattern[n] === 'string') {
|
||||
n ++
|
||||
}
|
||||
// now n is the index of the first one that is *not* a string.
|
||||
|
||||
// see if there's anything else
|
||||
var prefix
|
||||
switch (n) {
|
||||
// if not, then this is rather simple
|
||||
case pattern.length:
|
||||
this._processSimple(pattern.join('/'), index, cb)
|
||||
return
|
||||
|
||||
case 0:
|
||||
// pattern *starts* with some non-trivial item.
|
||||
// going to readdir(cwd), but not include the prefix in matches.
|
||||
prefix = null
|
||||
break
|
||||
|
||||
default:
|
||||
// pattern has some string bits in the front.
|
||||
// whatever it starts with, whether that's 'absolute' like /foo/bar,
|
||||
// or 'relative' like '../baz'
|
||||
prefix = pattern.slice(0, n).join('/')
|
||||
break
|
||||
}
|
||||
|
||||
var remain = pattern.slice(n)
|
||||
|
||||
// get the list of entries.
|
||||
var read
|
||||
if (prefix === null)
|
||||
read = '.'
|
||||
else if (isAbsolute(prefix) ||
|
||||
isAbsolute(pattern.map(function (p) {
|
||||
return typeof p === 'string' ? p : '[*]'
|
||||
}).join('/'))) {
|
||||
if (!prefix || !isAbsolute(prefix))
|
||||
prefix = '/' + prefix
|
||||
read = prefix
|
||||
} else
|
||||
read = prefix
|
||||
|
||||
var abs = this._makeAbs(read)
|
||||
|
||||
//if ignored, skip _processing
|
||||
if (childrenIgnored(this, read))
|
||||
return cb()
|
||||
|
||||
var isGlobStar = remain[0] === minimatch.GLOBSTAR
|
||||
if (isGlobStar)
|
||||
this._processGlobStar(prefix, read, abs, remain, index, inGlobStar, cb)
|
||||
else
|
||||
this._processReaddir(prefix, read, abs, remain, index, inGlobStar, cb)
|
||||
}
|
||||
|
||||
Glob.prototype._processReaddir = function (prefix, read, abs, remain, index, inGlobStar, cb) {
|
||||
var self = this
|
||||
this._readdir(abs, inGlobStar, function (er, entries) {
|
||||
return self._processReaddir2(prefix, read, abs, remain, index, inGlobStar, entries, cb)
|
||||
})
|
||||
}
|
||||
|
||||
Glob.prototype._processReaddir2 = function (prefix, read, abs, remain, index, inGlobStar, entries, cb) {
|
||||
|
||||
// if the abs isn't a dir, then nothing can match!
|
||||
if (!entries)
|
||||
return cb()
|
||||
|
||||
// It will only match dot entries if it starts with a dot, or if
|
||||
// dot is set. Stuff like @(.foo|.bar) isn't allowed.
|
||||
var pn = remain[0]
|
||||
var negate = !!this.minimatch.negate
|
||||
var rawGlob = pn._glob
|
||||
var dotOk = this.dot || rawGlob.charAt(0) === '.'
|
||||
|
||||
var matchedEntries = []
|
||||
for (var i = 0; i < entries.length; i++) {
|
||||
var e = entries[i]
|
||||
if (e.charAt(0) !== '.' || dotOk) {
|
||||
var m
|
||||
if (negate && !prefix) {
|
||||
m = !e.match(pn)
|
||||
} else {
|
||||
m = e.match(pn)
|
||||
}
|
||||
if (m)
|
||||
matchedEntries.push(e)
|
||||
}
|
||||
}
|
||||
|
||||
//console.error('prd2', prefix, entries, remain[0]._glob, matchedEntries)
|
||||
|
||||
var len = matchedEntries.length
|
||||
// If there are no matched entries, then nothing matches.
|
||||
if (len === 0)
|
||||
return cb()
|
||||
|
||||
// if this is the last remaining pattern bit, then no need for
|
||||
// an additional stat *unless* the user has specified mark or
|
||||
// stat explicitly. We know they exist, since readdir returned
|
||||
// them.
|
||||
|
||||
if (remain.length === 1 && !this.mark && !this.stat) {
|
||||
if (!this.matches[index])
|
||||
this.matches[index] = Object.create(null)
|
||||
|
||||
for (var i = 0; i < len; i ++) {
|
||||
var e = matchedEntries[i]
|
||||
if (prefix) {
|
||||
if (prefix !== '/')
|
||||
e = prefix + '/' + e
|
||||
else
|
||||
e = prefix + e
|
||||
}
|
||||
|
||||
if (e.charAt(0) === '/' && !this.nomount) {
|
||||
e = path.join(this.root, e)
|
||||
}
|
||||
this._emitMatch(index, e)
|
||||
}
|
||||
// This was the last one, and no stats were needed
|
||||
return cb()
|
||||
}
|
||||
|
||||
// now test all matched entries as stand-ins for that part
|
||||
// of the pattern.
|
||||
remain.shift()
|
||||
for (var i = 0; i < len; i ++) {
|
||||
var e = matchedEntries[i]
|
||||
var newPattern
|
||||
if (prefix) {
|
||||
if (prefix !== '/')
|
||||
e = prefix + '/' + e
|
||||
else
|
||||
e = prefix + e
|
||||
}
|
||||
this._process([e].concat(remain), index, inGlobStar, cb)
|
||||
}
|
||||
cb()
|
||||
}
|
||||
|
||||
Glob.prototype._emitMatch = function (index, e) {
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
if (isIgnored(this, e))
|
||||
return
|
||||
|
||||
if (this.paused) {
|
||||
this._emitQueue.push([index, e])
|
||||
return
|
||||
}
|
||||
|
||||
var abs = isAbsolute(e) ? e : this._makeAbs(e)
|
||||
|
||||
if (this.mark)
|
||||
e = this._mark(e)
|
||||
|
||||
if (this.absolute)
|
||||
e = abs
|
||||
|
||||
if (this.matches[index][e])
|
||||
return
|
||||
|
||||
if (this.nodir) {
|
||||
var c = this.cache[abs]
|
||||
if (c === 'DIR' || Array.isArray(c))
|
||||
return
|
||||
}
|
||||
|
||||
this.matches[index][e] = true
|
||||
|
||||
var st = this.statCache[abs]
|
||||
if (st)
|
||||
this.emit('stat', e, st)
|
||||
|
||||
this.emit('match', e)
|
||||
}
|
||||
|
||||
Glob.prototype._readdirInGlobStar = function (abs, cb) {
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
// follow all symlinked directories forever
|
||||
// just proceed as if this is a non-globstar situation
|
||||
if (this.follow)
|
||||
return this._readdir(abs, false, cb)
|
||||
|
||||
var lstatkey = 'lstat\0' + abs
|
||||
var self = this
|
||||
var lstatcb = inflight(lstatkey, lstatcb_)
|
||||
|
||||
if (lstatcb)
|
||||
self.fs.lstat(abs, lstatcb)
|
||||
|
||||
function lstatcb_ (er, lstat) {
|
||||
if (er && er.code === 'ENOENT')
|
||||
return cb()
|
||||
|
||||
var isSym = lstat && lstat.isSymbolicLink()
|
||||
self.symlinks[abs] = isSym
|
||||
|
||||
// If it's not a symlink or a dir, then it's definitely a regular file.
|
||||
// don't bother doing a readdir in that case.
|
||||
if (!isSym && lstat && !lstat.isDirectory()) {
|
||||
self.cache[abs] = 'FILE'
|
||||
cb()
|
||||
} else
|
||||
self._readdir(abs, false, cb)
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._readdir = function (abs, inGlobStar, cb) {
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
cb = inflight('readdir\0'+abs+'\0'+inGlobStar, cb)
|
||||
if (!cb)
|
||||
return
|
||||
|
||||
//console.error('RD %j %j', +inGlobStar, abs)
|
||||
if (inGlobStar && !ownProp(this.symlinks, abs))
|
||||
return this._readdirInGlobStar(abs, cb)
|
||||
|
||||
if (ownProp(this.cache, abs)) {
|
||||
var c = this.cache[abs]
|
||||
if (!c || c === 'FILE')
|
||||
return cb()
|
||||
|
||||
if (Array.isArray(c))
|
||||
return cb(null, c)
|
||||
}
|
||||
|
||||
var self = this
|
||||
self.fs.readdir(abs, readdirCb(this, abs, cb))
|
||||
}
|
||||
|
||||
function readdirCb (self, abs, cb) {
|
||||
return function (er, entries) {
|
||||
if (er)
|
||||
self._readdirError(abs, er, cb)
|
||||
else
|
||||
self._readdirEntries(abs, entries, cb)
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._readdirEntries = function (abs, entries, cb) {
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
// if we haven't asked to stat everything, then just
|
||||
// assume that everything in there exists, so we can avoid
|
||||
// having to stat it a second time.
|
||||
if (!this.mark && !this.stat) {
|
||||
for (var i = 0; i < entries.length; i ++) {
|
||||
var e = entries[i]
|
||||
if (abs === '/')
|
||||
e = abs + e
|
||||
else
|
||||
e = abs + '/' + e
|
||||
this.cache[e] = true
|
||||
}
|
||||
}
|
||||
|
||||
this.cache[abs] = entries
|
||||
return cb(null, entries)
|
||||
}
|
||||
|
||||
Glob.prototype._readdirError = function (f, er, cb) {
|
||||
if (this.aborted)
|
||||
return
|
||||
|
||||
// handle errors, and cache the information
|
||||
switch (er.code) {
|
||||
case 'ENOTSUP': // https://github.com/isaacs/node-glob/issues/205
|
||||
case 'ENOTDIR': // totally normal. means it *does* exist.
|
||||
var abs = this._makeAbs(f)
|
||||
this.cache[abs] = 'FILE'
|
||||
if (abs === this.cwdAbs) {
|
||||
var error = new Error(er.code + ' invalid cwd ' + this.cwd)
|
||||
error.path = this.cwd
|
||||
error.code = er.code
|
||||
this.emit('error', error)
|
||||
this.abort()
|
||||
}
|
||||
break
|
||||
|
||||
case 'ENOENT': // not terribly unusual
|
||||
case 'ELOOP':
|
||||
case 'ENAMETOOLONG':
|
||||
case 'UNKNOWN':
|
||||
this.cache[this._makeAbs(f)] = false
|
||||
break
|
||||
|
||||
default: // some unusual error. Treat as failure.
|
||||
this.cache[this._makeAbs(f)] = false
|
||||
if (this.strict) {
|
||||
this.emit('error', er)
|
||||
// If the error is handled, then we abort
|
||||
// if not, we threw out of here
|
||||
this.abort()
|
||||
}
|
||||
if (!this.silent)
|
||||
console.error('glob error', er)
|
||||
break
|
||||
}
|
||||
|
||||
return cb()
|
||||
}
|
||||
|
||||
Glob.prototype._processGlobStar = function (prefix, read, abs, remain, index, inGlobStar, cb) {
|
||||
var self = this
|
||||
this._readdir(abs, inGlobStar, function (er, entries) {
|
||||
self._processGlobStar2(prefix, read, abs, remain, index, inGlobStar, entries, cb)
|
||||
})
|
||||
}
|
||||
|
||||
|
||||
Glob.prototype._processGlobStar2 = function (prefix, read, abs, remain, index, inGlobStar, entries, cb) {
|
||||
//console.error('pgs2', prefix, remain[0], entries)
|
||||
|
||||
// no entries means not a dir, so it can never have matches
|
||||
// foo.txt/** doesn't match foo.txt
|
||||
if (!entries)
|
||||
return cb()
|
||||
|
||||
// test without the globstar, and with every child both below
|
||||
// and replacing the globstar.
|
||||
var remainWithoutGlobStar = remain.slice(1)
|
||||
var gspref = prefix ? [ prefix ] : []
|
||||
var noGlobStar = gspref.concat(remainWithoutGlobStar)
|
||||
|
||||
// the noGlobStar pattern exits the inGlobStar state
|
||||
this._process(noGlobStar, index, false, cb)
|
||||
|
||||
var isSym = this.symlinks[abs]
|
||||
var len = entries.length
|
||||
|
||||
// If it's a symlink, and we're in a globstar, then stop
|
||||
if (isSym && inGlobStar)
|
||||
return cb()
|
||||
|
||||
for (var i = 0; i < len; i++) {
|
||||
var e = entries[i]
|
||||
if (e.charAt(0) === '.' && !this.dot)
|
||||
continue
|
||||
|
||||
// these two cases enter the inGlobStar state
|
||||
var instead = gspref.concat(entries[i], remainWithoutGlobStar)
|
||||
this._process(instead, index, true, cb)
|
||||
|
||||
var below = gspref.concat(entries[i], remain)
|
||||
this._process(below, index, true, cb)
|
||||
}
|
||||
|
||||
cb()
|
||||
}
|
||||
|
||||
Glob.prototype._processSimple = function (prefix, index, cb) {
|
||||
// XXX review this. Shouldn't it be doing the mounting etc
|
||||
// before doing stat? kinda weird?
|
||||
var self = this
|
||||
this._stat(prefix, function (er, exists) {
|
||||
self._processSimple2(prefix, index, er, exists, cb)
|
||||
})
|
||||
}
|
||||
Glob.prototype._processSimple2 = function (prefix, index, er, exists, cb) {
|
||||
|
||||
//console.error('ps2', prefix, exists)
|
||||
|
||||
if (!this.matches[index])
|
||||
this.matches[index] = Object.create(null)
|
||||
|
||||
// If it doesn't exist, then just mark the lack of results
|
||||
if (!exists)
|
||||
return cb()
|
||||
|
||||
if (prefix && isAbsolute(prefix) && !this.nomount) {
|
||||
var trail = /[\/\\]$/.test(prefix)
|
||||
if (prefix.charAt(0) === '/') {
|
||||
prefix = path.join(this.root, prefix)
|
||||
} else {
|
||||
prefix = path.resolve(this.root, prefix)
|
||||
if (trail)
|
||||
prefix += '/'
|
||||
}
|
||||
}
|
||||
|
||||
if (process.platform === 'win32')
|
||||
prefix = prefix.replace(/\\/g, '/')
|
||||
|
||||
// Mark this as a match
|
||||
this._emitMatch(index, prefix)
|
||||
cb()
|
||||
}
|
||||
|
||||
// Returns either 'DIR', 'FILE', or false
|
||||
Glob.prototype._stat = function (f, cb) {
|
||||
var abs = this._makeAbs(f)
|
||||
var needDir = f.slice(-1) === '/'
|
||||
|
||||
if (f.length > this.maxLength)
|
||||
return cb()
|
||||
|
||||
if (!this.stat && ownProp(this.cache, abs)) {
|
||||
var c = this.cache[abs]
|
||||
|
||||
if (Array.isArray(c))
|
||||
c = 'DIR'
|
||||
|
||||
// It exists, but maybe not how we need it
|
||||
if (!needDir || c === 'DIR')
|
||||
return cb(null, c)
|
||||
|
||||
if (needDir && c === 'FILE')
|
||||
return cb()
|
||||
|
||||
// otherwise we have to stat, because maybe c=true
|
||||
// if we know it exists, but not what it is.
|
||||
}
|
||||
|
||||
var exists
|
||||
var stat = this.statCache[abs]
|
||||
if (stat !== undefined) {
|
||||
if (stat === false)
|
||||
return cb(null, stat)
|
||||
else {
|
||||
var type = stat.isDirectory() ? 'DIR' : 'FILE'
|
||||
if (needDir && type === 'FILE')
|
||||
return cb()
|
||||
else
|
||||
return cb(null, type, stat)
|
||||
}
|
||||
}
|
||||
|
||||
var self = this
|
||||
var statcb = inflight('stat\0' + abs, lstatcb_)
|
||||
if (statcb)
|
||||
self.fs.lstat(abs, statcb)
|
||||
|
||||
function lstatcb_ (er, lstat) {
|
||||
if (lstat && lstat.isSymbolicLink()) {
|
||||
// If it's a symlink, then treat it as the target, unless
|
||||
// the target does not exist, then treat it as a file.
|
||||
return self.fs.stat(abs, function (er, stat) {
|
||||
if (er)
|
||||
self._stat2(f, abs, null, lstat, cb)
|
||||
else
|
||||
self._stat2(f, abs, er, stat, cb)
|
||||
})
|
||||
} else {
|
||||
self._stat2(f, abs, er, lstat, cb)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Glob.prototype._stat2 = function (f, abs, er, stat, cb) {
|
||||
if (er && (er.code === 'ENOENT' || er.code === 'ENOTDIR')) {
|
||||
this.statCache[abs] = false
|
||||
return cb()
|
||||
}
|
||||
|
||||
var needDir = f.slice(-1) === '/'
|
||||
this.statCache[abs] = stat
|
||||
|
||||
if (abs.slice(-1) === '/' && stat && !stat.isDirectory())
|
||||
return cb(null, false, stat)
|
||||
|
||||
var c = true
|
||||
if (stat)
|
||||
c = stat.isDirectory() ? 'DIR' : 'FILE'
|
||||
this.cache[abs] = this.cache[abs] || c
|
||||
|
||||
if (needDir && c === 'FILE')
|
||||
return cb()
|
||||
|
||||
return cb(null, c, stat)
|
||||
}
|
||||
55
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/package.json
generated
vendored
Normal file
55
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,55 @@
|
|||
{
|
||||
"author": "Isaac Z. Schlueter <i@izs.me> (http://blog.izs.me/)",
|
||||
"name": "glob",
|
||||
"description": "a little globber",
|
||||
"version": "7.2.3",
|
||||
"publishConfig": {
|
||||
"tag": "v7-legacy"
|
||||
},
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/isaacs/node-glob.git"
|
||||
},
|
||||
"main": "glob.js",
|
||||
"files": [
|
||||
"glob.js",
|
||||
"sync.js",
|
||||
"common.js"
|
||||
],
|
||||
"engines": {
|
||||
"node": "*"
|
||||
},
|
||||
"dependencies": {
|
||||
"fs.realpath": "^1.0.0",
|
||||
"inflight": "^1.0.4",
|
||||
"inherits": "2",
|
||||
"minimatch": "^3.1.1",
|
||||
"once": "^1.3.0",
|
||||
"path-is-absolute": "^1.0.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"memfs": "^3.2.0",
|
||||
"mkdirp": "0",
|
||||
"rimraf": "^2.2.8",
|
||||
"tap": "^15.0.6",
|
||||
"tick": "0.0.6"
|
||||
},
|
||||
"tap": {
|
||||
"before": "test/00-setup.js",
|
||||
"after": "test/zz-cleanup.js",
|
||||
"jobs": 1
|
||||
},
|
||||
"scripts": {
|
||||
"prepublish": "npm run benchclean",
|
||||
"profclean": "rm -f v8.log profile.txt",
|
||||
"test": "tap",
|
||||
"test-regen": "npm run profclean && TEST_REGEN=1 node test/00-setup.js",
|
||||
"bench": "bash benchmark.sh",
|
||||
"prof": "bash prof.sh && cat profile.txt",
|
||||
"benchclean": "node benchclean.js"
|
||||
},
|
||||
"license": "ISC",
|
||||
"funding": {
|
||||
"url": "https://github.com/sponsors/isaacs"
|
||||
}
|
||||
}
|
||||
486
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/sync.js
generated
vendored
Normal file
486
electron/node_modules/cacache/node_modules/rimraf/node_modules/glob/sync.js
generated
vendored
Normal file
|
|
@ -0,0 +1,486 @@
|
|||
module.exports = globSync
|
||||
globSync.GlobSync = GlobSync
|
||||
|
||||
var rp = require('fs.realpath')
|
||||
var minimatch = require('minimatch')
|
||||
var Minimatch = minimatch.Minimatch
|
||||
var Glob = require('./glob.js').Glob
|
||||
var util = require('util')
|
||||
var path = require('path')
|
||||
var assert = require('assert')
|
||||
var isAbsolute = require('path-is-absolute')
|
||||
var common = require('./common.js')
|
||||
var setopts = common.setopts
|
||||
var ownProp = common.ownProp
|
||||
var childrenIgnored = common.childrenIgnored
|
||||
var isIgnored = common.isIgnored
|
||||
|
||||
function globSync (pattern, options) {
|
||||
if (typeof options === 'function' || arguments.length === 3)
|
||||
throw new TypeError('callback provided to sync glob\n'+
|
||||
'See: https://github.com/isaacs/node-glob/issues/167')
|
||||
|
||||
return new GlobSync(pattern, options).found
|
||||
}
|
||||
|
||||
function GlobSync (pattern, options) {
|
||||
if (!pattern)
|
||||
throw new Error('must provide pattern')
|
||||
|
||||
if (typeof options === 'function' || arguments.length === 3)
|
||||
throw new TypeError('callback provided to sync glob\n'+
|
||||
'See: https://github.com/isaacs/node-glob/issues/167')
|
||||
|
||||
if (!(this instanceof GlobSync))
|
||||
return new GlobSync(pattern, options)
|
||||
|
||||
setopts(this, pattern, options)
|
||||
|
||||
if (this.noprocess)
|
||||
return this
|
||||
|
||||
var n = this.minimatch.set.length
|
||||
this.matches = new Array(n)
|
||||
for (var i = 0; i < n; i ++) {
|
||||
this._process(this.minimatch.set[i], i, false)
|
||||
}
|
||||
this._finish()
|
||||
}
|
||||
|
||||
GlobSync.prototype._finish = function () {
|
||||
assert.ok(this instanceof GlobSync)
|
||||
if (this.realpath) {
|
||||
var self = this
|
||||
this.matches.forEach(function (matchset, index) {
|
||||
var set = self.matches[index] = Object.create(null)
|
||||
for (var p in matchset) {
|
||||
try {
|
||||
p = self._makeAbs(p)
|
||||
var real = rp.realpathSync(p, self.realpathCache)
|
||||
set[real] = true
|
||||
} catch (er) {
|
||||
if (er.syscall === 'stat')
|
||||
set[self._makeAbs(p)] = true
|
||||
else
|
||||
throw er
|
||||
}
|
||||
}
|
||||
})
|
||||
}
|
||||
common.finish(this)
|
||||
}
|
||||
|
||||
|
||||
GlobSync.prototype._process = function (pattern, index, inGlobStar) {
|
||||
assert.ok(this instanceof GlobSync)
|
||||
|
||||
// Get the first [n] parts of pattern that are all strings.
|
||||
var n = 0
|
||||
while (typeof pattern[n] === 'string') {
|
||||
n ++
|
||||
}
|
||||
// now n is the index of the first one that is *not* a string.
|
||||
|
||||
// See if there's anything else
|
||||
var prefix
|
||||
switch (n) {
|
||||
// if not, then this is rather simple
|
||||
case pattern.length:
|
||||
this._processSimple(pattern.join('/'), index)
|
||||
return
|
||||
|
||||
case 0:
|
||||
// pattern *starts* with some non-trivial item.
|
||||
// going to readdir(cwd), but not include the prefix in matches.
|
||||
prefix = null
|
||||
break
|
||||
|
||||
default:
|
||||
// pattern has some string bits in the front.
|
||||
// whatever it starts with, whether that's 'absolute' like /foo/bar,
|
||||
// or 'relative' like '../baz'
|
||||
prefix = pattern.slice(0, n).join('/')
|
||||
break
|
||||
}
|
||||
|
||||
var remain = pattern.slice(n)
|
||||
|
||||
// get the list of entries.
|
||||
var read
|
||||
if (prefix === null)
|
||||
read = '.'
|
||||
else if (isAbsolute(prefix) ||
|
||||
isAbsolute(pattern.map(function (p) {
|
||||
return typeof p === 'string' ? p : '[*]'
|
||||
}).join('/'))) {
|
||||
if (!prefix || !isAbsolute(prefix))
|
||||
prefix = '/' + prefix
|
||||
read = prefix
|
||||
} else
|
||||
read = prefix
|
||||
|
||||
var abs = this._makeAbs(read)
|
||||
|
||||
//if ignored, skip processing
|
||||
if (childrenIgnored(this, read))
|
||||
return
|
||||
|
||||
var isGlobStar = remain[0] === minimatch.GLOBSTAR
|
||||
if (isGlobStar)
|
||||
this._processGlobStar(prefix, read, abs, remain, index, inGlobStar)
|
||||
else
|
||||
this._processReaddir(prefix, read, abs, remain, index, inGlobStar)
|
||||
}
|
||||
|
||||
|
||||
GlobSync.prototype._processReaddir = function (prefix, read, abs, remain, index, inGlobStar) {
|
||||
var entries = this._readdir(abs, inGlobStar)
|
||||
|
||||
// if the abs isn't a dir, then nothing can match!
|
||||
if (!entries)
|
||||
return
|
||||
|
||||
// It will only match dot entries if it starts with a dot, or if
|
||||
// dot is set. Stuff like @(.foo|.bar) isn't allowed.
|
||||
var pn = remain[0]
|
||||
var negate = !!this.minimatch.negate
|
||||
var rawGlob = pn._glob
|
||||
var dotOk = this.dot || rawGlob.charAt(0) === '.'
|
||||
|
||||
var matchedEntries = []
|
||||
for (var i = 0; i < entries.length; i++) {
|
||||
var e = entries[i]
|
||||
if (e.charAt(0) !== '.' || dotOk) {
|
||||
var m
|
||||
if (negate && !prefix) {
|
||||
m = !e.match(pn)
|
||||
} else {
|
||||
m = e.match(pn)
|
||||
}
|
||||
if (m)
|
||||
matchedEntries.push(e)
|
||||
}
|
||||
}
|
||||
|
||||
var len = matchedEntries.length
|
||||
// If there are no matched entries, then nothing matches.
|
||||
if (len === 0)
|
||||
return
|
||||
|
||||
// if this is the last remaining pattern bit, then no need for
|
||||
// an additional stat *unless* the user has specified mark or
|
||||
// stat explicitly. We know they exist, since readdir returned
|
||||
// them.
|
||||
|
||||
if (remain.length === 1 && !this.mark && !this.stat) {
|
||||
if (!this.matches[index])
|
||||
this.matches[index] = Object.create(null)
|
||||
|
||||
for (var i = 0; i < len; i ++) {
|
||||
var e = matchedEntries[i]
|
||||
if (prefix) {
|
||||
if (prefix.slice(-1) !== '/')
|
||||
e = prefix + '/' + e
|
||||
else
|
||||
e = prefix + e
|
||||
}
|
||||
|
||||
if (e.charAt(0) === '/' && !this.nomount) {
|
||||
e = path.join(this.root, e)
|
||||
}
|
||||
this._emitMatch(index, e)
|
||||
}
|
||||
// This was the last one, and no stats were needed
|
||||
return
|
||||
}
|
||||
|
||||
// now test all matched entries as stand-ins for that part
|
||||
// of the pattern.
|
||||
remain.shift()
|
||||
for (var i = 0; i < len; i ++) {
|
||||
var e = matchedEntries[i]
|
||||
var newPattern
|
||||
if (prefix)
|
||||
newPattern = [prefix, e]
|
||||
else
|
||||
newPattern = [e]
|
||||
this._process(newPattern.concat(remain), index, inGlobStar)
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
GlobSync.prototype._emitMatch = function (index, e) {
|
||||
if (isIgnored(this, e))
|
||||
return
|
||||
|
||||
var abs = this._makeAbs(e)
|
||||
|
||||
if (this.mark)
|
||||
e = this._mark(e)
|
||||
|
||||
if (this.absolute) {
|
||||
e = abs
|
||||
}
|
||||
|
||||
if (this.matches[index][e])
|
||||
return
|
||||
|
||||
if (this.nodir) {
|
||||
var c = this.cache[abs]
|
||||
if (c === 'DIR' || Array.isArray(c))
|
||||
return
|
||||
}
|
||||
|
||||
this.matches[index][e] = true
|
||||
|
||||
if (this.stat)
|
||||
this._stat(e)
|
||||
}
|
||||
|
||||
|
||||
GlobSync.prototype._readdirInGlobStar = function (abs) {
|
||||
// follow all symlinked directories forever
|
||||
// just proceed as if this is a non-globstar situation
|
||||
if (this.follow)
|
||||
return this._readdir(abs, false)
|
||||
|
||||
var entries
|
||||
var lstat
|
||||
var stat
|
||||
try {
|
||||
lstat = this.fs.lstatSync(abs)
|
||||
} catch (er) {
|
||||
if (er.code === 'ENOENT') {
|
||||
// lstat failed, doesn't exist
|
||||
return null
|
||||
}
|
||||
}
|
||||
|
||||
var isSym = lstat && lstat.isSymbolicLink()
|
||||
this.symlinks[abs] = isSym
|
||||
|
||||
// If it's not a symlink or a dir, then it's definitely a regular file.
|
||||
// don't bother doing a readdir in that case.
|
||||
if (!isSym && lstat && !lstat.isDirectory())
|
||||
this.cache[abs] = 'FILE'
|
||||
else
|
||||
entries = this._readdir(abs, false)
|
||||
|
||||
return entries
|
||||
}
|
||||
|
||||
GlobSync.prototype._readdir = function (abs, inGlobStar) {
|
||||
var entries
|
||||
|
||||
if (inGlobStar && !ownProp(this.symlinks, abs))
|
||||
return this._readdirInGlobStar(abs)
|
||||
|
||||
if (ownProp(this.cache, abs)) {
|
||||
var c = this.cache[abs]
|
||||
if (!c || c === 'FILE')
|
||||
return null
|
||||
|
||||
if (Array.isArray(c))
|
||||
return c
|
||||
}
|
||||
|
||||
try {
|
||||
return this._readdirEntries(abs, this.fs.readdirSync(abs))
|
||||
} catch (er) {
|
||||
this._readdirError(abs, er)
|
||||
return null
|
||||
}
|
||||
}
|
||||
|
||||
GlobSync.prototype._readdirEntries = function (abs, entries) {
|
||||
// if we haven't asked to stat everything, then just
|
||||
// assume that everything in there exists, so we can avoid
|
||||
// having to stat it a second time.
|
||||
if (!this.mark && !this.stat) {
|
||||
for (var i = 0; i < entries.length; i ++) {
|
||||
var e = entries[i]
|
||||
if (abs === '/')
|
||||
e = abs + e
|
||||
else
|
||||
e = abs + '/' + e
|
||||
this.cache[e] = true
|
||||
}
|
||||
}
|
||||
|
||||
this.cache[abs] = entries
|
||||
|
||||
// mark and cache dir-ness
|
||||
return entries
|
||||
}
|
||||
|
||||
GlobSync.prototype._readdirError = function (f, er) {
|
||||
// handle errors, and cache the information
|
||||
switch (er.code) {
|
||||
case 'ENOTSUP': // https://github.com/isaacs/node-glob/issues/205
|
||||
case 'ENOTDIR': // totally normal. means it *does* exist.
|
||||
var abs = this._makeAbs(f)
|
||||
this.cache[abs] = 'FILE'
|
||||
if (abs === this.cwdAbs) {
|
||||
var error = new Error(er.code + ' invalid cwd ' + this.cwd)
|
||||
error.path = this.cwd
|
||||
error.code = er.code
|
||||
throw error
|
||||
}
|
||||
break
|
||||
|
||||
case 'ENOENT': // not terribly unusual
|
||||
case 'ELOOP':
|
||||
case 'ENAMETOOLONG':
|
||||
case 'UNKNOWN':
|
||||
this.cache[this._makeAbs(f)] = false
|
||||
break
|
||||
|
||||
default: // some unusual error. Treat as failure.
|
||||
this.cache[this._makeAbs(f)] = false
|
||||
if (this.strict)
|
||||
throw er
|
||||
if (!this.silent)
|
||||
console.error('glob error', er)
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
GlobSync.prototype._processGlobStar = function (prefix, read, abs, remain, index, inGlobStar) {
|
||||
|
||||
var entries = this._readdir(abs, inGlobStar)
|
||||
|
||||
// no entries means not a dir, so it can never have matches
|
||||
// foo.txt/** doesn't match foo.txt
|
||||
if (!entries)
|
||||
return
|
||||
|
||||
// test without the globstar, and with every child both below
|
||||
// and replacing the globstar.
|
||||
var remainWithoutGlobStar = remain.slice(1)
|
||||
var gspref = prefix ? [ prefix ] : []
|
||||
var noGlobStar = gspref.concat(remainWithoutGlobStar)
|
||||
|
||||
// the noGlobStar pattern exits the inGlobStar state
|
||||
this._process(noGlobStar, index, false)
|
||||
|
||||
var len = entries.length
|
||||
var isSym = this.symlinks[abs]
|
||||
|
||||
// If it's a symlink, and we're in a globstar, then stop
|
||||
if (isSym && inGlobStar)
|
||||
return
|
||||
|
||||
for (var i = 0; i < len; i++) {
|
||||
var e = entries[i]
|
||||
if (e.charAt(0) === '.' && !this.dot)
|
||||
continue
|
||||
|
||||
// these two cases enter the inGlobStar state
|
||||
var instead = gspref.concat(entries[i], remainWithoutGlobStar)
|
||||
this._process(instead, index, true)
|
||||
|
||||
var below = gspref.concat(entries[i], remain)
|
||||
this._process(below, index, true)
|
||||
}
|
||||
}
|
||||
|
||||
GlobSync.prototype._processSimple = function (prefix, index) {
|
||||
// XXX review this. Shouldn't it be doing the mounting etc
|
||||
// before doing stat? kinda weird?
|
||||
var exists = this._stat(prefix)
|
||||
|
||||
if (!this.matches[index])
|
||||
this.matches[index] = Object.create(null)
|
||||
|
||||
// If it doesn't exist, then just mark the lack of results
|
||||
if (!exists)
|
||||
return
|
||||
|
||||
if (prefix && isAbsolute(prefix) && !this.nomount) {
|
||||
var trail = /[\/\\]$/.test(prefix)
|
||||
if (prefix.charAt(0) === '/') {
|
||||
prefix = path.join(this.root, prefix)
|
||||
} else {
|
||||
prefix = path.resolve(this.root, prefix)
|
||||
if (trail)
|
||||
prefix += '/'
|
||||
}
|
||||
}
|
||||
|
||||
if (process.platform === 'win32')
|
||||
prefix = prefix.replace(/\\/g, '/')
|
||||
|
||||
// Mark this as a match
|
||||
this._emitMatch(index, prefix)
|
||||
}
|
||||
|
||||
// Returns either 'DIR', 'FILE', or false
|
||||
GlobSync.prototype._stat = function (f) {
|
||||
var abs = this._makeAbs(f)
|
||||
var needDir = f.slice(-1) === '/'
|
||||
|
||||
if (f.length > this.maxLength)
|
||||
return false
|
||||
|
||||
if (!this.stat && ownProp(this.cache, abs)) {
|
||||
var c = this.cache[abs]
|
||||
|
||||
if (Array.isArray(c))
|
||||
c = 'DIR'
|
||||
|
||||
// It exists, but maybe not how we need it
|
||||
if (!needDir || c === 'DIR')
|
||||
return c
|
||||
|
||||
if (needDir && c === 'FILE')
|
||||
return false
|
||||
|
||||
// otherwise we have to stat, because maybe c=true
|
||||
// if we know it exists, but not what it is.
|
||||
}
|
||||
|
||||
var exists
|
||||
var stat = this.statCache[abs]
|
||||
if (!stat) {
|
||||
var lstat
|
||||
try {
|
||||
lstat = this.fs.lstatSync(abs)
|
||||
} catch (er) {
|
||||
if (er && (er.code === 'ENOENT' || er.code === 'ENOTDIR')) {
|
||||
this.statCache[abs] = false
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
if (lstat && lstat.isSymbolicLink()) {
|
||||
try {
|
||||
stat = this.fs.statSync(abs)
|
||||
} catch (er) {
|
||||
stat = lstat
|
||||
}
|
||||
} else {
|
||||
stat = lstat
|
||||
}
|
||||
}
|
||||
|
||||
this.statCache[abs] = stat
|
||||
|
||||
var c = true
|
||||
if (stat)
|
||||
c = stat.isDirectory() ? 'DIR' : 'FILE'
|
||||
|
||||
this.cache[abs] = this.cache[abs] || c
|
||||
|
||||
if (needDir && c === 'FILE')
|
||||
return false
|
||||
|
||||
return c
|
||||
}
|
||||
|
||||
GlobSync.prototype._mark = function (p) {
|
||||
return common.mark(this, p)
|
||||
}
|
||||
|
||||
GlobSync.prototype._makeAbs = function (f) {
|
||||
return common.makeAbs(this, f)
|
||||
}
|
||||
15
electron/node_modules/cacache/node_modules/rimraf/node_modules/minimatch/LICENSE
generated
vendored
Normal file
15
electron/node_modules/cacache/node_modules/rimraf/node_modules/minimatch/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
The ISC License
|
||||
|
||||
Copyright (c) Isaac Z. Schlueter and Contributors
|
||||
|
||||
Permission to use, copy, modify, and/or distribute this software for any
|
||||
purpose with or without fee is hereby granted, provided that the above
|
||||
copyright notice and this permission notice appear in all copies.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
||||
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
||||
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
||||
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
||||
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR
|
||||
IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
267
electron/node_modules/cacache/node_modules/rimraf/node_modules/minimatch/README.md
generated
vendored
Normal file
267
electron/node_modules/cacache/node_modules/rimraf/node_modules/minimatch/README.md
generated
vendored
Normal file
|
|
@ -0,0 +1,267 @@
|
|||
# minimatch
|
||||
|
||||
A minimal matching utility.
|
||||
|
||||
[](http://travis-ci.org/isaacs/minimatch)
|
||||
|
||||
|
||||
This is the matching library used internally by npm.
|
||||
|
||||
It works by converting glob expressions into JavaScript `RegExp`
|
||||
objects.
|
||||
|
||||
## Important Security Consideration!
|
||||
|
||||
> [!WARNING]
|
||||
> This library uses JavaScript regular expressions. Please read
|
||||
> the following warning carefully, and be thoughtful about what
|
||||
> you provide to this library in production systems.
|
||||
|
||||
_Any_ library in JavaScript that deals with matching string
|
||||
patterns using regular expressions will be subject to
|
||||
[ReDoS](https://owasp.org/www-community/attacks/Regular_expression_Denial_of_Service_-_ReDoS)
|
||||
if the pattern is generated using untrusted input.
|
||||
|
||||
Efforts have been made to mitigate risk as much as is feasible in
|
||||
such a library, providing maximum recursion depths and so forth,
|
||||
but these measures can only ultimately protect against accidents,
|
||||
not malice. A dedicated attacker can _always_ find patterns that
|
||||
cannot be defended against by a bash-compatible glob pattern
|
||||
matching system that uses JavaScript regular expressions.
|
||||
|
||||
To be extremely clear:
|
||||
|
||||
> [!WARNING]
|
||||
> **If you create a system where you take user input, and use
|
||||
> that input as the source of a Regular Expression pattern, in
|
||||
> this or any extant glob matcher in JavaScript, you will be
|
||||
> pwned.**
|
||||
|
||||
A future version of this library _may_ use a different matching
|
||||
algorithm which does not exhibit backtracking problems. If and
|
||||
when that happens, it will likely be a sweeping change, and those
|
||||
improvements will **not** be backported to legacy versions.
|
||||
|
||||
In the near term, it is not reasonable to continue to play
|
||||
whack-a-mole with security advisories, and so any future ReDoS
|
||||
reports will be considered "working as intended", and resolved
|
||||
entirely by this warning.
|
||||
|
||||
## Usage
|
||||
|
||||
```javascript
|
||||
var minimatch = require("minimatch")
|
||||
|
||||
minimatch("bar.foo", "*.foo") // true!
|
||||
minimatch("bar.foo", "*.bar") // false!
|
||||
minimatch("bar.foo", "*.+(bar|foo)", { debug: true }) // true, and noisy!
|
||||
```
|
||||
|
||||
## Features
|
||||
|
||||
Supports these glob features:
|
||||
|
||||
* Brace Expansion
|
||||
* Extended glob matching
|
||||
* "Globstar" `**` matching
|
||||
|
||||
See:
|
||||
|
||||
* `man sh`
|
||||
* `man bash`
|
||||
* `man 3 fnmatch`
|
||||
* `man 5 gitignore`
|
||||
|
||||
## Minimatch Class
|
||||
|
||||
Create a minimatch object by instantiating the `minimatch.Minimatch` class.
|
||||
|
||||
```javascript
|
||||
var Minimatch = require("minimatch").Minimatch
|
||||
var mm = new Minimatch(pattern, options)
|
||||
```
|
||||
|
||||
### Properties
|
||||
|
||||
* `pattern` The original pattern the minimatch object represents.
|
||||
* `options` The options supplied to the constructor.
|
||||
* `set` A 2-dimensional array of regexp or string expressions.
|
||||
Each row in the
|
||||
array corresponds to a brace-expanded pattern. Each item in the row
|
||||
corresponds to a single path-part. For example, the pattern
|
||||
`{a,b/c}/d` would expand to a set of patterns like:
|
||||
|
||||
[ [ a, d ]
|
||||
, [ b, c, d ] ]
|
||||
|
||||
If a portion of the pattern doesn't have any "magic" in it
|
||||
(that is, it's something like `"foo"` rather than `fo*o?`), then it
|
||||
will be left as a string rather than converted to a regular
|
||||
expression.
|
||||
|
||||
* `regexp` Created by the `makeRe` method. A single regular expression
|
||||
expressing the entire pattern. This is useful in cases where you wish
|
||||
to use the pattern somewhat like `fnmatch(3)` with `FNM_PATH` enabled.
|
||||
* `negate` True if the pattern is negated.
|
||||
* `comment` True if the pattern is a comment.
|
||||
* `empty` True if the pattern is `""`.
|
||||
|
||||
### Methods
|
||||
|
||||
* `makeRe` Generate the `regexp` member if necessary, and return it.
|
||||
Will return `false` if the pattern is invalid.
|
||||
* `match(fname)` Return true if the filename matches the pattern, or
|
||||
false otherwise.
|
||||
* `matchOne(fileArray, patternArray, partial)` Take a `/`-split
|
||||
filename, and match it against a single row in the `regExpSet`. This
|
||||
method is mainly for internal use, but is exposed so that it can be
|
||||
used by a glob-walker that needs to avoid excessive filesystem calls.
|
||||
|
||||
All other methods are internal, and will be called as necessary.
|
||||
|
||||
### minimatch(path, pattern, options)
|
||||
|
||||
Main export. Tests a path against the pattern using the options.
|
||||
|
||||
```javascript
|
||||
var isJS = minimatch(file, "*.js", { matchBase: true })
|
||||
```
|
||||
|
||||
### minimatch.filter(pattern, options)
|
||||
|
||||
Returns a function that tests its
|
||||
supplied argument, suitable for use with `Array.filter`. Example:
|
||||
|
||||
```javascript
|
||||
var javascripts = fileList.filter(minimatch.filter("*.js", {matchBase: true}))
|
||||
```
|
||||
|
||||
### minimatch.match(list, pattern, options)
|
||||
|
||||
Match against the list of
|
||||
files, in the style of fnmatch or glob. If nothing is matched, and
|
||||
options.nonull is set, then return a list containing the pattern itself.
|
||||
|
||||
```javascript
|
||||
var javascripts = minimatch.match(fileList, "*.js", {matchBase: true}))
|
||||
```
|
||||
|
||||
### minimatch.makeRe(pattern, options)
|
||||
|
||||
Make a regular expression object from the pattern.
|
||||
|
||||
## Options
|
||||
|
||||
All options are `false` by default.
|
||||
|
||||
### debug
|
||||
|
||||
Dump a ton of stuff to stderr.
|
||||
|
||||
### nobrace
|
||||
|
||||
Do not expand `{a,b}` and `{1..3}` brace sets.
|
||||
|
||||
### noglobstar
|
||||
|
||||
Disable `**` matching against multiple folder names.
|
||||
|
||||
### dot
|
||||
|
||||
Allow patterns to match filenames starting with a period, even if
|
||||
the pattern does not explicitly have a period in that spot.
|
||||
|
||||
Note that by default, `a/**/b` will **not** match `a/.d/b`, unless `dot`
|
||||
is set.
|
||||
|
||||
### noext
|
||||
|
||||
Disable "extglob" style patterns like `+(a|b)`.
|
||||
|
||||
### nocase
|
||||
|
||||
Perform a case-insensitive match.
|
||||
|
||||
### nonull
|
||||
|
||||
When a match is not found by `minimatch.match`, return a list containing
|
||||
the pattern itself if this option is set. When not set, an empty list
|
||||
is returned if there are no matches.
|
||||
|
||||
### matchBase
|
||||
|
||||
If set, then patterns without slashes will be matched
|
||||
against the basename of the path if it contains slashes. For example,
|
||||
`a?b` would match the path `/xyz/123/acb`, but not `/xyz/acb/123`.
|
||||
|
||||
### nocomment
|
||||
|
||||
Suppress the behavior of treating `#` at the start of a pattern as a
|
||||
comment.
|
||||
|
||||
### nonegate
|
||||
|
||||
Suppress the behavior of treating a leading `!` character as negation.
|
||||
|
||||
### flipNegate
|
||||
|
||||
Returns from negate expressions the same as if they were not negated.
|
||||
(Ie, true on a hit, false on a miss.)
|
||||
|
||||
### partial
|
||||
|
||||
Compare a partial path to a pattern. As long as the parts of the path that
|
||||
are present are not contradicted by the pattern, it will be treated as a
|
||||
match. This is useful in applications where you're walking through a
|
||||
folder structure, and don't yet have the full path, but want to ensure that
|
||||
you do not walk down paths that can never be a match.
|
||||
|
||||
For example,
|
||||
|
||||
```js
|
||||
minimatch('/a/b', '/a/*/c/d', { partial: true }) // true, might be /a/b/c/d
|
||||
minimatch('/a/b', '/**/d', { partial: true }) // true, might be /a/b/.../d
|
||||
minimatch('/x/y/z', '/a/**/z', { partial: true }) // false, because x !== a
|
||||
```
|
||||
|
||||
### allowWindowsEscape
|
||||
|
||||
Windows path separator `\` is by default converted to `/`, which
|
||||
prohibits the usage of `\` as a escape character. This flag skips that
|
||||
behavior and allows using the escape character.
|
||||
|
||||
## Comparisons to other fnmatch/glob implementations
|
||||
|
||||
While strict compliance with the existing standards is a worthwhile
|
||||
goal, some discrepancies exist between minimatch and other
|
||||
implementations, and are intentional.
|
||||
|
||||
If the pattern starts with a `!` character, then it is negated. Set the
|
||||
`nonegate` flag to suppress this behavior, and treat leading `!`
|
||||
characters normally. This is perhaps relevant if you wish to start the
|
||||
pattern with a negative extglob pattern like `!(a|B)`. Multiple `!`
|
||||
characters at the start of a pattern will negate the pattern multiple
|
||||
times.
|
||||
|
||||
If a pattern starts with `#`, then it is treated as a comment, and
|
||||
will not match anything. Use `\#` to match a literal `#` at the
|
||||
start of a line, or set the `nocomment` flag to suppress this behavior.
|
||||
|
||||
The double-star character `**` is supported by default, unless the
|
||||
`noglobstar` flag is set. This is supported in the manner of bsdglob
|
||||
and bash 4.1, where `**` only has special significance if it is the only
|
||||
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
|
||||
`a/**b` will not.
|
||||
|
||||
If an escaped pattern has no matches, and the `nonull` flag is set,
|
||||
then minimatch.match returns the pattern as-provided, rather than
|
||||
interpreting the character escapes. For example,
|
||||
`minimatch.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
|
||||
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
|
||||
that it does not resolve escaped pattern characters.
|
||||
|
||||
If brace expansion is not disabled, then it is performed before any
|
||||
other interpretation of the glob pattern. Thus, a pattern like
|
||||
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
|
||||
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
|
||||
checked for validity. Since those two are valid, matching proceeds.
|
||||
1005
electron/node_modules/cacache/node_modules/rimraf/node_modules/minimatch/minimatch.js
generated
vendored
Normal file
1005
electron/node_modules/cacache/node_modules/rimraf/node_modules/minimatch/minimatch.js
generated
vendored
Normal file
File diff suppressed because it is too large
Load diff
33
electron/node_modules/cacache/node_modules/rimraf/node_modules/minimatch/package.json
generated
vendored
Normal file
33
electron/node_modules/cacache/node_modules/rimraf/node_modules/minimatch/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,33 @@
|
|||
{
|
||||
"author": "Isaac Z. Schlueter <i@izs.me> (http://blog.izs.me)",
|
||||
"name": "minimatch",
|
||||
"description": "a glob matcher in javascript",
|
||||
"version": "3.1.5",
|
||||
"publishConfig": {
|
||||
"tag": "legacy-v3"
|
||||
},
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/isaacs/minimatch.git"
|
||||
},
|
||||
"main": "minimatch.js",
|
||||
"scripts": {
|
||||
"test": "tap",
|
||||
"preversion": "npm test",
|
||||
"postversion": "npm publish",
|
||||
"postpublish": "git push origin --all; git push origin --tags"
|
||||
},
|
||||
"engines": {
|
||||
"node": "*"
|
||||
},
|
||||
"dependencies": {
|
||||
"brace-expansion": "^1.1.7"
|
||||
},
|
||||
"devDependencies": {
|
||||
"tap": "^15.1.6"
|
||||
},
|
||||
"license": "ISC",
|
||||
"files": [
|
||||
"minimatch.js"
|
||||
]
|
||||
}
|
||||
32
electron/node_modules/cacache/node_modules/rimraf/package.json
generated
vendored
Normal file
32
electron/node_modules/cacache/node_modules/rimraf/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,32 @@
|
|||
{
|
||||
"name": "rimraf",
|
||||
"version": "3.0.2",
|
||||
"main": "rimraf.js",
|
||||
"description": "A deep deletion module for node (like `rm -rf`)",
|
||||
"author": "Isaac Z. Schlueter <i@izs.me> (http://blog.izs.me/)",
|
||||
"license": "ISC",
|
||||
"repository": "git://github.com/isaacs/rimraf.git",
|
||||
"scripts": {
|
||||
"preversion": "npm test",
|
||||
"postversion": "npm publish",
|
||||
"postpublish": "git push origin --follow-tags",
|
||||
"test": "tap test/*.js"
|
||||
},
|
||||
"bin": "./bin.js",
|
||||
"dependencies": {
|
||||
"glob": "^7.1.3"
|
||||
},
|
||||
"files": [
|
||||
"LICENSE",
|
||||
"README.md",
|
||||
"bin.js",
|
||||
"rimraf.js"
|
||||
],
|
||||
"devDependencies": {
|
||||
"mkdirp": "^0.5.1",
|
||||
"tap": "^12.1.1"
|
||||
},
|
||||
"funding": {
|
||||
"url": "https://github.com/sponsors/isaacs"
|
||||
}
|
||||
}
|
||||
360
electron/node_modules/cacache/node_modules/rimraf/rimraf.js
generated
vendored
Normal file
360
electron/node_modules/cacache/node_modules/rimraf/rimraf.js
generated
vendored
Normal file
|
|
@ -0,0 +1,360 @@
|
|||
const assert = require("assert")
|
||||
const path = require("path")
|
||||
const fs = require("fs")
|
||||
let glob = undefined
|
||||
try {
|
||||
glob = require("glob")
|
||||
} catch (_err) {
|
||||
// treat glob as optional.
|
||||
}
|
||||
|
||||
const defaultGlobOpts = {
|
||||
nosort: true,
|
||||
silent: true
|
||||
}
|
||||
|
||||
// for EMFILE handling
|
||||
let timeout = 0
|
||||
|
||||
const isWindows = (process.platform === "win32")
|
||||
|
||||
const defaults = options => {
|
||||
const methods = [
|
||||
'unlink',
|
||||
'chmod',
|
||||
'stat',
|
||||
'lstat',
|
||||
'rmdir',
|
||||
'readdir'
|
||||
]
|
||||
methods.forEach(m => {
|
||||
options[m] = options[m] || fs[m]
|
||||
m = m + 'Sync'
|
||||
options[m] = options[m] || fs[m]
|
||||
})
|
||||
|
||||
options.maxBusyTries = options.maxBusyTries || 3
|
||||
options.emfileWait = options.emfileWait || 1000
|
||||
if (options.glob === false) {
|
||||
options.disableGlob = true
|
||||
}
|
||||
if (options.disableGlob !== true && glob === undefined) {
|
||||
throw Error('glob dependency not found, set `options.disableGlob = true` if intentional')
|
||||
}
|
||||
options.disableGlob = options.disableGlob || false
|
||||
options.glob = options.glob || defaultGlobOpts
|
||||
}
|
||||
|
||||
const rimraf = (p, options, cb) => {
|
||||
if (typeof options === 'function') {
|
||||
cb = options
|
||||
options = {}
|
||||
}
|
||||
|
||||
assert(p, 'rimraf: missing path')
|
||||
assert.equal(typeof p, 'string', 'rimraf: path should be a string')
|
||||
assert.equal(typeof cb, 'function', 'rimraf: callback function required')
|
||||
assert(options, 'rimraf: invalid options argument provided')
|
||||
assert.equal(typeof options, 'object', 'rimraf: options should be object')
|
||||
|
||||
defaults(options)
|
||||
|
||||
let busyTries = 0
|
||||
let errState = null
|
||||
let n = 0
|
||||
|
||||
const next = (er) => {
|
||||
errState = errState || er
|
||||
if (--n === 0)
|
||||
cb(errState)
|
||||
}
|
||||
|
||||
const afterGlob = (er, results) => {
|
||||
if (er)
|
||||
return cb(er)
|
||||
|
||||
n = results.length
|
||||
if (n === 0)
|
||||
return cb()
|
||||
|
||||
results.forEach(p => {
|
||||
const CB = (er) => {
|
||||
if (er) {
|
||||
if ((er.code === "EBUSY" || er.code === "ENOTEMPTY" || er.code === "EPERM") &&
|
||||
busyTries < options.maxBusyTries) {
|
||||
busyTries ++
|
||||
// try again, with the same exact callback as this one.
|
||||
return setTimeout(() => rimraf_(p, options, CB), busyTries * 100)
|
||||
}
|
||||
|
||||
// this one won't happen if graceful-fs is used.
|
||||
if (er.code === "EMFILE" && timeout < options.emfileWait) {
|
||||
return setTimeout(() => rimraf_(p, options, CB), timeout ++)
|
||||
}
|
||||
|
||||
// already gone
|
||||
if (er.code === "ENOENT") er = null
|
||||
}
|
||||
|
||||
timeout = 0
|
||||
next(er)
|
||||
}
|
||||
rimraf_(p, options, CB)
|
||||
})
|
||||
}
|
||||
|
||||
if (options.disableGlob || !glob.hasMagic(p))
|
||||
return afterGlob(null, [p])
|
||||
|
||||
options.lstat(p, (er, stat) => {
|
||||
if (!er)
|
||||
return afterGlob(null, [p])
|
||||
|
||||
glob(p, options.glob, afterGlob)
|
||||
})
|
||||
|
||||
}
|
||||
|
||||
// Two possible strategies.
|
||||
// 1. Assume it's a file. unlink it, then do the dir stuff on EPERM or EISDIR
|
||||
// 2. Assume it's a directory. readdir, then do the file stuff on ENOTDIR
|
||||
//
|
||||
// Both result in an extra syscall when you guess wrong. However, there
|
||||
// are likely far more normal files in the world than directories. This
|
||||
// is based on the assumption that a the average number of files per
|
||||
// directory is >= 1.
|
||||
//
|
||||
// If anyone ever complains about this, then I guess the strategy could
|
||||
// be made configurable somehow. But until then, YAGNI.
|
||||
const rimraf_ = (p, options, cb) => {
|
||||
assert(p)
|
||||
assert(options)
|
||||
assert(typeof cb === 'function')
|
||||
|
||||
// sunos lets the root user unlink directories, which is... weird.
|
||||
// so we have to lstat here and make sure it's not a dir.
|
||||
options.lstat(p, (er, st) => {
|
||||
if (er && er.code === "ENOENT")
|
||||
return cb(null)
|
||||
|
||||
// Windows can EPERM on stat. Life is suffering.
|
||||
if (er && er.code === "EPERM" && isWindows)
|
||||
fixWinEPERM(p, options, er, cb)
|
||||
|
||||
if (st && st.isDirectory())
|
||||
return rmdir(p, options, er, cb)
|
||||
|
||||
options.unlink(p, er => {
|
||||
if (er) {
|
||||
if (er.code === "ENOENT")
|
||||
return cb(null)
|
||||
if (er.code === "EPERM")
|
||||
return (isWindows)
|
||||
? fixWinEPERM(p, options, er, cb)
|
||||
: rmdir(p, options, er, cb)
|
||||
if (er.code === "EISDIR")
|
||||
return rmdir(p, options, er, cb)
|
||||
}
|
||||
return cb(er)
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
const fixWinEPERM = (p, options, er, cb) => {
|
||||
assert(p)
|
||||
assert(options)
|
||||
assert(typeof cb === 'function')
|
||||
|
||||
options.chmod(p, 0o666, er2 => {
|
||||
if (er2)
|
||||
cb(er2.code === "ENOENT" ? null : er)
|
||||
else
|
||||
options.stat(p, (er3, stats) => {
|
||||
if (er3)
|
||||
cb(er3.code === "ENOENT" ? null : er)
|
||||
else if (stats.isDirectory())
|
||||
rmdir(p, options, er, cb)
|
||||
else
|
||||
options.unlink(p, cb)
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
const fixWinEPERMSync = (p, options, er) => {
|
||||
assert(p)
|
||||
assert(options)
|
||||
|
||||
try {
|
||||
options.chmodSync(p, 0o666)
|
||||
} catch (er2) {
|
||||
if (er2.code === "ENOENT")
|
||||
return
|
||||
else
|
||||
throw er
|
||||
}
|
||||
|
||||
let stats
|
||||
try {
|
||||
stats = options.statSync(p)
|
||||
} catch (er3) {
|
||||
if (er3.code === "ENOENT")
|
||||
return
|
||||
else
|
||||
throw er
|
||||
}
|
||||
|
||||
if (stats.isDirectory())
|
||||
rmdirSync(p, options, er)
|
||||
else
|
||||
options.unlinkSync(p)
|
||||
}
|
||||
|
||||
const rmdir = (p, options, originalEr, cb) => {
|
||||
assert(p)
|
||||
assert(options)
|
||||
assert(typeof cb === 'function')
|
||||
|
||||
// try to rmdir first, and only readdir on ENOTEMPTY or EEXIST (SunOS)
|
||||
// if we guessed wrong, and it's not a directory, then
|
||||
// raise the original error.
|
||||
options.rmdir(p, er => {
|
||||
if (er && (er.code === "ENOTEMPTY" || er.code === "EEXIST" || er.code === "EPERM"))
|
||||
rmkids(p, options, cb)
|
||||
else if (er && er.code === "ENOTDIR")
|
||||
cb(originalEr)
|
||||
else
|
||||
cb(er)
|
||||
})
|
||||
}
|
||||
|
||||
const rmkids = (p, options, cb) => {
|
||||
assert(p)
|
||||
assert(options)
|
||||
assert(typeof cb === 'function')
|
||||
|
||||
options.readdir(p, (er, files) => {
|
||||
if (er)
|
||||
return cb(er)
|
||||
let n = files.length
|
||||
if (n === 0)
|
||||
return options.rmdir(p, cb)
|
||||
let errState
|
||||
files.forEach(f => {
|
||||
rimraf(path.join(p, f), options, er => {
|
||||
if (errState)
|
||||
return
|
||||
if (er)
|
||||
return cb(errState = er)
|
||||
if (--n === 0)
|
||||
options.rmdir(p, cb)
|
||||
})
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
// this looks simpler, and is strictly *faster*, but will
|
||||
// tie up the JavaScript thread and fail on excessively
|
||||
// deep directory trees.
|
||||
const rimrafSync = (p, options) => {
|
||||
options = options || {}
|
||||
defaults(options)
|
||||
|
||||
assert(p, 'rimraf: missing path')
|
||||
assert.equal(typeof p, 'string', 'rimraf: path should be a string')
|
||||
assert(options, 'rimraf: missing options')
|
||||
assert.equal(typeof options, 'object', 'rimraf: options should be object')
|
||||
|
||||
let results
|
||||
|
||||
if (options.disableGlob || !glob.hasMagic(p)) {
|
||||
results = [p]
|
||||
} else {
|
||||
try {
|
||||
options.lstatSync(p)
|
||||
results = [p]
|
||||
} catch (er) {
|
||||
results = glob.sync(p, options.glob)
|
||||
}
|
||||
}
|
||||
|
||||
if (!results.length)
|
||||
return
|
||||
|
||||
for (let i = 0; i < results.length; i++) {
|
||||
const p = results[i]
|
||||
|
||||
let st
|
||||
try {
|
||||
st = options.lstatSync(p)
|
||||
} catch (er) {
|
||||
if (er.code === "ENOENT")
|
||||
return
|
||||
|
||||
// Windows can EPERM on stat. Life is suffering.
|
||||
if (er.code === "EPERM" && isWindows)
|
||||
fixWinEPERMSync(p, options, er)
|
||||
}
|
||||
|
||||
try {
|
||||
// sunos lets the root user unlink directories, which is... weird.
|
||||
if (st && st.isDirectory())
|
||||
rmdirSync(p, options, null)
|
||||
else
|
||||
options.unlinkSync(p)
|
||||
} catch (er) {
|
||||
if (er.code === "ENOENT")
|
||||
return
|
||||
if (er.code === "EPERM")
|
||||
return isWindows ? fixWinEPERMSync(p, options, er) : rmdirSync(p, options, er)
|
||||
if (er.code !== "EISDIR")
|
||||
throw er
|
||||
|
||||
rmdirSync(p, options, er)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const rmdirSync = (p, options, originalEr) => {
|
||||
assert(p)
|
||||
assert(options)
|
||||
|
||||
try {
|
||||
options.rmdirSync(p)
|
||||
} catch (er) {
|
||||
if (er.code === "ENOENT")
|
||||
return
|
||||
if (er.code === "ENOTDIR")
|
||||
throw originalEr
|
||||
if (er.code === "ENOTEMPTY" || er.code === "EEXIST" || er.code === "EPERM")
|
||||
rmkidsSync(p, options)
|
||||
}
|
||||
}
|
||||
|
||||
const rmkidsSync = (p, options) => {
|
||||
assert(p)
|
||||
assert(options)
|
||||
options.readdirSync(p).forEach(f => rimrafSync(path.join(p, f), options))
|
||||
|
||||
// We only end up here once we got ENOTEMPTY at least once, and
|
||||
// at this point, we are guaranteed to have removed all the kids.
|
||||
// So, we know that it won't be ENOENT or ENOTDIR or anything else.
|
||||
// try really hard to delete stuff on windows, because it has a
|
||||
// PROFOUNDLY annoying habit of not closing handles promptly when
|
||||
// files are deleted, resulting in spurious ENOTEMPTY errors.
|
||||
const retries = isWindows ? 100 : 1
|
||||
let i = 0
|
||||
do {
|
||||
let threw = true
|
||||
try {
|
||||
const ret = options.rmdirSync(p, options)
|
||||
threw = false
|
||||
return ret
|
||||
} finally {
|
||||
if (++i < retries && threw)
|
||||
continue
|
||||
}
|
||||
} while (true)
|
||||
}
|
||||
|
||||
module.exports = rimraf
|
||||
rimraf.sync = rimrafSync
|
||||
15
electron/node_modules/cacache/node_modules/tar/LICENSE
generated
vendored
Normal file
15
electron/node_modules/cacache/node_modules/tar/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
The ISC License
|
||||
|
||||
Copyright (c) Isaac Z. Schlueter and Contributors
|
||||
|
||||
Permission to use, copy, modify, and/or distribute this software for any
|
||||
purpose with or without fee is hereby granted, provided that the above
|
||||
copyright notice and this permission notice appear in all copies.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
||||
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
||||
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
||||
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
||||
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR
|
||||
IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
1080
electron/node_modules/cacache/node_modules/tar/README.md
generated
vendored
Normal file
1080
electron/node_modules/cacache/node_modules/tar/README.md
generated
vendored
Normal file
File diff suppressed because it is too large
Load diff
18
electron/node_modules/cacache/node_modules/tar/index.js
generated
vendored
Normal file
18
electron/node_modules/cacache/node_modules/tar/index.js
generated
vendored
Normal file
|
|
@ -0,0 +1,18 @@
|
|||
'use strict'
|
||||
|
||||
// high-level commands
|
||||
exports.c = exports.create = require('./lib/create.js')
|
||||
exports.r = exports.replace = require('./lib/replace.js')
|
||||
exports.t = exports.list = require('./lib/list.js')
|
||||
exports.u = exports.update = require('./lib/update.js')
|
||||
exports.x = exports.extract = require('./lib/extract.js')
|
||||
|
||||
// classes
|
||||
exports.Pack = require('./lib/pack.js')
|
||||
exports.Unpack = require('./lib/unpack.js')
|
||||
exports.Parse = require('./lib/parse.js')
|
||||
exports.ReadEntry = require('./lib/read-entry.js')
|
||||
exports.WriteEntry = require('./lib/write-entry.js')
|
||||
exports.Header = require('./lib/header.js')
|
||||
exports.Pax = require('./lib/pax.js')
|
||||
exports.types = require('./lib/types.js')
|
||||
111
electron/node_modules/cacache/node_modules/tar/lib/create.js
generated
vendored
Normal file
111
electron/node_modules/cacache/node_modules/tar/lib/create.js
generated
vendored
Normal file
|
|
@ -0,0 +1,111 @@
|
|||
'use strict'
|
||||
|
||||
// tar -c
|
||||
const hlo = require('./high-level-opt.js')
|
||||
|
||||
const Pack = require('./pack.js')
|
||||
const fsm = require('fs-minipass')
|
||||
const t = require('./list.js')
|
||||
const path = require('path')
|
||||
|
||||
module.exports = (opt_, files, cb) => {
|
||||
if (typeof files === 'function') {
|
||||
cb = files
|
||||
}
|
||||
|
||||
if (Array.isArray(opt_)) {
|
||||
files = opt_, opt_ = {}
|
||||
}
|
||||
|
||||
if (!files || !Array.isArray(files) || !files.length) {
|
||||
throw new TypeError('no files or directories specified')
|
||||
}
|
||||
|
||||
files = Array.from(files)
|
||||
|
||||
const opt = hlo(opt_)
|
||||
|
||||
if (opt.sync && typeof cb === 'function') {
|
||||
throw new TypeError('callback not supported for sync tar functions')
|
||||
}
|
||||
|
||||
if (!opt.file && typeof cb === 'function') {
|
||||
throw new TypeError('callback only supported with file option')
|
||||
}
|
||||
|
||||
return opt.file && opt.sync ? createFileSync(opt, files)
|
||||
: opt.file ? createFile(opt, files, cb)
|
||||
: opt.sync ? createSync(opt, files)
|
||||
: create(opt, files)
|
||||
}
|
||||
|
||||
const createFileSync = (opt, files) => {
|
||||
const p = new Pack.Sync(opt)
|
||||
const stream = new fsm.WriteStreamSync(opt.file, {
|
||||
mode: opt.mode || 0o666,
|
||||
})
|
||||
p.pipe(stream)
|
||||
addFilesSync(p, files)
|
||||
}
|
||||
|
||||
const createFile = (opt, files, cb) => {
|
||||
const p = new Pack(opt)
|
||||
const stream = new fsm.WriteStream(opt.file, {
|
||||
mode: opt.mode || 0o666,
|
||||
})
|
||||
p.pipe(stream)
|
||||
|
||||
const promise = new Promise((res, rej) => {
|
||||
stream.on('error', rej)
|
||||
stream.on('close', res)
|
||||
p.on('error', rej)
|
||||
})
|
||||
|
||||
addFilesAsync(p, files)
|
||||
|
||||
return cb ? promise.then(cb, cb) : promise
|
||||
}
|
||||
|
||||
const addFilesSync = (p, files) => {
|
||||
files.forEach(file => {
|
||||
if (file.charAt(0) === '@') {
|
||||
t({
|
||||
file: path.resolve(p.cwd, file.slice(1)),
|
||||
sync: true,
|
||||
noResume: true,
|
||||
onentry: entry => p.add(entry),
|
||||
})
|
||||
} else {
|
||||
p.add(file)
|
||||
}
|
||||
})
|
||||
p.end()
|
||||
}
|
||||
|
||||
const addFilesAsync = (p, files) => {
|
||||
while (files.length) {
|
||||
const file = files.shift()
|
||||
if (file.charAt(0) === '@') {
|
||||
return t({
|
||||
file: path.resolve(p.cwd, file.slice(1)),
|
||||
noResume: true,
|
||||
onentry: entry => p.add(entry),
|
||||
}).then(_ => addFilesAsync(p, files))
|
||||
} else {
|
||||
p.add(file)
|
||||
}
|
||||
}
|
||||
p.end()
|
||||
}
|
||||
|
||||
const createSync = (opt, files) => {
|
||||
const p = new Pack.Sync(opt)
|
||||
addFilesSync(p, files)
|
||||
return p
|
||||
}
|
||||
|
||||
const create = (opt, files) => {
|
||||
const p = new Pack(opt)
|
||||
addFilesAsync(p, files)
|
||||
return p
|
||||
}
|
||||
113
electron/node_modules/cacache/node_modules/tar/lib/extract.js
generated
vendored
Normal file
113
electron/node_modules/cacache/node_modules/tar/lib/extract.js
generated
vendored
Normal file
|
|
@ -0,0 +1,113 @@
|
|||
'use strict'
|
||||
|
||||
// tar -x
|
||||
const hlo = require('./high-level-opt.js')
|
||||
const Unpack = require('./unpack.js')
|
||||
const fs = require('fs')
|
||||
const fsm = require('fs-minipass')
|
||||
const path = require('path')
|
||||
const stripSlash = require('./strip-trailing-slashes.js')
|
||||
|
||||
module.exports = (opt_, files, cb) => {
|
||||
if (typeof opt_ === 'function') {
|
||||
cb = opt_, files = null, opt_ = {}
|
||||
} else if (Array.isArray(opt_)) {
|
||||
files = opt_, opt_ = {}
|
||||
}
|
||||
|
||||
if (typeof files === 'function') {
|
||||
cb = files, files = null
|
||||
}
|
||||
|
||||
if (!files) {
|
||||
files = []
|
||||
} else {
|
||||
files = Array.from(files)
|
||||
}
|
||||
|
||||
const opt = hlo(opt_)
|
||||
|
||||
if (opt.sync && typeof cb === 'function') {
|
||||
throw new TypeError('callback not supported for sync tar functions')
|
||||
}
|
||||
|
||||
if (!opt.file && typeof cb === 'function') {
|
||||
throw new TypeError('callback only supported with file option')
|
||||
}
|
||||
|
||||
if (files.length) {
|
||||
filesFilter(opt, files)
|
||||
}
|
||||
|
||||
return opt.file && opt.sync ? extractFileSync(opt)
|
||||
: opt.file ? extractFile(opt, cb)
|
||||
: opt.sync ? extractSync(opt)
|
||||
: extract(opt)
|
||||
}
|
||||
|
||||
// construct a filter that limits the file entries listed
|
||||
// include child entries if a dir is included
|
||||
const filesFilter = (opt, files) => {
|
||||
const map = new Map(files.map(f => [stripSlash(f), true]))
|
||||
const filter = opt.filter
|
||||
|
||||
const mapHas = (file, r) => {
|
||||
const root = r || path.parse(file).root || '.'
|
||||
const ret = file === root ? false
|
||||
: map.has(file) ? map.get(file)
|
||||
: mapHas(path.dirname(file), root)
|
||||
|
||||
map.set(file, ret)
|
||||
return ret
|
||||
}
|
||||
|
||||
opt.filter = filter
|
||||
? (file, entry) => filter(file, entry) && mapHas(stripSlash(file))
|
||||
: file => mapHas(stripSlash(file))
|
||||
}
|
||||
|
||||
const extractFileSync = opt => {
|
||||
const u = new Unpack.Sync(opt)
|
||||
|
||||
const file = opt.file
|
||||
const stat = fs.statSync(file)
|
||||
// This trades a zero-byte read() syscall for a stat
|
||||
// However, it will usually result in less memory allocation
|
||||
const readSize = opt.maxReadSize || 16 * 1024 * 1024
|
||||
const stream = new fsm.ReadStreamSync(file, {
|
||||
readSize: readSize,
|
||||
size: stat.size,
|
||||
})
|
||||
stream.pipe(u)
|
||||
}
|
||||
|
||||
const extractFile = (opt, cb) => {
|
||||
const u = new Unpack(opt)
|
||||
const readSize = opt.maxReadSize || 16 * 1024 * 1024
|
||||
|
||||
const file = opt.file
|
||||
const p = new Promise((resolve, reject) => {
|
||||
u.on('error', reject)
|
||||
u.on('close', resolve)
|
||||
|
||||
// This trades a zero-byte read() syscall for a stat
|
||||
// However, it will usually result in less memory allocation
|
||||
fs.stat(file, (er, stat) => {
|
||||
if (er) {
|
||||
reject(er)
|
||||
} else {
|
||||
const stream = new fsm.ReadStream(file, {
|
||||
readSize: readSize,
|
||||
size: stat.size,
|
||||
})
|
||||
stream.on('error', reject)
|
||||
stream.pipe(u)
|
||||
}
|
||||
})
|
||||
})
|
||||
return cb ? p.then(cb, cb) : p
|
||||
}
|
||||
|
||||
const extractSync = opt => new Unpack.Sync(opt)
|
||||
|
||||
const extract = opt => new Unpack(opt)
|
||||
20
electron/node_modules/cacache/node_modules/tar/lib/get-write-flag.js
generated
vendored
Normal file
20
electron/node_modules/cacache/node_modules/tar/lib/get-write-flag.js
generated
vendored
Normal file
|
|
@ -0,0 +1,20 @@
|
|||
// Get the appropriate flag to use for creating files
|
||||
// We use fmap on Windows platforms for files less than
|
||||
// 512kb. This is a fairly low limit, but avoids making
|
||||
// things slower in some cases. Since most of what this
|
||||
// library is used for is extracting tarballs of many
|
||||
// relatively small files in npm packages and the like,
|
||||
// it can be a big boost on Windows platforms.
|
||||
// Only supported in Node v12.9.0 and above.
|
||||
const platform = process.env.__FAKE_PLATFORM__ || process.platform
|
||||
const isWindows = platform === 'win32'
|
||||
const fs = global.__FAKE_TESTING_FS__ || require('fs')
|
||||
|
||||
/* istanbul ignore next */
|
||||
const { O_CREAT, O_TRUNC, O_WRONLY, UV_FS_O_FILEMAP = 0 } = fs.constants
|
||||
|
||||
const fMapEnabled = isWindows && !!UV_FS_O_FILEMAP
|
||||
const fMapLimit = 512 * 1024
|
||||
const fMapFlag = UV_FS_O_FILEMAP | O_TRUNC | O_CREAT | O_WRONLY
|
||||
module.exports = !fMapEnabled ? () => 'w'
|
||||
: size => size < fMapLimit ? fMapFlag : 'w'
|
||||
304
electron/node_modules/cacache/node_modules/tar/lib/header.js
generated
vendored
Normal file
304
electron/node_modules/cacache/node_modules/tar/lib/header.js
generated
vendored
Normal file
|
|
@ -0,0 +1,304 @@
|
|||
'use strict'
|
||||
// parse a 512-byte header block to a data object, or vice-versa
|
||||
// encode returns `true` if a pax extended header is needed, because
|
||||
// the data could not be faithfully encoded in a simple header.
|
||||
// (Also, check header.needPax to see if it needs a pax header.)
|
||||
|
||||
const types = require('./types.js')
|
||||
const pathModule = require('path').posix
|
||||
const large = require('./large-numbers.js')
|
||||
|
||||
const SLURP = Symbol('slurp')
|
||||
const TYPE = Symbol('type')
|
||||
|
||||
class Header {
|
||||
constructor (data, off, ex, gex) {
|
||||
this.cksumValid = false
|
||||
this.needPax = false
|
||||
this.nullBlock = false
|
||||
|
||||
this.block = null
|
||||
this.path = null
|
||||
this.mode = null
|
||||
this.uid = null
|
||||
this.gid = null
|
||||
this.size = null
|
||||
this.mtime = null
|
||||
this.cksum = null
|
||||
this[TYPE] = '0'
|
||||
this.linkpath = null
|
||||
this.uname = null
|
||||
this.gname = null
|
||||
this.devmaj = 0
|
||||
this.devmin = 0
|
||||
this.atime = null
|
||||
this.ctime = null
|
||||
|
||||
if (Buffer.isBuffer(data)) {
|
||||
this.decode(data, off || 0, ex, gex)
|
||||
} else if (data) {
|
||||
this.set(data)
|
||||
}
|
||||
}
|
||||
|
||||
decode (buf, off, ex, gex) {
|
||||
if (!off) {
|
||||
off = 0
|
||||
}
|
||||
|
||||
if (!buf || !(buf.length >= off + 512)) {
|
||||
throw new Error('need 512 bytes for header')
|
||||
}
|
||||
|
||||
this.path = decString(buf, off, 100)
|
||||
this.mode = decNumber(buf, off + 100, 8)
|
||||
this.uid = decNumber(buf, off + 108, 8)
|
||||
this.gid = decNumber(buf, off + 116, 8)
|
||||
this.size = decNumber(buf, off + 124, 12)
|
||||
this.mtime = decDate(buf, off + 136, 12)
|
||||
this.cksum = decNumber(buf, off + 148, 12)
|
||||
|
||||
// if we have extended or global extended headers, apply them now
|
||||
// See https://github.com/npm/node-tar/pull/187
|
||||
this[SLURP](ex)
|
||||
this[SLURP](gex, true)
|
||||
|
||||
// old tar versions marked dirs as a file with a trailing /
|
||||
this[TYPE] = decString(buf, off + 156, 1)
|
||||
if (this[TYPE] === '') {
|
||||
this[TYPE] = '0'
|
||||
}
|
||||
if (this[TYPE] === '0' && this.path.slice(-1) === '/') {
|
||||
this[TYPE] = '5'
|
||||
}
|
||||
|
||||
// tar implementations sometimes incorrectly put the stat(dir).size
|
||||
// as the size in the tarball, even though Directory entries are
|
||||
// not able to have any body at all. In the very rare chance that
|
||||
// it actually DOES have a body, we weren't going to do anything with
|
||||
// it anyway, and it'll just be a warning about an invalid header.
|
||||
if (this[TYPE] === '5') {
|
||||
this.size = 0
|
||||
}
|
||||
|
||||
this.linkpath = decString(buf, off + 157, 100)
|
||||
if (buf.slice(off + 257, off + 265).toString() === 'ustar\u000000') {
|
||||
this.uname = decString(buf, off + 265, 32)
|
||||
this.gname = decString(buf, off + 297, 32)
|
||||
this.devmaj = decNumber(buf, off + 329, 8)
|
||||
this.devmin = decNumber(buf, off + 337, 8)
|
||||
if (buf[off + 475] !== 0) {
|
||||
// definitely a prefix, definitely >130 chars.
|
||||
const prefix = decString(buf, off + 345, 155)
|
||||
this.path = prefix + '/' + this.path
|
||||
} else {
|
||||
const prefix = decString(buf, off + 345, 130)
|
||||
if (prefix) {
|
||||
this.path = prefix + '/' + this.path
|
||||
}
|
||||
this.atime = decDate(buf, off + 476, 12)
|
||||
this.ctime = decDate(buf, off + 488, 12)
|
||||
}
|
||||
}
|
||||
|
||||
let sum = 8 * 0x20
|
||||
for (let i = off; i < off + 148; i++) {
|
||||
sum += buf[i]
|
||||
}
|
||||
|
||||
for (let i = off + 156; i < off + 512; i++) {
|
||||
sum += buf[i]
|
||||
}
|
||||
|
||||
this.cksumValid = sum === this.cksum
|
||||
if (this.cksum === null && sum === 8 * 0x20) {
|
||||
this.nullBlock = true
|
||||
}
|
||||
}
|
||||
|
||||
[SLURP] (ex, global) {
|
||||
for (const k in ex) {
|
||||
// we slurp in everything except for the path attribute in
|
||||
// a global extended header, because that's weird.
|
||||
if (ex[k] !== null && ex[k] !== undefined &&
|
||||
!(global && k === 'path')) {
|
||||
this[k] = ex[k]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
encode (buf, off) {
|
||||
if (!buf) {
|
||||
buf = this.block = Buffer.alloc(512)
|
||||
off = 0
|
||||
}
|
||||
|
||||
if (!off) {
|
||||
off = 0
|
||||
}
|
||||
|
||||
if (!(buf.length >= off + 512)) {
|
||||
throw new Error('need 512 bytes for header')
|
||||
}
|
||||
|
||||
const prefixSize = this.ctime || this.atime ? 130 : 155
|
||||
const split = splitPrefix(this.path || '', prefixSize)
|
||||
const path = split[0]
|
||||
const prefix = split[1]
|
||||
this.needPax = split[2]
|
||||
|
||||
this.needPax = encString(buf, off, 100, path) || this.needPax
|
||||
this.needPax = encNumber(buf, off + 100, 8, this.mode) || this.needPax
|
||||
this.needPax = encNumber(buf, off + 108, 8, this.uid) || this.needPax
|
||||
this.needPax = encNumber(buf, off + 116, 8, this.gid) || this.needPax
|
||||
this.needPax = encNumber(buf, off + 124, 12, this.size) || this.needPax
|
||||
this.needPax = encDate(buf, off + 136, 12, this.mtime) || this.needPax
|
||||
buf[off + 156] = this[TYPE].charCodeAt(0)
|
||||
this.needPax = encString(buf, off + 157, 100, this.linkpath) || this.needPax
|
||||
buf.write('ustar\u000000', off + 257, 8)
|
||||
this.needPax = encString(buf, off + 265, 32, this.uname) || this.needPax
|
||||
this.needPax = encString(buf, off + 297, 32, this.gname) || this.needPax
|
||||
this.needPax = encNumber(buf, off + 329, 8, this.devmaj) || this.needPax
|
||||
this.needPax = encNumber(buf, off + 337, 8, this.devmin) || this.needPax
|
||||
this.needPax = encString(buf, off + 345, prefixSize, prefix) || this.needPax
|
||||
if (buf[off + 475] !== 0) {
|
||||
this.needPax = encString(buf, off + 345, 155, prefix) || this.needPax
|
||||
} else {
|
||||
this.needPax = encString(buf, off + 345, 130, prefix) || this.needPax
|
||||
this.needPax = encDate(buf, off + 476, 12, this.atime) || this.needPax
|
||||
this.needPax = encDate(buf, off + 488, 12, this.ctime) || this.needPax
|
||||
}
|
||||
|
||||
let sum = 8 * 0x20
|
||||
for (let i = off; i < off + 148; i++) {
|
||||
sum += buf[i]
|
||||
}
|
||||
|
||||
for (let i = off + 156; i < off + 512; i++) {
|
||||
sum += buf[i]
|
||||
}
|
||||
|
||||
this.cksum = sum
|
||||
encNumber(buf, off + 148, 8, this.cksum)
|
||||
this.cksumValid = true
|
||||
|
||||
return this.needPax
|
||||
}
|
||||
|
||||
set (data) {
|
||||
for (const i in data) {
|
||||
if (data[i] !== null && data[i] !== undefined) {
|
||||
this[i] = data[i]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
get type () {
|
||||
return types.name.get(this[TYPE]) || this[TYPE]
|
||||
}
|
||||
|
||||
get typeKey () {
|
||||
return this[TYPE]
|
||||
}
|
||||
|
||||
set type (type) {
|
||||
if (types.code.has(type)) {
|
||||
this[TYPE] = types.code.get(type)
|
||||
} else {
|
||||
this[TYPE] = type
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const splitPrefix = (p, prefixSize) => {
|
||||
const pathSize = 100
|
||||
let pp = p
|
||||
let prefix = ''
|
||||
let ret
|
||||
const root = pathModule.parse(p).root || '.'
|
||||
|
||||
if (Buffer.byteLength(pp) < pathSize) {
|
||||
ret = [pp, prefix, false]
|
||||
} else {
|
||||
// first set prefix to the dir, and path to the base
|
||||
prefix = pathModule.dirname(pp)
|
||||
pp = pathModule.basename(pp)
|
||||
|
||||
do {
|
||||
if (Buffer.byteLength(pp) <= pathSize &&
|
||||
Buffer.byteLength(prefix) <= prefixSize) {
|
||||
// both fit!
|
||||
ret = [pp, prefix, false]
|
||||
} else if (Buffer.byteLength(pp) > pathSize &&
|
||||
Buffer.byteLength(prefix) <= prefixSize) {
|
||||
// prefix fits in prefix, but path doesn't fit in path
|
||||
ret = [pp.slice(0, pathSize - 1), prefix, true]
|
||||
} else {
|
||||
// make path take a bit from prefix
|
||||
pp = pathModule.join(pathModule.basename(prefix), pp)
|
||||
prefix = pathModule.dirname(prefix)
|
||||
}
|
||||
} while (prefix !== root && !ret)
|
||||
|
||||
// at this point, found no resolution, just truncate
|
||||
if (!ret) {
|
||||
ret = [p.slice(0, pathSize - 1), '', true]
|
||||
}
|
||||
}
|
||||
return ret
|
||||
}
|
||||
|
||||
const decString = (buf, off, size) =>
|
||||
buf.slice(off, off + size).toString('utf8').replace(/\0.*/, '')
|
||||
|
||||
const decDate = (buf, off, size) =>
|
||||
numToDate(decNumber(buf, off, size))
|
||||
|
||||
const numToDate = num => num === null ? null : new Date(num * 1000)
|
||||
|
||||
const decNumber = (buf, off, size) =>
|
||||
buf[off] & 0x80 ? large.parse(buf.slice(off, off + size))
|
||||
: decSmallNumber(buf, off, size)
|
||||
|
||||
const nanNull = value => isNaN(value) ? null : value
|
||||
|
||||
const decSmallNumber = (buf, off, size) =>
|
||||
nanNull(parseInt(
|
||||
buf.slice(off, off + size)
|
||||
.toString('utf8').replace(/\0.*$/, '').trim(), 8))
|
||||
|
||||
// the maximum encodable as a null-terminated octal, by field size
|
||||
const MAXNUM = {
|
||||
12: 0o77777777777,
|
||||
8: 0o7777777,
|
||||
}
|
||||
|
||||
const encNumber = (buf, off, size, number) =>
|
||||
number === null ? false :
|
||||
number > MAXNUM[size] || number < 0
|
||||
? (large.encode(number, buf.slice(off, off + size)), true)
|
||||
: (encSmallNumber(buf, off, size, number), false)
|
||||
|
||||
const encSmallNumber = (buf, off, size, number) =>
|
||||
buf.write(octalString(number, size), off, size, 'ascii')
|
||||
|
||||
const octalString = (number, size) =>
|
||||
padOctal(Math.floor(number).toString(8), size)
|
||||
|
||||
const padOctal = (string, size) =>
|
||||
(string.length === size - 1 ? string
|
||||
: new Array(size - string.length - 1).join('0') + string + ' ') + '\0'
|
||||
|
||||
const encDate = (buf, off, size, date) =>
|
||||
date === null ? false :
|
||||
encNumber(buf, off, size, date.getTime() / 1000)
|
||||
|
||||
// enough to fill the longest string we've got
|
||||
const NULLS = new Array(156).join('\0')
|
||||
// pad with nulls, return true if it's longer or non-ascii
|
||||
const encString = (buf, off, size, string) =>
|
||||
string === null ? false :
|
||||
(buf.write(string + NULLS, off, size, 'utf8'),
|
||||
string.length !== Buffer.byteLength(string) || string.length > size)
|
||||
|
||||
module.exports = Header
|
||||
29
electron/node_modules/cacache/node_modules/tar/lib/high-level-opt.js
generated
vendored
Normal file
29
electron/node_modules/cacache/node_modules/tar/lib/high-level-opt.js
generated
vendored
Normal file
|
|
@ -0,0 +1,29 @@
|
|||
'use strict'
|
||||
|
||||
// turn tar(1) style args like `C` into the more verbose things like `cwd`
|
||||
|
||||
const argmap = new Map([
|
||||
['C', 'cwd'],
|
||||
['f', 'file'],
|
||||
['z', 'gzip'],
|
||||
['P', 'preservePaths'],
|
||||
['U', 'unlink'],
|
||||
['strip-components', 'strip'],
|
||||
['stripComponents', 'strip'],
|
||||
['keep-newer', 'newer'],
|
||||
['keepNewer', 'newer'],
|
||||
['keep-newer-files', 'newer'],
|
||||
['keepNewerFiles', 'newer'],
|
||||
['k', 'keep'],
|
||||
['keep-existing', 'keep'],
|
||||
['keepExisting', 'keep'],
|
||||
['m', 'noMtime'],
|
||||
['no-mtime', 'noMtime'],
|
||||
['p', 'preserveOwner'],
|
||||
['L', 'follow'],
|
||||
['h', 'follow'],
|
||||
])
|
||||
|
||||
module.exports = opt => opt ? Object.keys(opt).map(k => [
|
||||
argmap.has(k) ? argmap.get(k) : k, opt[k],
|
||||
]).reduce((set, kv) => (set[kv[0]] = kv[1], set), Object.create(null)) : {}
|
||||
104
electron/node_modules/cacache/node_modules/tar/lib/large-numbers.js
generated
vendored
Normal file
104
electron/node_modules/cacache/node_modules/tar/lib/large-numbers.js
generated
vendored
Normal file
|
|
@ -0,0 +1,104 @@
|
|||
'use strict'
|
||||
// Tar can encode large and negative numbers using a leading byte of
|
||||
// 0xff for negative, and 0x80 for positive.
|
||||
|
||||
const encode = (num, buf) => {
|
||||
if (!Number.isSafeInteger(num)) {
|
||||
// The number is so large that javascript cannot represent it with integer
|
||||
// precision.
|
||||
throw Error('cannot encode number outside of javascript safe integer range')
|
||||
} else if (num < 0) {
|
||||
encodeNegative(num, buf)
|
||||
} else {
|
||||
encodePositive(num, buf)
|
||||
}
|
||||
return buf
|
||||
}
|
||||
|
||||
const encodePositive = (num, buf) => {
|
||||
buf[0] = 0x80
|
||||
|
||||
for (var i = buf.length; i > 1; i--) {
|
||||
buf[i - 1] = num & 0xff
|
||||
num = Math.floor(num / 0x100)
|
||||
}
|
||||
}
|
||||
|
||||
const encodeNegative = (num, buf) => {
|
||||
buf[0] = 0xff
|
||||
var flipped = false
|
||||
num = num * -1
|
||||
for (var i = buf.length; i > 1; i--) {
|
||||
var byte = num & 0xff
|
||||
num = Math.floor(num / 0x100)
|
||||
if (flipped) {
|
||||
buf[i - 1] = onesComp(byte)
|
||||
} else if (byte === 0) {
|
||||
buf[i - 1] = 0
|
||||
} else {
|
||||
flipped = true
|
||||
buf[i - 1] = twosComp(byte)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const parse = (buf) => {
|
||||
const pre = buf[0]
|
||||
const value = pre === 0x80 ? pos(buf.slice(1, buf.length))
|
||||
: pre === 0xff ? twos(buf)
|
||||
: null
|
||||
if (value === null) {
|
||||
throw Error('invalid base256 encoding')
|
||||
}
|
||||
|
||||
if (!Number.isSafeInteger(value)) {
|
||||
// The number is so large that javascript cannot represent it with integer
|
||||
// precision.
|
||||
throw Error('parsed number outside of javascript safe integer range')
|
||||
}
|
||||
|
||||
return value
|
||||
}
|
||||
|
||||
const twos = (buf) => {
|
||||
var len = buf.length
|
||||
var sum = 0
|
||||
var flipped = false
|
||||
for (var i = len - 1; i > -1; i--) {
|
||||
var byte = buf[i]
|
||||
var f
|
||||
if (flipped) {
|
||||
f = onesComp(byte)
|
||||
} else if (byte === 0) {
|
||||
f = byte
|
||||
} else {
|
||||
flipped = true
|
||||
f = twosComp(byte)
|
||||
}
|
||||
if (f !== 0) {
|
||||
sum -= f * Math.pow(256, len - i - 1)
|
||||
}
|
||||
}
|
||||
return sum
|
||||
}
|
||||
|
||||
const pos = (buf) => {
|
||||
var len = buf.length
|
||||
var sum = 0
|
||||
for (var i = len - 1; i > -1; i--) {
|
||||
var byte = buf[i]
|
||||
if (byte !== 0) {
|
||||
sum += byte * Math.pow(256, len - i - 1)
|
||||
}
|
||||
}
|
||||
return sum
|
||||
}
|
||||
|
||||
const onesComp = byte => (0xff ^ byte) & 0xff
|
||||
|
||||
const twosComp = byte => ((0xff ^ byte) + 1) & 0xff
|
||||
|
||||
module.exports = {
|
||||
encode,
|
||||
parse,
|
||||
}
|
||||
139
electron/node_modules/cacache/node_modules/tar/lib/list.js
generated
vendored
Normal file
139
electron/node_modules/cacache/node_modules/tar/lib/list.js
generated
vendored
Normal file
|
|
@ -0,0 +1,139 @@
|
|||
'use strict'
|
||||
|
||||
// XXX: This shares a lot in common with extract.js
|
||||
// maybe some DRY opportunity here?
|
||||
|
||||
// tar -t
|
||||
const hlo = require('./high-level-opt.js')
|
||||
const Parser = require('./parse.js')
|
||||
const fs = require('fs')
|
||||
const fsm = require('fs-minipass')
|
||||
const path = require('path')
|
||||
const stripSlash = require('./strip-trailing-slashes.js')
|
||||
|
||||
module.exports = (opt_, files, cb) => {
|
||||
if (typeof opt_ === 'function') {
|
||||
cb = opt_, files = null, opt_ = {}
|
||||
} else if (Array.isArray(opt_)) {
|
||||
files = opt_, opt_ = {}
|
||||
}
|
||||
|
||||
if (typeof files === 'function') {
|
||||
cb = files, files = null
|
||||
}
|
||||
|
||||
if (!files) {
|
||||
files = []
|
||||
} else {
|
||||
files = Array.from(files)
|
||||
}
|
||||
|
||||
const opt = hlo(opt_)
|
||||
|
||||
if (opt.sync && typeof cb === 'function') {
|
||||
throw new TypeError('callback not supported for sync tar functions')
|
||||
}
|
||||
|
||||
if (!opt.file && typeof cb === 'function') {
|
||||
throw new TypeError('callback only supported with file option')
|
||||
}
|
||||
|
||||
if (files.length) {
|
||||
filesFilter(opt, files)
|
||||
}
|
||||
|
||||
if (!opt.noResume) {
|
||||
onentryFunction(opt)
|
||||
}
|
||||
|
||||
return opt.file && opt.sync ? listFileSync(opt)
|
||||
: opt.file ? listFile(opt, cb)
|
||||
: list(opt)
|
||||
}
|
||||
|
||||
const onentryFunction = opt => {
|
||||
const onentry = opt.onentry
|
||||
opt.onentry = onentry ? e => {
|
||||
onentry(e)
|
||||
e.resume()
|
||||
} : e => e.resume()
|
||||
}
|
||||
|
||||
// construct a filter that limits the file entries listed
|
||||
// include child entries if a dir is included
|
||||
const filesFilter = (opt, files) => {
|
||||
const map = new Map(files.map(f => [stripSlash(f), true]))
|
||||
const filter = opt.filter
|
||||
|
||||
const mapHas = (file, r) => {
|
||||
const root = r || path.parse(file).root || '.'
|
||||
const ret = file === root ? false
|
||||
: map.has(file) ? map.get(file)
|
||||
: mapHas(path.dirname(file), root)
|
||||
|
||||
map.set(file, ret)
|
||||
return ret
|
||||
}
|
||||
|
||||
opt.filter = filter
|
||||
? (file, entry) => filter(file, entry) && mapHas(stripSlash(file))
|
||||
: file => mapHas(stripSlash(file))
|
||||
}
|
||||
|
||||
const listFileSync = opt => {
|
||||
const p = list(opt)
|
||||
const file = opt.file
|
||||
let threw = true
|
||||
let fd
|
||||
try {
|
||||
const stat = fs.statSync(file)
|
||||
const readSize = opt.maxReadSize || 16 * 1024 * 1024
|
||||
if (stat.size < readSize) {
|
||||
p.end(fs.readFileSync(file))
|
||||
} else {
|
||||
let pos = 0
|
||||
const buf = Buffer.allocUnsafe(readSize)
|
||||
fd = fs.openSync(file, 'r')
|
||||
while (pos < stat.size) {
|
||||
const bytesRead = fs.readSync(fd, buf, 0, readSize, pos)
|
||||
pos += bytesRead
|
||||
p.write(buf.slice(0, bytesRead))
|
||||
}
|
||||
p.end()
|
||||
}
|
||||
threw = false
|
||||
} finally {
|
||||
if (threw && fd) {
|
||||
try {
|
||||
fs.closeSync(fd)
|
||||
} catch (er) {}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const listFile = (opt, cb) => {
|
||||
const parse = new Parser(opt)
|
||||
const readSize = opt.maxReadSize || 16 * 1024 * 1024
|
||||
|
||||
const file = opt.file
|
||||
const p = new Promise((resolve, reject) => {
|
||||
parse.on('error', reject)
|
||||
parse.on('end', resolve)
|
||||
|
||||
fs.stat(file, (er, stat) => {
|
||||
if (er) {
|
||||
reject(er)
|
||||
} else {
|
||||
const stream = new fsm.ReadStream(file, {
|
||||
readSize: readSize,
|
||||
size: stat.size,
|
||||
})
|
||||
stream.on('error', reject)
|
||||
stream.pipe(parse)
|
||||
}
|
||||
})
|
||||
})
|
||||
return cb ? p.then(cb, cb) : p
|
||||
}
|
||||
|
||||
const list = opt => new Parser(opt)
|
||||
229
electron/node_modules/cacache/node_modules/tar/lib/mkdir.js
generated
vendored
Normal file
229
electron/node_modules/cacache/node_modules/tar/lib/mkdir.js
generated
vendored
Normal file
|
|
@ -0,0 +1,229 @@
|
|||
'use strict'
|
||||
// wrapper around mkdirp for tar's needs.
|
||||
|
||||
// TODO: This should probably be a class, not functionally
|
||||
// passing around state in a gazillion args.
|
||||
|
||||
const mkdirp = require('mkdirp')
|
||||
const fs = require('fs')
|
||||
const path = require('path')
|
||||
const chownr = require('chownr')
|
||||
const normPath = require('./normalize-windows-path.js')
|
||||
|
||||
class SymlinkError extends Error {
|
||||
constructor (symlink, path) {
|
||||
super('Cannot extract through symbolic link')
|
||||
this.path = path
|
||||
this.symlink = symlink
|
||||
}
|
||||
|
||||
get name () {
|
||||
return 'SylinkError'
|
||||
}
|
||||
}
|
||||
|
||||
class CwdError extends Error {
|
||||
constructor (path, code) {
|
||||
super(code + ': Cannot cd into \'' + path + '\'')
|
||||
this.path = path
|
||||
this.code = code
|
||||
}
|
||||
|
||||
get name () {
|
||||
return 'CwdError'
|
||||
}
|
||||
}
|
||||
|
||||
const cGet = (cache, key) => cache.get(normPath(key))
|
||||
const cSet = (cache, key, val) => cache.set(normPath(key), val)
|
||||
|
||||
const checkCwd = (dir, cb) => {
|
||||
fs.stat(dir, (er, st) => {
|
||||
if (er || !st.isDirectory()) {
|
||||
er = new CwdError(dir, er && er.code || 'ENOTDIR')
|
||||
}
|
||||
cb(er)
|
||||
})
|
||||
}
|
||||
|
||||
module.exports = (dir, opt, cb) => {
|
||||
dir = normPath(dir)
|
||||
|
||||
// if there's any overlap between mask and mode,
|
||||
// then we'll need an explicit chmod
|
||||
const umask = opt.umask
|
||||
const mode = opt.mode | 0o0700
|
||||
const needChmod = (mode & umask) !== 0
|
||||
|
||||
const uid = opt.uid
|
||||
const gid = opt.gid
|
||||
const doChown = typeof uid === 'number' &&
|
||||
typeof gid === 'number' &&
|
||||
(uid !== opt.processUid || gid !== opt.processGid)
|
||||
|
||||
const preserve = opt.preserve
|
||||
const unlink = opt.unlink
|
||||
const cache = opt.cache
|
||||
const cwd = normPath(opt.cwd)
|
||||
|
||||
const done = (er, created) => {
|
||||
if (er) {
|
||||
cb(er)
|
||||
} else {
|
||||
cSet(cache, dir, true)
|
||||
if (created && doChown) {
|
||||
chownr(created, uid, gid, er => done(er))
|
||||
} else if (needChmod) {
|
||||
fs.chmod(dir, mode, cb)
|
||||
} else {
|
||||
cb()
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (cache && cGet(cache, dir) === true) {
|
||||
return done()
|
||||
}
|
||||
|
||||
if (dir === cwd) {
|
||||
return checkCwd(dir, done)
|
||||
}
|
||||
|
||||
if (preserve) {
|
||||
return mkdirp(dir, { mode }).then(made => done(null, made), done)
|
||||
}
|
||||
|
||||
const sub = normPath(path.relative(cwd, dir))
|
||||
const parts = sub.split('/')
|
||||
mkdir_(cwd, parts, mode, cache, unlink, cwd, null, done)
|
||||
}
|
||||
|
||||
const mkdir_ = (base, parts, mode, cache, unlink, cwd, created, cb) => {
|
||||
if (!parts.length) {
|
||||
return cb(null, created)
|
||||
}
|
||||
const p = parts.shift()
|
||||
const part = normPath(path.resolve(base + '/' + p))
|
||||
if (cGet(cache, part)) {
|
||||
return mkdir_(part, parts, mode, cache, unlink, cwd, created, cb)
|
||||
}
|
||||
fs.mkdir(part, mode, onmkdir(part, parts, mode, cache, unlink, cwd, created, cb))
|
||||
}
|
||||
|
||||
const onmkdir = (part, parts, mode, cache, unlink, cwd, created, cb) => er => {
|
||||
if (er) {
|
||||
fs.lstat(part, (statEr, st) => {
|
||||
if (statEr) {
|
||||
statEr.path = statEr.path && normPath(statEr.path)
|
||||
cb(statEr)
|
||||
} else if (st.isDirectory()) {
|
||||
mkdir_(part, parts, mode, cache, unlink, cwd, created, cb)
|
||||
} else if (unlink) {
|
||||
fs.unlink(part, er => {
|
||||
if (er) {
|
||||
return cb(er)
|
||||
}
|
||||
fs.mkdir(part, mode, onmkdir(part, parts, mode, cache, unlink, cwd, created, cb))
|
||||
})
|
||||
} else if (st.isSymbolicLink()) {
|
||||
return cb(new SymlinkError(part, part + '/' + parts.join('/')))
|
||||
} else {
|
||||
cb(er)
|
||||
}
|
||||
})
|
||||
} else {
|
||||
created = created || part
|
||||
mkdir_(part, parts, mode, cache, unlink, cwd, created, cb)
|
||||
}
|
||||
}
|
||||
|
||||
const checkCwdSync = dir => {
|
||||
let ok = false
|
||||
let code = 'ENOTDIR'
|
||||
try {
|
||||
ok = fs.statSync(dir).isDirectory()
|
||||
} catch (er) {
|
||||
code = er.code
|
||||
} finally {
|
||||
if (!ok) {
|
||||
throw new CwdError(dir, code)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
module.exports.sync = (dir, opt) => {
|
||||
dir = normPath(dir)
|
||||
// if there's any overlap between mask and mode,
|
||||
// then we'll need an explicit chmod
|
||||
const umask = opt.umask
|
||||
const mode = opt.mode | 0o0700
|
||||
const needChmod = (mode & umask) !== 0
|
||||
|
||||
const uid = opt.uid
|
||||
const gid = opt.gid
|
||||
const doChown = typeof uid === 'number' &&
|
||||
typeof gid === 'number' &&
|
||||
(uid !== opt.processUid || gid !== opt.processGid)
|
||||
|
||||
const preserve = opt.preserve
|
||||
const unlink = opt.unlink
|
||||
const cache = opt.cache
|
||||
const cwd = normPath(opt.cwd)
|
||||
|
||||
const done = (created) => {
|
||||
cSet(cache, dir, true)
|
||||
if (created && doChown) {
|
||||
chownr.sync(created, uid, gid)
|
||||
}
|
||||
if (needChmod) {
|
||||
fs.chmodSync(dir, mode)
|
||||
}
|
||||
}
|
||||
|
||||
if (cache && cGet(cache, dir) === true) {
|
||||
return done()
|
||||
}
|
||||
|
||||
if (dir === cwd) {
|
||||
checkCwdSync(cwd)
|
||||
return done()
|
||||
}
|
||||
|
||||
if (preserve) {
|
||||
return done(mkdirp.sync(dir, mode))
|
||||
}
|
||||
|
||||
const sub = normPath(path.relative(cwd, dir))
|
||||
const parts = sub.split('/')
|
||||
let created = null
|
||||
for (let p = parts.shift(), part = cwd;
|
||||
p && (part += '/' + p);
|
||||
p = parts.shift()) {
|
||||
part = normPath(path.resolve(part))
|
||||
if (cGet(cache, part)) {
|
||||
continue
|
||||
}
|
||||
|
||||
try {
|
||||
fs.mkdirSync(part, mode)
|
||||
created = created || part
|
||||
cSet(cache, part, true)
|
||||
} catch (er) {
|
||||
const st = fs.lstatSync(part)
|
||||
if (st.isDirectory()) {
|
||||
cSet(cache, part, true)
|
||||
continue
|
||||
} else if (unlink) {
|
||||
fs.unlinkSync(part)
|
||||
fs.mkdirSync(part, mode)
|
||||
created = created || part
|
||||
cSet(cache, part, true)
|
||||
continue
|
||||
} else if (st.isSymbolicLink()) {
|
||||
return new SymlinkError(part, part + '/' + parts.join('/'))
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return done(created)
|
||||
}
|
||||
27
electron/node_modules/cacache/node_modules/tar/lib/mode-fix.js
generated
vendored
Normal file
27
electron/node_modules/cacache/node_modules/tar/lib/mode-fix.js
generated
vendored
Normal file
|
|
@ -0,0 +1,27 @@
|
|||
'use strict'
|
||||
module.exports = (mode, isDir, portable) => {
|
||||
mode &= 0o7777
|
||||
|
||||
// in portable mode, use the minimum reasonable umask
|
||||
// if this system creates files with 0o664 by default
|
||||
// (as some linux distros do), then we'll write the
|
||||
// archive with 0o644 instead. Also, don't ever create
|
||||
// a file that is not readable/writable by the owner.
|
||||
if (portable) {
|
||||
mode = (mode | 0o600) & ~0o22
|
||||
}
|
||||
|
||||
// if dirs are readable, then they should be listable
|
||||
if (isDir) {
|
||||
if (mode & 0o400) {
|
||||
mode |= 0o100
|
||||
}
|
||||
if (mode & 0o40) {
|
||||
mode |= 0o10
|
||||
}
|
||||
if (mode & 0o4) {
|
||||
mode |= 0o1
|
||||
}
|
||||
}
|
||||
return mode
|
||||
}
|
||||
12
electron/node_modules/cacache/node_modules/tar/lib/normalize-unicode.js
generated
vendored
Normal file
12
electron/node_modules/cacache/node_modules/tar/lib/normalize-unicode.js
generated
vendored
Normal file
|
|
@ -0,0 +1,12 @@
|
|||
// warning: extremely hot code path.
|
||||
// This has been meticulously optimized for use
|
||||
// within npm install on large package trees.
|
||||
// Do not edit without careful benchmarking.
|
||||
const normalizeCache = Object.create(null)
|
||||
const { hasOwnProperty } = Object.prototype
|
||||
module.exports = s => {
|
||||
if (!hasOwnProperty.call(normalizeCache, s)) {
|
||||
normalizeCache[s] = s.normalize('NFD')
|
||||
}
|
||||
return normalizeCache[s]
|
||||
}
|
||||
8
electron/node_modules/cacache/node_modules/tar/lib/normalize-windows-path.js
generated
vendored
Normal file
8
electron/node_modules/cacache/node_modules/tar/lib/normalize-windows-path.js
generated
vendored
Normal file
|
|
@ -0,0 +1,8 @@
|
|||
// on windows, either \ or / are valid directory separators.
|
||||
// on unix, \ is a valid character in filenames.
|
||||
// so, on windows, and only on windows, we replace all \ chars with /,
|
||||
// so that we can use / as our one and only directory separator char.
|
||||
|
||||
const platform = process.env.TESTING_TAR_FAKE_PLATFORM || process.platform
|
||||
module.exports = platform !== 'win32' ? p => p
|
||||
: p => p && p.replace(/\\/g, '/')
|
||||
432
electron/node_modules/cacache/node_modules/tar/lib/pack.js
generated
vendored
Normal file
432
electron/node_modules/cacache/node_modules/tar/lib/pack.js
generated
vendored
Normal file
|
|
@ -0,0 +1,432 @@
|
|||
'use strict'
|
||||
|
||||
// A readable tar stream creator
|
||||
// Technically, this is a transform stream that you write paths into,
|
||||
// and tar format comes out of.
|
||||
// The `add()` method is like `write()` but returns this,
|
||||
// and end() return `this` as well, so you can
|
||||
// do `new Pack(opt).add('files').add('dir').end().pipe(output)
|
||||
// You could also do something like:
|
||||
// streamOfPaths().pipe(new Pack()).pipe(new fs.WriteStream('out.tar'))
|
||||
|
||||
class PackJob {
|
||||
constructor (path, absolute) {
|
||||
this.path = path || './'
|
||||
this.absolute = absolute
|
||||
this.entry = null
|
||||
this.stat = null
|
||||
this.readdir = null
|
||||
this.pending = false
|
||||
this.ignore = false
|
||||
this.piped = false
|
||||
}
|
||||
}
|
||||
|
||||
const { Minipass } = require('minipass')
|
||||
const zlib = require('minizlib')
|
||||
const ReadEntry = require('./read-entry.js')
|
||||
const WriteEntry = require('./write-entry.js')
|
||||
const WriteEntrySync = WriteEntry.Sync
|
||||
const WriteEntryTar = WriteEntry.Tar
|
||||
const Yallist = require('yallist')
|
||||
const EOF = Buffer.alloc(1024)
|
||||
const ONSTAT = Symbol('onStat')
|
||||
const ENDED = Symbol('ended')
|
||||
const QUEUE = Symbol('queue')
|
||||
const CURRENT = Symbol('current')
|
||||
const PROCESS = Symbol('process')
|
||||
const PROCESSING = Symbol('processing')
|
||||
const PROCESSJOB = Symbol('processJob')
|
||||
const JOBS = Symbol('jobs')
|
||||
const JOBDONE = Symbol('jobDone')
|
||||
const ADDFSENTRY = Symbol('addFSEntry')
|
||||
const ADDTARENTRY = Symbol('addTarEntry')
|
||||
const STAT = Symbol('stat')
|
||||
const READDIR = Symbol('readdir')
|
||||
const ONREADDIR = Symbol('onreaddir')
|
||||
const PIPE = Symbol('pipe')
|
||||
const ENTRY = Symbol('entry')
|
||||
const ENTRYOPT = Symbol('entryOpt')
|
||||
const WRITEENTRYCLASS = Symbol('writeEntryClass')
|
||||
const WRITE = Symbol('write')
|
||||
const ONDRAIN = Symbol('ondrain')
|
||||
|
||||
const fs = require('fs')
|
||||
const path = require('path')
|
||||
const warner = require('./warn-mixin.js')
|
||||
const normPath = require('./normalize-windows-path.js')
|
||||
|
||||
const Pack = warner(class Pack extends Minipass {
|
||||
constructor (opt) {
|
||||
super(opt)
|
||||
opt = opt || Object.create(null)
|
||||
this.opt = opt
|
||||
this.file = opt.file || ''
|
||||
this.cwd = opt.cwd || process.cwd()
|
||||
this.maxReadSize = opt.maxReadSize
|
||||
this.preservePaths = !!opt.preservePaths
|
||||
this.strict = !!opt.strict
|
||||
this.noPax = !!opt.noPax
|
||||
this.prefix = normPath(opt.prefix || '')
|
||||
this.linkCache = opt.linkCache || new Map()
|
||||
this.statCache = opt.statCache || new Map()
|
||||
this.readdirCache = opt.readdirCache || new Map()
|
||||
|
||||
this[WRITEENTRYCLASS] = WriteEntry
|
||||
if (typeof opt.onwarn === 'function') {
|
||||
this.on('warn', opt.onwarn)
|
||||
}
|
||||
|
||||
this.portable = !!opt.portable
|
||||
this.zip = null
|
||||
|
||||
if (opt.gzip || opt.brotli) {
|
||||
if (opt.gzip && opt.brotli) {
|
||||
throw new TypeError('gzip and brotli are mutually exclusive')
|
||||
}
|
||||
if (opt.gzip) {
|
||||
if (typeof opt.gzip !== 'object') {
|
||||
opt.gzip = {}
|
||||
}
|
||||
if (this.portable) {
|
||||
opt.gzip.portable = true
|
||||
}
|
||||
this.zip = new zlib.Gzip(opt.gzip)
|
||||
}
|
||||
if (opt.brotli) {
|
||||
if (typeof opt.brotli !== 'object') {
|
||||
opt.brotli = {}
|
||||
}
|
||||
this.zip = new zlib.BrotliCompress(opt.brotli)
|
||||
}
|
||||
this.zip.on('data', chunk => super.write(chunk))
|
||||
this.zip.on('end', _ => super.end())
|
||||
this.zip.on('drain', _ => this[ONDRAIN]())
|
||||
this.on('resume', _ => this.zip.resume())
|
||||
} else {
|
||||
this.on('drain', this[ONDRAIN])
|
||||
}
|
||||
|
||||
this.noDirRecurse = !!opt.noDirRecurse
|
||||
this.follow = !!opt.follow
|
||||
this.noMtime = !!opt.noMtime
|
||||
this.mtime = opt.mtime || null
|
||||
|
||||
this.filter = typeof opt.filter === 'function' ? opt.filter : _ => true
|
||||
|
||||
this[QUEUE] = new Yallist()
|
||||
this[JOBS] = 0
|
||||
this.jobs = +opt.jobs || 4
|
||||
this[PROCESSING] = false
|
||||
this[ENDED] = false
|
||||
}
|
||||
|
||||
[WRITE] (chunk) {
|
||||
return super.write(chunk)
|
||||
}
|
||||
|
||||
add (path) {
|
||||
this.write(path)
|
||||
return this
|
||||
}
|
||||
|
||||
end (path) {
|
||||
if (path) {
|
||||
this.write(path)
|
||||
}
|
||||
this[ENDED] = true
|
||||
this[PROCESS]()
|
||||
return this
|
||||
}
|
||||
|
||||
write (path) {
|
||||
if (this[ENDED]) {
|
||||
throw new Error('write after end')
|
||||
}
|
||||
|
||||
if (path instanceof ReadEntry) {
|
||||
this[ADDTARENTRY](path)
|
||||
} else {
|
||||
this[ADDFSENTRY](path)
|
||||
}
|
||||
return this.flowing
|
||||
}
|
||||
|
||||
[ADDTARENTRY] (p) {
|
||||
const absolute = normPath(path.resolve(this.cwd, p.path))
|
||||
// in this case, we don't have to wait for the stat
|
||||
if (!this.filter(p.path, p)) {
|
||||
p.resume()
|
||||
} else {
|
||||
const job = new PackJob(p.path, absolute, false)
|
||||
job.entry = new WriteEntryTar(p, this[ENTRYOPT](job))
|
||||
job.entry.on('end', _ => this[JOBDONE](job))
|
||||
this[JOBS] += 1
|
||||
this[QUEUE].push(job)
|
||||
}
|
||||
|
||||
this[PROCESS]()
|
||||
}
|
||||
|
||||
[ADDFSENTRY] (p) {
|
||||
const absolute = normPath(path.resolve(this.cwd, p))
|
||||
this[QUEUE].push(new PackJob(p, absolute))
|
||||
this[PROCESS]()
|
||||
}
|
||||
|
||||
[STAT] (job) {
|
||||
job.pending = true
|
||||
this[JOBS] += 1
|
||||
const stat = this.follow ? 'stat' : 'lstat'
|
||||
fs[stat](job.absolute, (er, stat) => {
|
||||
job.pending = false
|
||||
this[JOBS] -= 1
|
||||
if (er) {
|
||||
this.emit('error', er)
|
||||
} else {
|
||||
this[ONSTAT](job, stat)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
[ONSTAT] (job, stat) {
|
||||
this.statCache.set(job.absolute, stat)
|
||||
job.stat = stat
|
||||
|
||||
// now we have the stat, we can filter it.
|
||||
if (!this.filter(job.path, stat)) {
|
||||
job.ignore = true
|
||||
}
|
||||
|
||||
this[PROCESS]()
|
||||
}
|
||||
|
||||
[READDIR] (job) {
|
||||
job.pending = true
|
||||
this[JOBS] += 1
|
||||
fs.readdir(job.absolute, (er, entries) => {
|
||||
job.pending = false
|
||||
this[JOBS] -= 1
|
||||
if (er) {
|
||||
return this.emit('error', er)
|
||||
}
|
||||
this[ONREADDIR](job, entries)
|
||||
})
|
||||
}
|
||||
|
||||
[ONREADDIR] (job, entries) {
|
||||
this.readdirCache.set(job.absolute, entries)
|
||||
job.readdir = entries
|
||||
this[PROCESS]()
|
||||
}
|
||||
|
||||
[PROCESS] () {
|
||||
if (this[PROCESSING]) {
|
||||
return
|
||||
}
|
||||
|
||||
this[PROCESSING] = true
|
||||
for (let w = this[QUEUE].head;
|
||||
w !== null && this[JOBS] < this.jobs;
|
||||
w = w.next) {
|
||||
this[PROCESSJOB](w.value)
|
||||
if (w.value.ignore) {
|
||||
const p = w.next
|
||||
this[QUEUE].removeNode(w)
|
||||
w.next = p
|
||||
}
|
||||
}
|
||||
|
||||
this[PROCESSING] = false
|
||||
|
||||
if (this[ENDED] && !this[QUEUE].length && this[JOBS] === 0) {
|
||||
if (this.zip) {
|
||||
this.zip.end(EOF)
|
||||
} else {
|
||||
super.write(EOF)
|
||||
super.end()
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
get [CURRENT] () {
|
||||
return this[QUEUE] && this[QUEUE].head && this[QUEUE].head.value
|
||||
}
|
||||
|
||||
[JOBDONE] (job) {
|
||||
this[QUEUE].shift()
|
||||
this[JOBS] -= 1
|
||||
this[PROCESS]()
|
||||
}
|
||||
|
||||
[PROCESSJOB] (job) {
|
||||
if (job.pending) {
|
||||
return
|
||||
}
|
||||
|
||||
if (job.entry) {
|
||||
if (job === this[CURRENT] && !job.piped) {
|
||||
this[PIPE](job)
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
if (!job.stat) {
|
||||
if (this.statCache.has(job.absolute)) {
|
||||
this[ONSTAT](job, this.statCache.get(job.absolute))
|
||||
} else {
|
||||
this[STAT](job)
|
||||
}
|
||||
}
|
||||
if (!job.stat) {
|
||||
return
|
||||
}
|
||||
|
||||
// filtered out!
|
||||
if (job.ignore) {
|
||||
return
|
||||
}
|
||||
|
||||
if (!this.noDirRecurse && job.stat.isDirectory() && !job.readdir) {
|
||||
if (this.readdirCache.has(job.absolute)) {
|
||||
this[ONREADDIR](job, this.readdirCache.get(job.absolute))
|
||||
} else {
|
||||
this[READDIR](job)
|
||||
}
|
||||
if (!job.readdir) {
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
// we know it doesn't have an entry, because that got checked above
|
||||
job.entry = this[ENTRY](job)
|
||||
if (!job.entry) {
|
||||
job.ignore = true
|
||||
return
|
||||
}
|
||||
|
||||
if (job === this[CURRENT] && !job.piped) {
|
||||
this[PIPE](job)
|
||||
}
|
||||
}
|
||||
|
||||
[ENTRYOPT] (job) {
|
||||
return {
|
||||
onwarn: (code, msg, data) => this.warn(code, msg, data),
|
||||
noPax: this.noPax,
|
||||
cwd: this.cwd,
|
||||
absolute: job.absolute,
|
||||
preservePaths: this.preservePaths,
|
||||
maxReadSize: this.maxReadSize,
|
||||
strict: this.strict,
|
||||
portable: this.portable,
|
||||
linkCache: this.linkCache,
|
||||
statCache: this.statCache,
|
||||
noMtime: this.noMtime,
|
||||
mtime: this.mtime,
|
||||
prefix: this.prefix,
|
||||
}
|
||||
}
|
||||
|
||||
[ENTRY] (job) {
|
||||
this[JOBS] += 1
|
||||
try {
|
||||
return new this[WRITEENTRYCLASS](job.path, this[ENTRYOPT](job))
|
||||
.on('end', () => this[JOBDONE](job))
|
||||
.on('error', er => this.emit('error', er))
|
||||
} catch (er) {
|
||||
this.emit('error', er)
|
||||
}
|
||||
}
|
||||
|
||||
[ONDRAIN] () {
|
||||
if (this[CURRENT] && this[CURRENT].entry) {
|
||||
this[CURRENT].entry.resume()
|
||||
}
|
||||
}
|
||||
|
||||
// like .pipe() but using super, because our write() is special
|
||||
[PIPE] (job) {
|
||||
job.piped = true
|
||||
|
||||
if (job.readdir) {
|
||||
job.readdir.forEach(entry => {
|
||||
const p = job.path
|
||||
const base = p === './' ? '' : p.replace(/\/*$/, '/')
|
||||
this[ADDFSENTRY](base + entry)
|
||||
})
|
||||
}
|
||||
|
||||
const source = job.entry
|
||||
const zip = this.zip
|
||||
|
||||
if (zip) {
|
||||
source.on('data', chunk => {
|
||||
if (!zip.write(chunk)) {
|
||||
source.pause()
|
||||
}
|
||||
})
|
||||
} else {
|
||||
source.on('data', chunk => {
|
||||
if (!super.write(chunk)) {
|
||||
source.pause()
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
pause () {
|
||||
if (this.zip) {
|
||||
this.zip.pause()
|
||||
}
|
||||
return super.pause()
|
||||
}
|
||||
})
|
||||
|
||||
class PackSync extends Pack {
|
||||
constructor (opt) {
|
||||
super(opt)
|
||||
this[WRITEENTRYCLASS] = WriteEntrySync
|
||||
}
|
||||
|
||||
// pause/resume are no-ops in sync streams.
|
||||
pause () {}
|
||||
resume () {}
|
||||
|
||||
[STAT] (job) {
|
||||
const stat = this.follow ? 'statSync' : 'lstatSync'
|
||||
this[ONSTAT](job, fs[stat](job.absolute))
|
||||
}
|
||||
|
||||
[READDIR] (job, stat) {
|
||||
this[ONREADDIR](job, fs.readdirSync(job.absolute))
|
||||
}
|
||||
|
||||
// gotta get it all in this tick
|
||||
[PIPE] (job) {
|
||||
const source = job.entry
|
||||
const zip = this.zip
|
||||
|
||||
if (job.readdir) {
|
||||
job.readdir.forEach(entry => {
|
||||
const p = job.path
|
||||
const base = p === './' ? '' : p.replace(/\/*$/, '/')
|
||||
this[ADDFSENTRY](base + entry)
|
||||
})
|
||||
}
|
||||
|
||||
if (zip) {
|
||||
source.on('data', chunk => {
|
||||
zip.write(chunk)
|
||||
})
|
||||
} else {
|
||||
source.on('data', chunk => {
|
||||
super[WRITE](chunk)
|
||||
})
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Pack.Sync = PackSync
|
||||
|
||||
module.exports = Pack
|
||||
552
electron/node_modules/cacache/node_modules/tar/lib/parse.js
generated
vendored
Normal file
552
electron/node_modules/cacache/node_modules/tar/lib/parse.js
generated
vendored
Normal file
|
|
@ -0,0 +1,552 @@
|
|||
'use strict'
|
||||
|
||||
// this[BUFFER] is the remainder of a chunk if we're waiting for
|
||||
// the full 512 bytes of a header to come in. We will Buffer.concat()
|
||||
// it to the next write(), which is a mem copy, but a small one.
|
||||
//
|
||||
// this[QUEUE] is a Yallist of entries that haven't been emitted
|
||||
// yet this can only get filled up if the user keeps write()ing after
|
||||
// a write() returns false, or does a write() with more than one entry
|
||||
//
|
||||
// We don't buffer chunks, we always parse them and either create an
|
||||
// entry, or push it into the active entry. The ReadEntry class knows
|
||||
// to throw data away if .ignore=true
|
||||
//
|
||||
// Shift entry off the buffer when it emits 'end', and emit 'entry' for
|
||||
// the next one in the list.
|
||||
//
|
||||
// At any time, we're pushing body chunks into the entry at WRITEENTRY,
|
||||
// and waiting for 'end' on the entry at READENTRY
|
||||
//
|
||||
// ignored entries get .resume() called on them straight away
|
||||
|
||||
const warner = require('./warn-mixin.js')
|
||||
const Header = require('./header.js')
|
||||
const EE = require('events')
|
||||
const Yallist = require('yallist')
|
||||
const maxMetaEntrySize = 1024 * 1024
|
||||
const Entry = require('./read-entry.js')
|
||||
const Pax = require('./pax.js')
|
||||
const zlib = require('minizlib')
|
||||
const { nextTick } = require('process')
|
||||
|
||||
const gzipHeader = Buffer.from([0x1f, 0x8b])
|
||||
const STATE = Symbol('state')
|
||||
const WRITEENTRY = Symbol('writeEntry')
|
||||
const READENTRY = Symbol('readEntry')
|
||||
const NEXTENTRY = Symbol('nextEntry')
|
||||
const PROCESSENTRY = Symbol('processEntry')
|
||||
const EX = Symbol('extendedHeader')
|
||||
const GEX = Symbol('globalExtendedHeader')
|
||||
const META = Symbol('meta')
|
||||
const EMITMETA = Symbol('emitMeta')
|
||||
const BUFFER = Symbol('buffer')
|
||||
const QUEUE = Symbol('queue')
|
||||
const ENDED = Symbol('ended')
|
||||
const EMITTEDEND = Symbol('emittedEnd')
|
||||
const EMIT = Symbol('emit')
|
||||
const UNZIP = Symbol('unzip')
|
||||
const CONSUMECHUNK = Symbol('consumeChunk')
|
||||
const CONSUMECHUNKSUB = Symbol('consumeChunkSub')
|
||||
const CONSUMEBODY = Symbol('consumeBody')
|
||||
const CONSUMEMETA = Symbol('consumeMeta')
|
||||
const CONSUMEHEADER = Symbol('consumeHeader')
|
||||
const CONSUMING = Symbol('consuming')
|
||||
const BUFFERCONCAT = Symbol('bufferConcat')
|
||||
const MAYBEEND = Symbol('maybeEnd')
|
||||
const WRITING = Symbol('writing')
|
||||
const ABORTED = Symbol('aborted')
|
||||
const DONE = Symbol('onDone')
|
||||
const SAW_VALID_ENTRY = Symbol('sawValidEntry')
|
||||
const SAW_NULL_BLOCK = Symbol('sawNullBlock')
|
||||
const SAW_EOF = Symbol('sawEOF')
|
||||
const CLOSESTREAM = Symbol('closeStream')
|
||||
|
||||
const noop = _ => true
|
||||
|
||||
module.exports = warner(class Parser extends EE {
|
||||
constructor (opt) {
|
||||
opt = opt || {}
|
||||
super(opt)
|
||||
|
||||
this.file = opt.file || ''
|
||||
|
||||
// set to boolean false when an entry starts. 1024 bytes of \0
|
||||
// is technically a valid tarball, albeit a boring one.
|
||||
this[SAW_VALID_ENTRY] = null
|
||||
|
||||
// these BADARCHIVE errors can't be detected early. listen on DONE.
|
||||
this.on(DONE, _ => {
|
||||
if (this[STATE] === 'begin' || this[SAW_VALID_ENTRY] === false) {
|
||||
// either less than 1 block of data, or all entries were invalid.
|
||||
// Either way, probably not even a tarball.
|
||||
this.warn('TAR_BAD_ARCHIVE', 'Unrecognized archive format')
|
||||
}
|
||||
})
|
||||
|
||||
if (opt.ondone) {
|
||||
this.on(DONE, opt.ondone)
|
||||
} else {
|
||||
this.on(DONE, _ => {
|
||||
this.emit('prefinish')
|
||||
this.emit('finish')
|
||||
this.emit('end')
|
||||
})
|
||||
}
|
||||
|
||||
this.strict = !!opt.strict
|
||||
this.maxMetaEntrySize = opt.maxMetaEntrySize || maxMetaEntrySize
|
||||
this.filter = typeof opt.filter === 'function' ? opt.filter : noop
|
||||
// Unlike gzip, brotli doesn't have any magic bytes to identify it
|
||||
// Users need to explicitly tell us they're extracting a brotli file
|
||||
// Or we infer from the file extension
|
||||
const isTBR = (opt.file && (
|
||||
opt.file.endsWith('.tar.br') || opt.file.endsWith('.tbr')))
|
||||
// if it's a tbr file it MIGHT be brotli, but we don't know until
|
||||
// we look at it and verify it's not a valid tar file.
|
||||
this.brotli = !opt.gzip && opt.brotli !== undefined ? opt.brotli
|
||||
: isTBR ? undefined
|
||||
: false
|
||||
|
||||
// have to set this so that streams are ok piping into it
|
||||
this.writable = true
|
||||
this.readable = false
|
||||
|
||||
this[QUEUE] = new Yallist()
|
||||
this[BUFFER] = null
|
||||
this[READENTRY] = null
|
||||
this[WRITEENTRY] = null
|
||||
this[STATE] = 'begin'
|
||||
this[META] = ''
|
||||
this[EX] = null
|
||||
this[GEX] = null
|
||||
this[ENDED] = false
|
||||
this[UNZIP] = null
|
||||
this[ABORTED] = false
|
||||
this[SAW_NULL_BLOCK] = false
|
||||
this[SAW_EOF] = false
|
||||
|
||||
this.on('end', () => this[CLOSESTREAM]())
|
||||
|
||||
if (typeof opt.onwarn === 'function') {
|
||||
this.on('warn', opt.onwarn)
|
||||
}
|
||||
if (typeof opt.onentry === 'function') {
|
||||
this.on('entry', opt.onentry)
|
||||
}
|
||||
}
|
||||
|
||||
[CONSUMEHEADER] (chunk, position) {
|
||||
if (this[SAW_VALID_ENTRY] === null) {
|
||||
this[SAW_VALID_ENTRY] = false
|
||||
}
|
||||
let header
|
||||
try {
|
||||
header = new Header(chunk, position, this[EX], this[GEX])
|
||||
} catch (er) {
|
||||
return this.warn('TAR_ENTRY_INVALID', er)
|
||||
}
|
||||
|
||||
if (header.nullBlock) {
|
||||
if (this[SAW_NULL_BLOCK]) {
|
||||
this[SAW_EOF] = true
|
||||
// ending an archive with no entries. pointless, but legal.
|
||||
if (this[STATE] === 'begin') {
|
||||
this[STATE] = 'header'
|
||||
}
|
||||
this[EMIT]('eof')
|
||||
} else {
|
||||
this[SAW_NULL_BLOCK] = true
|
||||
this[EMIT]('nullBlock')
|
||||
}
|
||||
} else {
|
||||
this[SAW_NULL_BLOCK] = false
|
||||
if (!header.cksumValid) {
|
||||
this.warn('TAR_ENTRY_INVALID', 'checksum failure', { header })
|
||||
} else if (!header.path) {
|
||||
this.warn('TAR_ENTRY_INVALID', 'path is required', { header })
|
||||
} else {
|
||||
const type = header.type
|
||||
if (/^(Symbolic)?Link$/.test(type) && !header.linkpath) {
|
||||
this.warn('TAR_ENTRY_INVALID', 'linkpath required', { header })
|
||||
} else if (!/^(Symbolic)?Link$/.test(type) && header.linkpath) {
|
||||
this.warn('TAR_ENTRY_INVALID', 'linkpath forbidden', { header })
|
||||
} else {
|
||||
const entry = this[WRITEENTRY] = new Entry(header, this[EX], this[GEX])
|
||||
|
||||
// we do this for meta & ignored entries as well, because they
|
||||
// are still valid tar, or else we wouldn't know to ignore them
|
||||
if (!this[SAW_VALID_ENTRY]) {
|
||||
if (entry.remain) {
|
||||
// this might be the one!
|
||||
const onend = () => {
|
||||
if (!entry.invalid) {
|
||||
this[SAW_VALID_ENTRY] = true
|
||||
}
|
||||
}
|
||||
entry.on('end', onend)
|
||||
} else {
|
||||
this[SAW_VALID_ENTRY] = true
|
||||
}
|
||||
}
|
||||
|
||||
if (entry.meta) {
|
||||
if (entry.size > this.maxMetaEntrySize) {
|
||||
entry.ignore = true
|
||||
this[EMIT]('ignoredEntry', entry)
|
||||
this[STATE] = 'ignore'
|
||||
entry.resume()
|
||||
} else if (entry.size > 0) {
|
||||
this[META] = ''
|
||||
entry.on('data', c => this[META] += c)
|
||||
this[STATE] = 'meta'
|
||||
}
|
||||
} else {
|
||||
this[EX] = null
|
||||
entry.ignore = entry.ignore || !this.filter(entry.path, entry)
|
||||
|
||||
if (entry.ignore) {
|
||||
// probably valid, just not something we care about
|
||||
this[EMIT]('ignoredEntry', entry)
|
||||
this[STATE] = entry.remain ? 'ignore' : 'header'
|
||||
entry.resume()
|
||||
} else {
|
||||
if (entry.remain) {
|
||||
this[STATE] = 'body'
|
||||
} else {
|
||||
this[STATE] = 'header'
|
||||
entry.end()
|
||||
}
|
||||
|
||||
if (!this[READENTRY]) {
|
||||
this[QUEUE].push(entry)
|
||||
this[NEXTENTRY]()
|
||||
} else {
|
||||
this[QUEUE].push(entry)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
[CLOSESTREAM] () {
|
||||
nextTick(() => this.emit('close'))
|
||||
}
|
||||
|
||||
[PROCESSENTRY] (entry) {
|
||||
let go = true
|
||||
|
||||
if (!entry) {
|
||||
this[READENTRY] = null
|
||||
go = false
|
||||
} else if (Array.isArray(entry)) {
|
||||
this.emit.apply(this, entry)
|
||||
} else {
|
||||
this[READENTRY] = entry
|
||||
this.emit('entry', entry)
|
||||
if (!entry.emittedEnd) {
|
||||
entry.on('end', _ => this[NEXTENTRY]())
|
||||
go = false
|
||||
}
|
||||
}
|
||||
|
||||
return go
|
||||
}
|
||||
|
||||
[NEXTENTRY] () {
|
||||
do {} while (this[PROCESSENTRY](this[QUEUE].shift()))
|
||||
|
||||
if (!this[QUEUE].length) {
|
||||
// At this point, there's nothing in the queue, but we may have an
|
||||
// entry which is being consumed (readEntry).
|
||||
// If we don't, then we definitely can handle more data.
|
||||
// If we do, and either it's flowing, or it has never had any data
|
||||
// written to it, then it needs more.
|
||||
// The only other possibility is that it has returned false from a
|
||||
// write() call, so we wait for the next drain to continue.
|
||||
const re = this[READENTRY]
|
||||
const drainNow = !re || re.flowing || re.size === re.remain
|
||||
if (drainNow) {
|
||||
if (!this[WRITING]) {
|
||||
this.emit('drain')
|
||||
}
|
||||
} else {
|
||||
re.once('drain', _ => this.emit('drain'))
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
[CONSUMEBODY] (chunk, position) {
|
||||
// write up to but no more than writeEntry.blockRemain
|
||||
const entry = this[WRITEENTRY]
|
||||
const br = entry.blockRemain
|
||||
const c = (br >= chunk.length && position === 0) ? chunk
|
||||
: chunk.slice(position, position + br)
|
||||
|
||||
entry.write(c)
|
||||
|
||||
if (!entry.blockRemain) {
|
||||
this[STATE] = 'header'
|
||||
this[WRITEENTRY] = null
|
||||
entry.end()
|
||||
}
|
||||
|
||||
return c.length
|
||||
}
|
||||
|
||||
[CONSUMEMETA] (chunk, position) {
|
||||
const entry = this[WRITEENTRY]
|
||||
const ret = this[CONSUMEBODY](chunk, position)
|
||||
|
||||
// if we finished, then the entry is reset
|
||||
if (!this[WRITEENTRY]) {
|
||||
this[EMITMETA](entry)
|
||||
}
|
||||
|
||||
return ret
|
||||
}
|
||||
|
||||
[EMIT] (ev, data, extra) {
|
||||
if (!this[QUEUE].length && !this[READENTRY]) {
|
||||
this.emit(ev, data, extra)
|
||||
} else {
|
||||
this[QUEUE].push([ev, data, extra])
|
||||
}
|
||||
}
|
||||
|
||||
[EMITMETA] (entry) {
|
||||
this[EMIT]('meta', this[META])
|
||||
switch (entry.type) {
|
||||
case 'ExtendedHeader':
|
||||
case 'OldExtendedHeader':
|
||||
this[EX] = Pax.parse(this[META], this[EX], false)
|
||||
break
|
||||
|
||||
case 'GlobalExtendedHeader':
|
||||
this[GEX] = Pax.parse(this[META], this[GEX], true)
|
||||
break
|
||||
|
||||
case 'NextFileHasLongPath':
|
||||
case 'OldGnuLongPath':
|
||||
this[EX] = this[EX] || Object.create(null)
|
||||
this[EX].path = this[META].replace(/\0.*/, '')
|
||||
break
|
||||
|
||||
case 'NextFileHasLongLinkpath':
|
||||
this[EX] = this[EX] || Object.create(null)
|
||||
this[EX].linkpath = this[META].replace(/\0.*/, '')
|
||||
break
|
||||
|
||||
/* istanbul ignore next */
|
||||
default: throw new Error('unknown meta: ' + entry.type)
|
||||
}
|
||||
}
|
||||
|
||||
abort (error) {
|
||||
this[ABORTED] = true
|
||||
this.emit('abort', error)
|
||||
// always throws, even in non-strict mode
|
||||
this.warn('TAR_ABORT', error, { recoverable: false })
|
||||
}
|
||||
|
||||
write (chunk) {
|
||||
if (this[ABORTED]) {
|
||||
return
|
||||
}
|
||||
|
||||
// first write, might be gzipped
|
||||
const needSniff = this[UNZIP] === null ||
|
||||
this.brotli === undefined && this[UNZIP] === false
|
||||
if (needSniff && chunk) {
|
||||
if (this[BUFFER]) {
|
||||
chunk = Buffer.concat([this[BUFFER], chunk])
|
||||
this[BUFFER] = null
|
||||
}
|
||||
if (chunk.length < gzipHeader.length) {
|
||||
this[BUFFER] = chunk
|
||||
return true
|
||||
}
|
||||
|
||||
// look for gzip header
|
||||
for (let i = 0; this[UNZIP] === null && i < gzipHeader.length; i++) {
|
||||
if (chunk[i] !== gzipHeader[i]) {
|
||||
this[UNZIP] = false
|
||||
}
|
||||
}
|
||||
|
||||
const maybeBrotli = this.brotli === undefined
|
||||
if (this[UNZIP] === false && maybeBrotli) {
|
||||
// read the first header to see if it's a valid tar file. If so,
|
||||
// we can safely assume that it's not actually brotli, despite the
|
||||
// .tbr or .tar.br file extension.
|
||||
// if we ended before getting a full chunk, yes, def brotli
|
||||
if (chunk.length < 512) {
|
||||
if (this[ENDED]) {
|
||||
this.brotli = true
|
||||
} else {
|
||||
this[BUFFER] = chunk
|
||||
return true
|
||||
}
|
||||
} else {
|
||||
// if it's tar, it's pretty reliably not brotli, chances of
|
||||
// that happening are astronomical.
|
||||
try {
|
||||
new Header(chunk.slice(0, 512))
|
||||
this.brotli = false
|
||||
} catch (_) {
|
||||
this.brotli = true
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (this[UNZIP] === null || (this[UNZIP] === false && this.brotli)) {
|
||||
const ended = this[ENDED]
|
||||
this[ENDED] = false
|
||||
this[UNZIP] = this[UNZIP] === null
|
||||
? new zlib.Unzip()
|
||||
: new zlib.BrotliDecompress()
|
||||
this[UNZIP].on('data', chunk => this[CONSUMECHUNK](chunk))
|
||||
this[UNZIP].on('error', er => this.abort(er))
|
||||
this[UNZIP].on('end', _ => {
|
||||
this[ENDED] = true
|
||||
this[CONSUMECHUNK]()
|
||||
})
|
||||
this[WRITING] = true
|
||||
const ret = this[UNZIP][ended ? 'end' : 'write'](chunk)
|
||||
this[WRITING] = false
|
||||
return ret
|
||||
}
|
||||
}
|
||||
|
||||
this[WRITING] = true
|
||||
if (this[UNZIP]) {
|
||||
this[UNZIP].write(chunk)
|
||||
} else {
|
||||
this[CONSUMECHUNK](chunk)
|
||||
}
|
||||
this[WRITING] = false
|
||||
|
||||
// return false if there's a queue, or if the current entry isn't flowing
|
||||
const ret =
|
||||
this[QUEUE].length ? false :
|
||||
this[READENTRY] ? this[READENTRY].flowing :
|
||||
true
|
||||
|
||||
// if we have no queue, then that means a clogged READENTRY
|
||||
if (!ret && !this[QUEUE].length) {
|
||||
this[READENTRY].once('drain', _ => this.emit('drain'))
|
||||
}
|
||||
|
||||
return ret
|
||||
}
|
||||
|
||||
[BUFFERCONCAT] (c) {
|
||||
if (c && !this[ABORTED]) {
|
||||
this[BUFFER] = this[BUFFER] ? Buffer.concat([this[BUFFER], c]) : c
|
||||
}
|
||||
}
|
||||
|
||||
[MAYBEEND] () {
|
||||
if (this[ENDED] &&
|
||||
!this[EMITTEDEND] &&
|
||||
!this[ABORTED] &&
|
||||
!this[CONSUMING]) {
|
||||
this[EMITTEDEND] = true
|
||||
const entry = this[WRITEENTRY]
|
||||
if (entry && entry.blockRemain) {
|
||||
// truncated, likely a damaged file
|
||||
const have = this[BUFFER] ? this[BUFFER].length : 0
|
||||
this.warn('TAR_BAD_ARCHIVE', `Truncated input (needed ${
|
||||
entry.blockRemain} more bytes, only ${have} available)`, { entry })
|
||||
if (this[BUFFER]) {
|
||||
entry.write(this[BUFFER])
|
||||
}
|
||||
entry.end()
|
||||
}
|
||||
this[EMIT](DONE)
|
||||
}
|
||||
}
|
||||
|
||||
[CONSUMECHUNK] (chunk) {
|
||||
if (this[CONSUMING]) {
|
||||
this[BUFFERCONCAT](chunk)
|
||||
} else if (!chunk && !this[BUFFER]) {
|
||||
this[MAYBEEND]()
|
||||
} else {
|
||||
this[CONSUMING] = true
|
||||
if (this[BUFFER]) {
|
||||
this[BUFFERCONCAT](chunk)
|
||||
const c = this[BUFFER]
|
||||
this[BUFFER] = null
|
||||
this[CONSUMECHUNKSUB](c)
|
||||
} else {
|
||||
this[CONSUMECHUNKSUB](chunk)
|
||||
}
|
||||
|
||||
while (this[BUFFER] &&
|
||||
this[BUFFER].length >= 512 &&
|
||||
!this[ABORTED] &&
|
||||
!this[SAW_EOF]) {
|
||||
const c = this[BUFFER]
|
||||
this[BUFFER] = null
|
||||
this[CONSUMECHUNKSUB](c)
|
||||
}
|
||||
this[CONSUMING] = false
|
||||
}
|
||||
|
||||
if (!this[BUFFER] || this[ENDED]) {
|
||||
this[MAYBEEND]()
|
||||
}
|
||||
}
|
||||
|
||||
[CONSUMECHUNKSUB] (chunk) {
|
||||
// we know that we are in CONSUMING mode, so anything written goes into
|
||||
// the buffer. Advance the position and put any remainder in the buffer.
|
||||
let position = 0
|
||||
const length = chunk.length
|
||||
while (position + 512 <= length && !this[ABORTED] && !this[SAW_EOF]) {
|
||||
switch (this[STATE]) {
|
||||
case 'begin':
|
||||
case 'header':
|
||||
this[CONSUMEHEADER](chunk, position)
|
||||
position += 512
|
||||
break
|
||||
|
||||
case 'ignore':
|
||||
case 'body':
|
||||
position += this[CONSUMEBODY](chunk, position)
|
||||
break
|
||||
|
||||
case 'meta':
|
||||
position += this[CONSUMEMETA](chunk, position)
|
||||
break
|
||||
|
||||
/* istanbul ignore next */
|
||||
default:
|
||||
throw new Error('invalid state: ' + this[STATE])
|
||||
}
|
||||
}
|
||||
|
||||
if (position < length) {
|
||||
if (this[BUFFER]) {
|
||||
this[BUFFER] = Buffer.concat([chunk.slice(position), this[BUFFER]])
|
||||
} else {
|
||||
this[BUFFER] = chunk.slice(position)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
end (chunk) {
|
||||
if (!this[ABORTED]) {
|
||||
if (this[UNZIP]) {
|
||||
this[UNZIP].end(chunk)
|
||||
} else {
|
||||
this[ENDED] = true
|
||||
if (this.brotli === undefined) chunk = chunk || Buffer.alloc(0)
|
||||
this.write(chunk)
|
||||
}
|
||||
}
|
||||
}
|
||||
})
|
||||
156
electron/node_modules/cacache/node_modules/tar/lib/path-reservations.js
generated
vendored
Normal file
156
electron/node_modules/cacache/node_modules/tar/lib/path-reservations.js
generated
vendored
Normal file
|
|
@ -0,0 +1,156 @@
|
|||
// A path exclusive reservation system
|
||||
// reserve([list, of, paths], fn)
|
||||
// When the fn is first in line for all its paths, it
|
||||
// is called with a cb that clears the reservation.
|
||||
//
|
||||
// Used by async unpack to avoid clobbering paths in use,
|
||||
// while still allowing maximal safe parallelization.
|
||||
|
||||
const assert = require('assert')
|
||||
const normalize = require('./normalize-unicode.js')
|
||||
const stripSlashes = require('./strip-trailing-slashes.js')
|
||||
const { join } = require('path')
|
||||
|
||||
const platform = process.env.TESTING_TAR_FAKE_PLATFORM || process.platform
|
||||
const isWindows = platform === 'win32'
|
||||
|
||||
module.exports = () => {
|
||||
// path => [function or Set]
|
||||
// A Set object means a directory reservation
|
||||
// A fn is a direct reservation on that path
|
||||
const queues = new Map()
|
||||
|
||||
// fn => {paths:[path,...], dirs:[path, ...]}
|
||||
const reservations = new Map()
|
||||
|
||||
// return a set of parent dirs for a given path
|
||||
// '/a/b/c/d' -> ['/', '/a', '/a/b', '/a/b/c', '/a/b/c/d']
|
||||
const getDirs = path => {
|
||||
const dirs = path.split('/').slice(0, -1).reduce((set, path) => {
|
||||
if (set.length) {
|
||||
path = join(set[set.length - 1], path)
|
||||
}
|
||||
set.push(path || '/')
|
||||
return set
|
||||
}, [])
|
||||
return dirs
|
||||
}
|
||||
|
||||
// functions currently running
|
||||
const running = new Set()
|
||||
|
||||
// return the queues for each path the function cares about
|
||||
// fn => {paths, dirs}
|
||||
const getQueues = fn => {
|
||||
const res = reservations.get(fn)
|
||||
/* istanbul ignore if - unpossible */
|
||||
if (!res) {
|
||||
throw new Error('function does not have any path reservations')
|
||||
}
|
||||
return {
|
||||
paths: res.paths.map(path => queues.get(path)),
|
||||
dirs: [...res.dirs].map(path => queues.get(path)),
|
||||
}
|
||||
}
|
||||
|
||||
// check if fn is first in line for all its paths, and is
|
||||
// included in the first set for all its dir queues
|
||||
const check = fn => {
|
||||
const { paths, dirs } = getQueues(fn)
|
||||
return paths.every(q => q[0] === fn) &&
|
||||
dirs.every(q => q[0] instanceof Set && q[0].has(fn))
|
||||
}
|
||||
|
||||
// run the function if it's first in line and not already running
|
||||
const run = fn => {
|
||||
if (running.has(fn) || !check(fn)) {
|
||||
return false
|
||||
}
|
||||
running.add(fn)
|
||||
fn(() => clear(fn))
|
||||
return true
|
||||
}
|
||||
|
||||
const clear = fn => {
|
||||
if (!running.has(fn)) {
|
||||
return false
|
||||
}
|
||||
|
||||
const { paths, dirs } = reservations.get(fn)
|
||||
const next = new Set()
|
||||
|
||||
paths.forEach(path => {
|
||||
const q = queues.get(path)
|
||||
assert.equal(q[0], fn)
|
||||
if (q.length === 1) {
|
||||
queues.delete(path)
|
||||
} else {
|
||||
q.shift()
|
||||
if (typeof q[0] === 'function') {
|
||||
next.add(q[0])
|
||||
} else {
|
||||
q[0].forEach(fn => next.add(fn))
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
dirs.forEach(dir => {
|
||||
const q = queues.get(dir)
|
||||
assert(q[0] instanceof Set)
|
||||
if (q[0].size === 1 && q.length === 1) {
|
||||
queues.delete(dir)
|
||||
} else if (q[0].size === 1) {
|
||||
q.shift()
|
||||
|
||||
// must be a function or else the Set would've been reused
|
||||
next.add(q[0])
|
||||
} else {
|
||||
q[0].delete(fn)
|
||||
}
|
||||
})
|
||||
running.delete(fn)
|
||||
|
||||
next.forEach(fn => run(fn))
|
||||
return true
|
||||
}
|
||||
|
||||
const reserve = (paths, fn) => {
|
||||
// collide on matches across case and unicode normalization
|
||||
// On windows, thanks to the magic of 8.3 shortnames, it is fundamentally
|
||||
// impossible to determine whether two paths refer to the same thing on
|
||||
// disk, without asking the kernel for a shortname.
|
||||
// So, we just pretend that every path matches every other path here,
|
||||
// effectively removing all parallelization on windows.
|
||||
paths = isWindows ? ['win32 parallelization disabled'] : paths.map(p => {
|
||||
// don't need normPath, because we skip this entirely for windows
|
||||
return stripSlashes(join(normalize(p))).toLowerCase()
|
||||
})
|
||||
|
||||
const dirs = new Set(
|
||||
paths.map(path => getDirs(path)).reduce((a, b) => a.concat(b))
|
||||
)
|
||||
reservations.set(fn, { dirs, paths })
|
||||
paths.forEach(path => {
|
||||
const q = queues.get(path)
|
||||
if (!q) {
|
||||
queues.set(path, [fn])
|
||||
} else {
|
||||
q.push(fn)
|
||||
}
|
||||
})
|
||||
dirs.forEach(dir => {
|
||||
const q = queues.get(dir)
|
||||
if (!q) {
|
||||
queues.set(dir, [new Set([fn])])
|
||||
} else if (q[q.length - 1] instanceof Set) {
|
||||
q[q.length - 1].add(fn)
|
||||
} else {
|
||||
q.push(new Set([fn]))
|
||||
}
|
||||
})
|
||||
|
||||
return run(fn)
|
||||
}
|
||||
|
||||
return { check, reserve }
|
||||
}
|
||||
150
electron/node_modules/cacache/node_modules/tar/lib/pax.js
generated
vendored
Normal file
150
electron/node_modules/cacache/node_modules/tar/lib/pax.js
generated
vendored
Normal file
|
|
@ -0,0 +1,150 @@
|
|||
'use strict'
|
||||
const Header = require('./header.js')
|
||||
const path = require('path')
|
||||
|
||||
class Pax {
|
||||
constructor (obj, global) {
|
||||
this.atime = obj.atime || null
|
||||
this.charset = obj.charset || null
|
||||
this.comment = obj.comment || null
|
||||
this.ctime = obj.ctime || null
|
||||
this.gid = obj.gid || null
|
||||
this.gname = obj.gname || null
|
||||
this.linkpath = obj.linkpath || null
|
||||
this.mtime = obj.mtime || null
|
||||
this.path = obj.path || null
|
||||
this.size = obj.size || null
|
||||
this.uid = obj.uid || null
|
||||
this.uname = obj.uname || null
|
||||
this.dev = obj.dev || null
|
||||
this.ino = obj.ino || null
|
||||
this.nlink = obj.nlink || null
|
||||
this.global = global || false
|
||||
}
|
||||
|
||||
encode () {
|
||||
const body = this.encodeBody()
|
||||
if (body === '') {
|
||||
return null
|
||||
}
|
||||
|
||||
const bodyLen = Buffer.byteLength(body)
|
||||
// round up to 512 bytes
|
||||
// add 512 for header
|
||||
const bufLen = 512 * Math.ceil(1 + bodyLen / 512)
|
||||
const buf = Buffer.allocUnsafe(bufLen)
|
||||
|
||||
// 0-fill the header section, it might not hit every field
|
||||
for (let i = 0; i < 512; i++) {
|
||||
buf[i] = 0
|
||||
}
|
||||
|
||||
new Header({
|
||||
// XXX split the path
|
||||
// then the path should be PaxHeader + basename, but less than 99,
|
||||
// prepend with the dirname
|
||||
path: ('PaxHeader/' + path.basename(this.path)).slice(0, 99),
|
||||
mode: this.mode || 0o644,
|
||||
uid: this.uid || null,
|
||||
gid: this.gid || null,
|
||||
size: bodyLen,
|
||||
mtime: this.mtime || null,
|
||||
type: this.global ? 'GlobalExtendedHeader' : 'ExtendedHeader',
|
||||
linkpath: '',
|
||||
uname: this.uname || '',
|
||||
gname: this.gname || '',
|
||||
devmaj: 0,
|
||||
devmin: 0,
|
||||
atime: this.atime || null,
|
||||
ctime: this.ctime || null,
|
||||
}).encode(buf)
|
||||
|
||||
buf.write(body, 512, bodyLen, 'utf8')
|
||||
|
||||
// null pad after the body
|
||||
for (let i = bodyLen + 512; i < buf.length; i++) {
|
||||
buf[i] = 0
|
||||
}
|
||||
|
||||
return buf
|
||||
}
|
||||
|
||||
encodeBody () {
|
||||
return (
|
||||
this.encodeField('path') +
|
||||
this.encodeField('ctime') +
|
||||
this.encodeField('atime') +
|
||||
this.encodeField('dev') +
|
||||
this.encodeField('ino') +
|
||||
this.encodeField('nlink') +
|
||||
this.encodeField('charset') +
|
||||
this.encodeField('comment') +
|
||||
this.encodeField('gid') +
|
||||
this.encodeField('gname') +
|
||||
this.encodeField('linkpath') +
|
||||
this.encodeField('mtime') +
|
||||
this.encodeField('size') +
|
||||
this.encodeField('uid') +
|
||||
this.encodeField('uname')
|
||||
)
|
||||
}
|
||||
|
||||
encodeField (field) {
|
||||
if (this[field] === null || this[field] === undefined) {
|
||||
return ''
|
||||
}
|
||||
const v = this[field] instanceof Date ? this[field].getTime() / 1000
|
||||
: this[field]
|
||||
const s = ' ' +
|
||||
(field === 'dev' || field === 'ino' || field === 'nlink'
|
||||
? 'SCHILY.' : '') +
|
||||
field + '=' + v + '\n'
|
||||
const byteLen = Buffer.byteLength(s)
|
||||
// the digits includes the length of the digits in ascii base-10
|
||||
// so if it's 9 characters, then adding 1 for the 9 makes it 10
|
||||
// which makes it 11 chars.
|
||||
let digits = Math.floor(Math.log(byteLen) / Math.log(10)) + 1
|
||||
if (byteLen + digits >= Math.pow(10, digits)) {
|
||||
digits += 1
|
||||
}
|
||||
const len = digits + byteLen
|
||||
return len + s
|
||||
}
|
||||
}
|
||||
|
||||
Pax.parse = (string, ex, g) => new Pax(merge(parseKV(string), ex), g)
|
||||
|
||||
const merge = (a, b) =>
|
||||
b ? Object.keys(a).reduce((s, k) => (s[k] = a[k], s), b) : a
|
||||
|
||||
const parseKV = string =>
|
||||
string
|
||||
.replace(/\n$/, '')
|
||||
.split('\n')
|
||||
.reduce(parseKVLine, Object.create(null))
|
||||
|
||||
const parseKVLine = (set, line) => {
|
||||
const n = parseInt(line, 10)
|
||||
|
||||
// XXX Values with \n in them will fail this.
|
||||
// Refactor to not be a naive line-by-line parse.
|
||||
if (n !== Buffer.byteLength(line) + 1) {
|
||||
return set
|
||||
}
|
||||
|
||||
line = line.slice((n + ' ').length)
|
||||
const kv = line.split('=')
|
||||
const k = kv.shift().replace(/^SCHILY\.(dev|ino|nlink)/, '$1')
|
||||
if (!k) {
|
||||
return set
|
||||
}
|
||||
|
||||
const v = kv.join('=')
|
||||
set[k] = /^([A-Z]+\.)?([mac]|birth|creation)time$/.test(k)
|
||||
? new Date(v * 1000)
|
||||
: /^[0-9]+$/.test(v) ? +v
|
||||
: v
|
||||
return set
|
||||
}
|
||||
|
||||
module.exports = Pax
|
||||
107
electron/node_modules/cacache/node_modules/tar/lib/read-entry.js
generated
vendored
Normal file
107
electron/node_modules/cacache/node_modules/tar/lib/read-entry.js
generated
vendored
Normal file
|
|
@ -0,0 +1,107 @@
|
|||
'use strict'
|
||||
const { Minipass } = require('minipass')
|
||||
const normPath = require('./normalize-windows-path.js')
|
||||
|
||||
const SLURP = Symbol('slurp')
|
||||
module.exports = class ReadEntry extends Minipass {
|
||||
constructor (header, ex, gex) {
|
||||
super()
|
||||
// read entries always start life paused. this is to avoid the
|
||||
// situation where Minipass's auto-ending empty streams results
|
||||
// in an entry ending before we're ready for it.
|
||||
this.pause()
|
||||
this.extended = ex
|
||||
this.globalExtended = gex
|
||||
this.header = header
|
||||
this.startBlockSize = 512 * Math.ceil(header.size / 512)
|
||||
this.blockRemain = this.startBlockSize
|
||||
this.remain = header.size
|
||||
this.type = header.type
|
||||
this.meta = false
|
||||
this.ignore = false
|
||||
switch (this.type) {
|
||||
case 'File':
|
||||
case 'OldFile':
|
||||
case 'Link':
|
||||
case 'SymbolicLink':
|
||||
case 'CharacterDevice':
|
||||
case 'BlockDevice':
|
||||
case 'Directory':
|
||||
case 'FIFO':
|
||||
case 'ContiguousFile':
|
||||
case 'GNUDumpDir':
|
||||
break
|
||||
|
||||
case 'NextFileHasLongLinkpath':
|
||||
case 'NextFileHasLongPath':
|
||||
case 'OldGnuLongPath':
|
||||
case 'GlobalExtendedHeader':
|
||||
case 'ExtendedHeader':
|
||||
case 'OldExtendedHeader':
|
||||
this.meta = true
|
||||
break
|
||||
|
||||
// NOTE: gnutar and bsdtar treat unrecognized types as 'File'
|
||||
// it may be worth doing the same, but with a warning.
|
||||
default:
|
||||
this.ignore = true
|
||||
}
|
||||
|
||||
this.path = normPath(header.path)
|
||||
this.mode = header.mode
|
||||
if (this.mode) {
|
||||
this.mode = this.mode & 0o7777
|
||||
}
|
||||
this.uid = header.uid
|
||||
this.gid = header.gid
|
||||
this.uname = header.uname
|
||||
this.gname = header.gname
|
||||
this.size = header.size
|
||||
this.mtime = header.mtime
|
||||
this.atime = header.atime
|
||||
this.ctime = header.ctime
|
||||
this.linkpath = normPath(header.linkpath)
|
||||
this.uname = header.uname
|
||||
this.gname = header.gname
|
||||
|
||||
if (ex) {
|
||||
this[SLURP](ex)
|
||||
}
|
||||
if (gex) {
|
||||
this[SLURP](gex, true)
|
||||
}
|
||||
}
|
||||
|
||||
write (data) {
|
||||
const writeLen = data.length
|
||||
if (writeLen > this.blockRemain) {
|
||||
throw new Error('writing more to entry than is appropriate')
|
||||
}
|
||||
|
||||
const r = this.remain
|
||||
const br = this.blockRemain
|
||||
this.remain = Math.max(0, r - writeLen)
|
||||
this.blockRemain = Math.max(0, br - writeLen)
|
||||
if (this.ignore) {
|
||||
return true
|
||||
}
|
||||
|
||||
if (r >= writeLen) {
|
||||
return super.write(data)
|
||||
}
|
||||
|
||||
// r < writeLen
|
||||
return super.write(data.slice(0, r))
|
||||
}
|
||||
|
||||
[SLURP] (ex, global) {
|
||||
for (const k in ex) {
|
||||
// we slurp in everything except for the path attribute in
|
||||
// a global extended header, because that's weird.
|
||||
if (ex[k] !== null && ex[k] !== undefined &&
|
||||
!(global && k === 'path')) {
|
||||
this[k] = k === 'path' || k === 'linkpath' ? normPath(ex[k]) : ex[k]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
246
electron/node_modules/cacache/node_modules/tar/lib/replace.js
generated
vendored
Normal file
246
electron/node_modules/cacache/node_modules/tar/lib/replace.js
generated
vendored
Normal file
|
|
@ -0,0 +1,246 @@
|
|||
'use strict'
|
||||
|
||||
// tar -r
|
||||
const hlo = require('./high-level-opt.js')
|
||||
const Pack = require('./pack.js')
|
||||
const fs = require('fs')
|
||||
const fsm = require('fs-minipass')
|
||||
const t = require('./list.js')
|
||||
const path = require('path')
|
||||
|
||||
// starting at the head of the file, read a Header
|
||||
// If the checksum is invalid, that's our position to start writing
|
||||
// If it is, jump forward by the specified size (round up to 512)
|
||||
// and try again.
|
||||
// Write the new Pack stream starting there.
|
||||
|
||||
const Header = require('./header.js')
|
||||
|
||||
module.exports = (opt_, files, cb) => {
|
||||
const opt = hlo(opt_)
|
||||
|
||||
if (!opt.file) {
|
||||
throw new TypeError('file is required')
|
||||
}
|
||||
|
||||
if (opt.gzip || opt.brotli || opt.file.endsWith('.br') || opt.file.endsWith('.tbr')) {
|
||||
throw new TypeError('cannot append to compressed archives')
|
||||
}
|
||||
|
||||
if (!files || !Array.isArray(files) || !files.length) {
|
||||
throw new TypeError('no files or directories specified')
|
||||
}
|
||||
|
||||
files = Array.from(files)
|
||||
|
||||
return opt.sync ? replaceSync(opt, files)
|
||||
: replace(opt, files, cb)
|
||||
}
|
||||
|
||||
const replaceSync = (opt, files) => {
|
||||
const p = new Pack.Sync(opt)
|
||||
|
||||
let threw = true
|
||||
let fd
|
||||
let position
|
||||
|
||||
try {
|
||||
try {
|
||||
fd = fs.openSync(opt.file, 'r+')
|
||||
} catch (er) {
|
||||
if (er.code === 'ENOENT') {
|
||||
fd = fs.openSync(opt.file, 'w+')
|
||||
} else {
|
||||
throw er
|
||||
}
|
||||
}
|
||||
|
||||
const st = fs.fstatSync(fd)
|
||||
const headBuf = Buffer.alloc(512)
|
||||
|
||||
POSITION: for (position = 0; position < st.size; position += 512) {
|
||||
for (let bufPos = 0, bytes = 0; bufPos < 512; bufPos += bytes) {
|
||||
bytes = fs.readSync(
|
||||
fd, headBuf, bufPos, headBuf.length - bufPos, position + bufPos
|
||||
)
|
||||
|
||||
if (position === 0 && headBuf[0] === 0x1f && headBuf[1] === 0x8b) {
|
||||
throw new Error('cannot append to compressed archives')
|
||||
}
|
||||
|
||||
if (!bytes) {
|
||||
break POSITION
|
||||
}
|
||||
}
|
||||
|
||||
const h = new Header(headBuf)
|
||||
if (!h.cksumValid) {
|
||||
break
|
||||
}
|
||||
const entryBlockSize = 512 * Math.ceil(h.size / 512)
|
||||
if (position + entryBlockSize + 512 > st.size) {
|
||||
break
|
||||
}
|
||||
// the 512 for the header we just parsed will be added as well
|
||||
// also jump ahead all the blocks for the body
|
||||
position += entryBlockSize
|
||||
if (opt.mtimeCache) {
|
||||
opt.mtimeCache.set(h.path, h.mtime)
|
||||
}
|
||||
}
|
||||
threw = false
|
||||
|
||||
streamSync(opt, p, position, fd, files)
|
||||
} finally {
|
||||
if (threw) {
|
||||
try {
|
||||
fs.closeSync(fd)
|
||||
} catch (er) {}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const streamSync = (opt, p, position, fd, files) => {
|
||||
const stream = new fsm.WriteStreamSync(opt.file, {
|
||||
fd: fd,
|
||||
start: position,
|
||||
})
|
||||
p.pipe(stream)
|
||||
addFilesSync(p, files)
|
||||
}
|
||||
|
||||
const replace = (opt, files, cb) => {
|
||||
files = Array.from(files)
|
||||
const p = new Pack(opt)
|
||||
|
||||
const getPos = (fd, size, cb_) => {
|
||||
const cb = (er, pos) => {
|
||||
if (er) {
|
||||
fs.close(fd, _ => cb_(er))
|
||||
} else {
|
||||
cb_(null, pos)
|
||||
}
|
||||
}
|
||||
|
||||
let position = 0
|
||||
if (size === 0) {
|
||||
return cb(null, 0)
|
||||
}
|
||||
|
||||
let bufPos = 0
|
||||
const headBuf = Buffer.alloc(512)
|
||||
const onread = (er, bytes) => {
|
||||
if (er) {
|
||||
return cb(er)
|
||||
}
|
||||
bufPos += bytes
|
||||
if (bufPos < 512 && bytes) {
|
||||
return fs.read(
|
||||
fd, headBuf, bufPos, headBuf.length - bufPos,
|
||||
position + bufPos, onread
|
||||
)
|
||||
}
|
||||
|
||||
if (position === 0 && headBuf[0] === 0x1f && headBuf[1] === 0x8b) {
|
||||
return cb(new Error('cannot append to compressed archives'))
|
||||
}
|
||||
|
||||
// truncated header
|
||||
if (bufPos < 512) {
|
||||
return cb(null, position)
|
||||
}
|
||||
|
||||
const h = new Header(headBuf)
|
||||
if (!h.cksumValid) {
|
||||
return cb(null, position)
|
||||
}
|
||||
|
||||
const entryBlockSize = 512 * Math.ceil(h.size / 512)
|
||||
if (position + entryBlockSize + 512 > size) {
|
||||
return cb(null, position)
|
||||
}
|
||||
|
||||
position += entryBlockSize + 512
|
||||
if (position >= size) {
|
||||
return cb(null, position)
|
||||
}
|
||||
|
||||
if (opt.mtimeCache) {
|
||||
opt.mtimeCache.set(h.path, h.mtime)
|
||||
}
|
||||
bufPos = 0
|
||||
fs.read(fd, headBuf, 0, 512, position, onread)
|
||||
}
|
||||
fs.read(fd, headBuf, 0, 512, position, onread)
|
||||
}
|
||||
|
||||
const promise = new Promise((resolve, reject) => {
|
||||
p.on('error', reject)
|
||||
let flag = 'r+'
|
||||
const onopen = (er, fd) => {
|
||||
if (er && er.code === 'ENOENT' && flag === 'r+') {
|
||||
flag = 'w+'
|
||||
return fs.open(opt.file, flag, onopen)
|
||||
}
|
||||
|
||||
if (er) {
|
||||
return reject(er)
|
||||
}
|
||||
|
||||
fs.fstat(fd, (er, st) => {
|
||||
if (er) {
|
||||
return fs.close(fd, () => reject(er))
|
||||
}
|
||||
|
||||
getPos(fd, st.size, (er, position) => {
|
||||
if (er) {
|
||||
return reject(er)
|
||||
}
|
||||
const stream = new fsm.WriteStream(opt.file, {
|
||||
fd: fd,
|
||||
start: position,
|
||||
})
|
||||
p.pipe(stream)
|
||||
stream.on('error', reject)
|
||||
stream.on('close', resolve)
|
||||
addFilesAsync(p, files)
|
||||
})
|
||||
})
|
||||
}
|
||||
fs.open(opt.file, flag, onopen)
|
||||
})
|
||||
|
||||
return cb ? promise.then(cb, cb) : promise
|
||||
}
|
||||
|
||||
const addFilesSync = (p, files) => {
|
||||
files.forEach(file => {
|
||||
if (file.charAt(0) === '@') {
|
||||
t({
|
||||
file: path.resolve(p.cwd, file.slice(1)),
|
||||
sync: true,
|
||||
noResume: true,
|
||||
onentry: entry => p.add(entry),
|
||||
})
|
||||
} else {
|
||||
p.add(file)
|
||||
}
|
||||
})
|
||||
p.end()
|
||||
}
|
||||
|
||||
const addFilesAsync = (p, files) => {
|
||||
while (files.length) {
|
||||
const file = files.shift()
|
||||
if (file.charAt(0) === '@') {
|
||||
return t({
|
||||
file: path.resolve(p.cwd, file.slice(1)),
|
||||
noResume: true,
|
||||
onentry: entry => p.add(entry),
|
||||
}).then(_ => addFilesAsync(p, files))
|
||||
} else {
|
||||
p.add(file)
|
||||
}
|
||||
}
|
||||
p.end()
|
||||
}
|
||||
24
electron/node_modules/cacache/node_modules/tar/lib/strip-absolute-path.js
generated
vendored
Normal file
24
electron/node_modules/cacache/node_modules/tar/lib/strip-absolute-path.js
generated
vendored
Normal file
|
|
@ -0,0 +1,24 @@
|
|||
// unix absolute paths are also absolute on win32, so we use this for both
|
||||
const { isAbsolute, parse } = require('path').win32
|
||||
|
||||
// returns [root, stripped]
|
||||
// Note that windows will think that //x/y/z/a has a "root" of //x/y, and in
|
||||
// those cases, we want to sanitize it to x/y/z/a, not z/a, so we strip /
|
||||
// explicitly if it's the first character.
|
||||
// drive-specific relative paths on Windows get their root stripped off even
|
||||
// though they are not absolute, so `c:../foo` becomes ['c:', '../foo']
|
||||
module.exports = path => {
|
||||
let r = ''
|
||||
|
||||
let parsed = parse(path)
|
||||
while (isAbsolute(path) || parsed.root) {
|
||||
// windows will think that //x/y/z has a "root" of //x/y/
|
||||
// but strip the //?/C:/ off of //?/C:/path
|
||||
const root = path.charAt(0) === '/' && path.slice(0, 4) !== '//?/' ? '/'
|
||||
: parsed.root
|
||||
path = path.slice(root.length)
|
||||
r += root
|
||||
parsed = parse(path)
|
||||
}
|
||||
return [r, path]
|
||||
}
|
||||
13
electron/node_modules/cacache/node_modules/tar/lib/strip-trailing-slashes.js
generated
vendored
Normal file
13
electron/node_modules/cacache/node_modules/tar/lib/strip-trailing-slashes.js
generated
vendored
Normal file
|
|
@ -0,0 +1,13 @@
|
|||
// warning: extremely hot code path.
|
||||
// This has been meticulously optimized for use
|
||||
// within npm install on large package trees.
|
||||
// Do not edit without careful benchmarking.
|
||||
module.exports = str => {
|
||||
let i = str.length - 1
|
||||
let slashesStart = -1
|
||||
while (i > -1 && str.charAt(i) === '/') {
|
||||
slashesStart = i
|
||||
i--
|
||||
}
|
||||
return slashesStart === -1 ? str : str.slice(0, slashesStart)
|
||||
}
|
||||
44
electron/node_modules/cacache/node_modules/tar/lib/types.js
generated
vendored
Normal file
44
electron/node_modules/cacache/node_modules/tar/lib/types.js
generated
vendored
Normal file
|
|
@ -0,0 +1,44 @@
|
|||
'use strict'
|
||||
// map types from key to human-friendly name
|
||||
exports.name = new Map([
|
||||
['0', 'File'],
|
||||
// same as File
|
||||
['', 'OldFile'],
|
||||
['1', 'Link'],
|
||||
['2', 'SymbolicLink'],
|
||||
// Devices and FIFOs aren't fully supported
|
||||
// they are parsed, but skipped when unpacking
|
||||
['3', 'CharacterDevice'],
|
||||
['4', 'BlockDevice'],
|
||||
['5', 'Directory'],
|
||||
['6', 'FIFO'],
|
||||
// same as File
|
||||
['7', 'ContiguousFile'],
|
||||
// pax headers
|
||||
['g', 'GlobalExtendedHeader'],
|
||||
['x', 'ExtendedHeader'],
|
||||
// vendor-specific stuff
|
||||
// skip
|
||||
['A', 'SolarisACL'],
|
||||
// like 5, but with data, which should be skipped
|
||||
['D', 'GNUDumpDir'],
|
||||
// metadata only, skip
|
||||
['I', 'Inode'],
|
||||
// data = link path of next file
|
||||
['K', 'NextFileHasLongLinkpath'],
|
||||
// data = path of next file
|
||||
['L', 'NextFileHasLongPath'],
|
||||
// skip
|
||||
['M', 'ContinuationFile'],
|
||||
// like L
|
||||
['N', 'OldGnuLongPath'],
|
||||
// skip
|
||||
['S', 'SparseFile'],
|
||||
// skip
|
||||
['V', 'TapeVolumeHeader'],
|
||||
// like x
|
||||
['X', 'OldExtendedHeader'],
|
||||
])
|
||||
|
||||
// map the other direction
|
||||
exports.code = new Map(Array.from(exports.name).map(kv => [kv[1], kv[0]]))
|
||||
923
electron/node_modules/cacache/node_modules/tar/lib/unpack.js
generated
vendored
Normal file
923
electron/node_modules/cacache/node_modules/tar/lib/unpack.js
generated
vendored
Normal file
|
|
@ -0,0 +1,923 @@
|
|||
'use strict'
|
||||
|
||||
// the PEND/UNPEND stuff tracks whether we're ready to emit end/close yet.
|
||||
// but the path reservations are required to avoid race conditions where
|
||||
// parallelized unpack ops may mess with one another, due to dependencies
|
||||
// (like a Link depending on its target) or destructive operations (like
|
||||
// clobbering an fs object to create one of a different type.)
|
||||
|
||||
const assert = require('assert')
|
||||
const Parser = require('./parse.js')
|
||||
const fs = require('fs')
|
||||
const fsm = require('fs-minipass')
|
||||
const path = require('path')
|
||||
const mkdir = require('./mkdir.js')
|
||||
const wc = require('./winchars.js')
|
||||
const pathReservations = require('./path-reservations.js')
|
||||
const stripAbsolutePath = require('./strip-absolute-path.js')
|
||||
const normPath = require('./normalize-windows-path.js')
|
||||
const stripSlash = require('./strip-trailing-slashes.js')
|
||||
const normalize = require('./normalize-unicode.js')
|
||||
|
||||
const ONENTRY = Symbol('onEntry')
|
||||
const CHECKFS = Symbol('checkFs')
|
||||
const CHECKFS2 = Symbol('checkFs2')
|
||||
const PRUNECACHE = Symbol('pruneCache')
|
||||
const ISREUSABLE = Symbol('isReusable')
|
||||
const MAKEFS = Symbol('makeFs')
|
||||
const FILE = Symbol('file')
|
||||
const DIRECTORY = Symbol('directory')
|
||||
const LINK = Symbol('link')
|
||||
const SYMLINK = Symbol('symlink')
|
||||
const HARDLINK = Symbol('hardlink')
|
||||
const UNSUPPORTED = Symbol('unsupported')
|
||||
const CHECKPATH = Symbol('checkPath')
|
||||
const MKDIR = Symbol('mkdir')
|
||||
const ONERROR = Symbol('onError')
|
||||
const PENDING = Symbol('pending')
|
||||
const PEND = Symbol('pend')
|
||||
const UNPEND = Symbol('unpend')
|
||||
const ENDED = Symbol('ended')
|
||||
const MAYBECLOSE = Symbol('maybeClose')
|
||||
const SKIP = Symbol('skip')
|
||||
const DOCHOWN = Symbol('doChown')
|
||||
const UID = Symbol('uid')
|
||||
const GID = Symbol('gid')
|
||||
const CHECKED_CWD = Symbol('checkedCwd')
|
||||
const crypto = require('crypto')
|
||||
const getFlag = require('./get-write-flag.js')
|
||||
const platform = process.env.TESTING_TAR_FAKE_PLATFORM || process.platform
|
||||
const isWindows = platform === 'win32'
|
||||
const DEFAULT_MAX_DEPTH = 1024
|
||||
|
||||
// Unlinks on Windows are not atomic.
|
||||
//
|
||||
// This means that if you have a file entry, followed by another
|
||||
// file entry with an identical name, and you cannot re-use the file
|
||||
// (because it's a hardlink, or because unlink:true is set, or it's
|
||||
// Windows, which does not have useful nlink values), then the unlink
|
||||
// will be committed to the disk AFTER the new file has been written
|
||||
// over the old one, deleting the new file.
|
||||
//
|
||||
// To work around this, on Windows systems, we rename the file and then
|
||||
// delete the renamed file. It's a sloppy kludge, but frankly, I do not
|
||||
// know of a better way to do this, given windows' non-atomic unlink
|
||||
// semantics.
|
||||
//
|
||||
// See: https://github.com/npm/node-tar/issues/183
|
||||
/* istanbul ignore next */
|
||||
const unlinkFile = (path, cb) => {
|
||||
if (!isWindows) {
|
||||
return fs.unlink(path, cb)
|
||||
}
|
||||
|
||||
const name = path + '.DELETE.' + crypto.randomBytes(16).toString('hex')
|
||||
fs.rename(path, name, er => {
|
||||
if (er) {
|
||||
return cb(er)
|
||||
}
|
||||
fs.unlink(name, cb)
|
||||
})
|
||||
}
|
||||
|
||||
/* istanbul ignore next */
|
||||
const unlinkFileSync = path => {
|
||||
if (!isWindows) {
|
||||
return fs.unlinkSync(path)
|
||||
}
|
||||
|
||||
const name = path + '.DELETE.' + crypto.randomBytes(16).toString('hex')
|
||||
fs.renameSync(path, name)
|
||||
fs.unlinkSync(name)
|
||||
}
|
||||
|
||||
// this.gid, entry.gid, this.processUid
|
||||
const uint32 = (a, b, c) =>
|
||||
a === a >>> 0 ? a
|
||||
: b === b >>> 0 ? b
|
||||
: c
|
||||
|
||||
// clear the cache if it's a case-insensitive unicode-squashing match.
|
||||
// we can't know if the current file system is case-sensitive or supports
|
||||
// unicode fully, so we check for similarity on the maximally compatible
|
||||
// representation. Err on the side of pruning, since all it's doing is
|
||||
// preventing lstats, and it's not the end of the world if we get a false
|
||||
// positive.
|
||||
// Note that on windows, we always drop the entire cache whenever a
|
||||
// symbolic link is encountered, because 8.3 filenames are impossible
|
||||
// to reason about, and collisions are hazards rather than just failures.
|
||||
const cacheKeyNormalize = path => stripSlash(normPath(normalize(path)))
|
||||
.toLowerCase()
|
||||
|
||||
const pruneCache = (cache, abs) => {
|
||||
abs = cacheKeyNormalize(abs)
|
||||
for (const path of cache.keys()) {
|
||||
const pnorm = cacheKeyNormalize(path)
|
||||
if (pnorm === abs || pnorm.indexOf(abs + '/') === 0) {
|
||||
cache.delete(path)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const dropCache = cache => {
|
||||
for (const key of cache.keys()) {
|
||||
cache.delete(key)
|
||||
}
|
||||
}
|
||||
|
||||
class Unpack extends Parser {
|
||||
constructor (opt) {
|
||||
if (!opt) {
|
||||
opt = {}
|
||||
}
|
||||
|
||||
opt.ondone = _ => {
|
||||
this[ENDED] = true
|
||||
this[MAYBECLOSE]()
|
||||
}
|
||||
|
||||
super(opt)
|
||||
|
||||
this[CHECKED_CWD] = false
|
||||
|
||||
this.reservations = pathReservations()
|
||||
|
||||
this.transform = typeof opt.transform === 'function' ? opt.transform : null
|
||||
|
||||
this.writable = true
|
||||
this.readable = false
|
||||
|
||||
this[PENDING] = 0
|
||||
this[ENDED] = false
|
||||
|
||||
this.dirCache = opt.dirCache || new Map()
|
||||
|
||||
if (typeof opt.uid === 'number' || typeof opt.gid === 'number') {
|
||||
// need both or neither
|
||||
if (typeof opt.uid !== 'number' || typeof opt.gid !== 'number') {
|
||||
throw new TypeError('cannot set owner without number uid and gid')
|
||||
}
|
||||
if (opt.preserveOwner) {
|
||||
throw new TypeError(
|
||||
'cannot preserve owner in archive and also set owner explicitly')
|
||||
}
|
||||
this.uid = opt.uid
|
||||
this.gid = opt.gid
|
||||
this.setOwner = true
|
||||
} else {
|
||||
this.uid = null
|
||||
this.gid = null
|
||||
this.setOwner = false
|
||||
}
|
||||
|
||||
// default true for root
|
||||
if (opt.preserveOwner === undefined && typeof opt.uid !== 'number') {
|
||||
this.preserveOwner = process.getuid && process.getuid() === 0
|
||||
} else {
|
||||
this.preserveOwner = !!opt.preserveOwner
|
||||
}
|
||||
|
||||
this.processUid = (this.preserveOwner || this.setOwner) && process.getuid ?
|
||||
process.getuid() : null
|
||||
this.processGid = (this.preserveOwner || this.setOwner) && process.getgid ?
|
||||
process.getgid() : null
|
||||
|
||||
// prevent excessively deep nesting of subfolders
|
||||
// set to `Infinity` to remove this restriction
|
||||
this.maxDepth = typeof opt.maxDepth === 'number'
|
||||
? opt.maxDepth
|
||||
: DEFAULT_MAX_DEPTH
|
||||
|
||||
// mostly just for testing, but useful in some cases.
|
||||
// Forcibly trigger a chown on every entry, no matter what
|
||||
this.forceChown = opt.forceChown === true
|
||||
|
||||
// turn ><?| in filenames into 0xf000-higher encoded forms
|
||||
this.win32 = !!opt.win32 || isWindows
|
||||
|
||||
// do not unpack over files that are newer than what's in the archive
|
||||
this.newer = !!opt.newer
|
||||
|
||||
// do not unpack over ANY files
|
||||
this.keep = !!opt.keep
|
||||
|
||||
// do not set mtime/atime of extracted entries
|
||||
this.noMtime = !!opt.noMtime
|
||||
|
||||
// allow .., absolute path entries, and unpacking through symlinks
|
||||
// without this, warn and skip .., relativize absolutes, and error
|
||||
// on symlinks in extraction path
|
||||
this.preservePaths = !!opt.preservePaths
|
||||
|
||||
// unlink files and links before writing. This breaks existing hard
|
||||
// links, and removes symlink directories rather than erroring
|
||||
this.unlink = !!opt.unlink
|
||||
|
||||
this.cwd = normPath(path.resolve(opt.cwd || process.cwd()))
|
||||
this.strip = +opt.strip || 0
|
||||
// if we're not chmodding, then we don't need the process umask
|
||||
this.processUmask = opt.noChmod ? 0 : process.umask()
|
||||
this.umask = typeof opt.umask === 'number' ? opt.umask : this.processUmask
|
||||
|
||||
// default mode for dirs created as parents
|
||||
this.dmode = opt.dmode || (0o0777 & (~this.umask))
|
||||
this.fmode = opt.fmode || (0o0666 & (~this.umask))
|
||||
|
||||
this.on('entry', entry => this[ONENTRY](entry))
|
||||
}
|
||||
|
||||
// a bad or damaged archive is a warning for Parser, but an error
|
||||
// when extracting. Mark those errors as unrecoverable, because
|
||||
// the Unpack contract cannot be met.
|
||||
warn (code, msg, data = {}) {
|
||||
if (code === 'TAR_BAD_ARCHIVE' || code === 'TAR_ABORT') {
|
||||
data.recoverable = false
|
||||
}
|
||||
return super.warn(code, msg, data)
|
||||
}
|
||||
|
||||
[MAYBECLOSE] () {
|
||||
if (this[ENDED] && this[PENDING] === 0) {
|
||||
this.emit('prefinish')
|
||||
this.emit('finish')
|
||||
this.emit('end')
|
||||
}
|
||||
}
|
||||
|
||||
[CHECKPATH] (entry) {
|
||||
const p = normPath(entry.path)
|
||||
const parts = p.split('/')
|
||||
|
||||
if (this.strip) {
|
||||
if (parts.length < this.strip) {
|
||||
return false
|
||||
}
|
||||
if (entry.type === 'Link') {
|
||||
const linkparts = normPath(entry.linkpath).split('/')
|
||||
if (linkparts.length >= this.strip) {
|
||||
entry.linkpath = linkparts.slice(this.strip).join('/')
|
||||
} else {
|
||||
return false
|
||||
}
|
||||
}
|
||||
parts.splice(0, this.strip)
|
||||
entry.path = parts.join('/')
|
||||
}
|
||||
|
||||
if (isFinite(this.maxDepth) && parts.length > this.maxDepth) {
|
||||
this.warn('TAR_ENTRY_ERROR', 'path excessively deep', {
|
||||
entry,
|
||||
path: p,
|
||||
depth: parts.length,
|
||||
maxDepth: this.maxDepth,
|
||||
})
|
||||
return false
|
||||
}
|
||||
|
||||
if (!this.preservePaths) {
|
||||
if (parts.includes('..') || isWindows && /^[a-z]:\.\.$/i.test(parts[0])) {
|
||||
this.warn('TAR_ENTRY_ERROR', `path contains '..'`, {
|
||||
entry,
|
||||
path: p,
|
||||
})
|
||||
return false
|
||||
}
|
||||
|
||||
// strip off the root
|
||||
const [root, stripped] = stripAbsolutePath(p)
|
||||
if (root) {
|
||||
entry.path = stripped
|
||||
this.warn('TAR_ENTRY_INFO', `stripping ${root} from absolute path`, {
|
||||
entry,
|
||||
path: p,
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
if (path.isAbsolute(entry.path)) {
|
||||
entry.absolute = normPath(path.resolve(entry.path))
|
||||
} else {
|
||||
entry.absolute = normPath(path.resolve(this.cwd, entry.path))
|
||||
}
|
||||
|
||||
// if we somehow ended up with a path that escapes the cwd, and we are
|
||||
// not in preservePaths mode, then something is fishy! This should have
|
||||
// been prevented above, so ignore this for coverage.
|
||||
/* istanbul ignore if - defense in depth */
|
||||
if (!this.preservePaths &&
|
||||
entry.absolute.indexOf(this.cwd + '/') !== 0 &&
|
||||
entry.absolute !== this.cwd) {
|
||||
this.warn('TAR_ENTRY_ERROR', 'path escaped extraction target', {
|
||||
entry,
|
||||
path: normPath(entry.path),
|
||||
resolvedPath: entry.absolute,
|
||||
cwd: this.cwd,
|
||||
})
|
||||
return false
|
||||
}
|
||||
|
||||
// an archive can set properties on the extraction directory, but it
|
||||
// may not replace the cwd with a different kind of thing entirely.
|
||||
if (entry.absolute === this.cwd &&
|
||||
entry.type !== 'Directory' &&
|
||||
entry.type !== 'GNUDumpDir') {
|
||||
return false
|
||||
}
|
||||
|
||||
// only encode : chars that aren't drive letter indicators
|
||||
if (this.win32) {
|
||||
const { root: aRoot } = path.win32.parse(entry.absolute)
|
||||
entry.absolute = aRoot + wc.encode(entry.absolute.slice(aRoot.length))
|
||||
const { root: pRoot } = path.win32.parse(entry.path)
|
||||
entry.path = pRoot + wc.encode(entry.path.slice(pRoot.length))
|
||||
}
|
||||
|
||||
return true
|
||||
}
|
||||
|
||||
[ONENTRY] (entry) {
|
||||
if (!this[CHECKPATH](entry)) {
|
||||
return entry.resume()
|
||||
}
|
||||
|
||||
assert.equal(typeof entry.absolute, 'string')
|
||||
|
||||
switch (entry.type) {
|
||||
case 'Directory':
|
||||
case 'GNUDumpDir':
|
||||
if (entry.mode) {
|
||||
entry.mode = entry.mode | 0o700
|
||||
}
|
||||
|
||||
// eslint-disable-next-line no-fallthrough
|
||||
case 'File':
|
||||
case 'OldFile':
|
||||
case 'ContiguousFile':
|
||||
case 'Link':
|
||||
case 'SymbolicLink':
|
||||
return this[CHECKFS](entry)
|
||||
|
||||
case 'CharacterDevice':
|
||||
case 'BlockDevice':
|
||||
case 'FIFO':
|
||||
default:
|
||||
return this[UNSUPPORTED](entry)
|
||||
}
|
||||
}
|
||||
|
||||
[ONERROR] (er, entry) {
|
||||
// Cwd has to exist, or else nothing works. That's serious.
|
||||
// Other errors are warnings, which raise the error in strict
|
||||
// mode, but otherwise continue on.
|
||||
if (er.name === 'CwdError') {
|
||||
this.emit('error', er)
|
||||
} else {
|
||||
this.warn('TAR_ENTRY_ERROR', er, { entry })
|
||||
this[UNPEND]()
|
||||
entry.resume()
|
||||
}
|
||||
}
|
||||
|
||||
[MKDIR] (dir, mode, cb) {
|
||||
mkdir(normPath(dir), {
|
||||
uid: this.uid,
|
||||
gid: this.gid,
|
||||
processUid: this.processUid,
|
||||
processGid: this.processGid,
|
||||
umask: this.processUmask,
|
||||
preserve: this.preservePaths,
|
||||
unlink: this.unlink,
|
||||
cache: this.dirCache,
|
||||
cwd: this.cwd,
|
||||
mode: mode,
|
||||
noChmod: this.noChmod,
|
||||
}, cb)
|
||||
}
|
||||
|
||||
[DOCHOWN] (entry) {
|
||||
// in preserve owner mode, chown if the entry doesn't match process
|
||||
// in set owner mode, chown if setting doesn't match process
|
||||
return this.forceChown ||
|
||||
this.preserveOwner &&
|
||||
(typeof entry.uid === 'number' && entry.uid !== this.processUid ||
|
||||
typeof entry.gid === 'number' && entry.gid !== this.processGid)
|
||||
||
|
||||
(typeof this.uid === 'number' && this.uid !== this.processUid ||
|
||||
typeof this.gid === 'number' && this.gid !== this.processGid)
|
||||
}
|
||||
|
||||
[UID] (entry) {
|
||||
return uint32(this.uid, entry.uid, this.processUid)
|
||||
}
|
||||
|
||||
[GID] (entry) {
|
||||
return uint32(this.gid, entry.gid, this.processGid)
|
||||
}
|
||||
|
||||
[FILE] (entry, fullyDone) {
|
||||
const mode = entry.mode & 0o7777 || this.fmode
|
||||
const stream = new fsm.WriteStream(entry.absolute, {
|
||||
flags: getFlag(entry.size),
|
||||
mode: mode,
|
||||
autoClose: false,
|
||||
})
|
||||
stream.on('error', er => {
|
||||
if (stream.fd) {
|
||||
fs.close(stream.fd, () => {})
|
||||
}
|
||||
|
||||
// flush all the data out so that we aren't left hanging
|
||||
// if the error wasn't actually fatal. otherwise the parse
|
||||
// is blocked, and we never proceed.
|
||||
stream.write = () => true
|
||||
this[ONERROR](er, entry)
|
||||
fullyDone()
|
||||
})
|
||||
|
||||
let actions = 1
|
||||
const done = er => {
|
||||
if (er) {
|
||||
/* istanbul ignore else - we should always have a fd by now */
|
||||
if (stream.fd) {
|
||||
fs.close(stream.fd, () => {})
|
||||
}
|
||||
|
||||
this[ONERROR](er, entry)
|
||||
fullyDone()
|
||||
return
|
||||
}
|
||||
|
||||
if (--actions === 0) {
|
||||
fs.close(stream.fd, er => {
|
||||
if (er) {
|
||||
this[ONERROR](er, entry)
|
||||
} else {
|
||||
this[UNPEND]()
|
||||
}
|
||||
fullyDone()
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
stream.on('finish', _ => {
|
||||
// if futimes fails, try utimes
|
||||
// if utimes fails, fail with the original error
|
||||
// same for fchown/chown
|
||||
const abs = entry.absolute
|
||||
const fd = stream.fd
|
||||
|
||||
if (entry.mtime && !this.noMtime) {
|
||||
actions++
|
||||
const atime = entry.atime || new Date()
|
||||
const mtime = entry.mtime
|
||||
fs.futimes(fd, atime, mtime, er =>
|
||||
er ? fs.utimes(abs, atime, mtime, er2 => done(er2 && er))
|
||||
: done())
|
||||
}
|
||||
|
||||
if (this[DOCHOWN](entry)) {
|
||||
actions++
|
||||
const uid = this[UID](entry)
|
||||
const gid = this[GID](entry)
|
||||
fs.fchown(fd, uid, gid, er =>
|
||||
er ? fs.chown(abs, uid, gid, er2 => done(er2 && er))
|
||||
: done())
|
||||
}
|
||||
|
||||
done()
|
||||
})
|
||||
|
||||
const tx = this.transform ? this.transform(entry) || entry : entry
|
||||
if (tx !== entry) {
|
||||
tx.on('error', er => {
|
||||
this[ONERROR](er, entry)
|
||||
fullyDone()
|
||||
})
|
||||
entry.pipe(tx)
|
||||
}
|
||||
tx.pipe(stream)
|
||||
}
|
||||
|
||||
[DIRECTORY] (entry, fullyDone) {
|
||||
const mode = entry.mode & 0o7777 || this.dmode
|
||||
this[MKDIR](entry.absolute, mode, er => {
|
||||
if (er) {
|
||||
this[ONERROR](er, entry)
|
||||
fullyDone()
|
||||
return
|
||||
}
|
||||
|
||||
let actions = 1
|
||||
const done = _ => {
|
||||
if (--actions === 0) {
|
||||
fullyDone()
|
||||
this[UNPEND]()
|
||||
entry.resume()
|
||||
}
|
||||
}
|
||||
|
||||
if (entry.mtime && !this.noMtime) {
|
||||
actions++
|
||||
fs.utimes(entry.absolute, entry.atime || new Date(), entry.mtime, done)
|
||||
}
|
||||
|
||||
if (this[DOCHOWN](entry)) {
|
||||
actions++
|
||||
fs.chown(entry.absolute, this[UID](entry), this[GID](entry), done)
|
||||
}
|
||||
|
||||
done()
|
||||
})
|
||||
}
|
||||
|
||||
[UNSUPPORTED] (entry) {
|
||||
entry.unsupported = true
|
||||
this.warn('TAR_ENTRY_UNSUPPORTED',
|
||||
`unsupported entry type: ${entry.type}`, { entry })
|
||||
entry.resume()
|
||||
}
|
||||
|
||||
[SYMLINK] (entry, done) {
|
||||
this[LINK](entry, entry.linkpath, 'symlink', done)
|
||||
}
|
||||
|
||||
[HARDLINK] (entry, done) {
|
||||
const linkpath = normPath(path.resolve(this.cwd, entry.linkpath))
|
||||
this[LINK](entry, linkpath, 'link', done)
|
||||
}
|
||||
|
||||
[PEND] () {
|
||||
this[PENDING]++
|
||||
}
|
||||
|
||||
[UNPEND] () {
|
||||
this[PENDING]--
|
||||
this[MAYBECLOSE]()
|
||||
}
|
||||
|
||||
[SKIP] (entry) {
|
||||
this[UNPEND]()
|
||||
entry.resume()
|
||||
}
|
||||
|
||||
// Check if we can reuse an existing filesystem entry safely and
|
||||
// overwrite it, rather than unlinking and recreating
|
||||
// Windows doesn't report a useful nlink, so we just never reuse entries
|
||||
[ISREUSABLE] (entry, st) {
|
||||
return entry.type === 'File' &&
|
||||
!this.unlink &&
|
||||
st.isFile() &&
|
||||
st.nlink <= 1 &&
|
||||
!isWindows
|
||||
}
|
||||
|
||||
// check if a thing is there, and if so, try to clobber it
|
||||
[CHECKFS] (entry) {
|
||||
this[PEND]()
|
||||
const paths = [entry.path]
|
||||
if (entry.linkpath) {
|
||||
paths.push(entry.linkpath)
|
||||
}
|
||||
this.reservations.reserve(paths, done => this[CHECKFS2](entry, done))
|
||||
}
|
||||
|
||||
[PRUNECACHE] (entry) {
|
||||
// if we are not creating a directory, and the path is in the dirCache,
|
||||
// then that means we are about to delete the directory we created
|
||||
// previously, and it is no longer going to be a directory, and neither
|
||||
// is any of its children.
|
||||
// If a symbolic link is encountered, all bets are off. There is no
|
||||
// reasonable way to sanitize the cache in such a way we will be able to
|
||||
// avoid having filesystem collisions. If this happens with a non-symlink
|
||||
// entry, it'll just fail to unpack, but a symlink to a directory, using an
|
||||
// 8.3 shortname or certain unicode attacks, can evade detection and lead
|
||||
// to arbitrary writes to anywhere on the system.
|
||||
if (entry.type === 'SymbolicLink') {
|
||||
dropCache(this.dirCache)
|
||||
} else if (entry.type !== 'Directory') {
|
||||
pruneCache(this.dirCache, entry.absolute)
|
||||
}
|
||||
}
|
||||
|
||||
[CHECKFS2] (entry, fullyDone) {
|
||||
this[PRUNECACHE](entry)
|
||||
|
||||
const done = er => {
|
||||
this[PRUNECACHE](entry)
|
||||
fullyDone(er)
|
||||
}
|
||||
|
||||
const checkCwd = () => {
|
||||
this[MKDIR](this.cwd, this.dmode, er => {
|
||||
if (er) {
|
||||
this[ONERROR](er, entry)
|
||||
done()
|
||||
return
|
||||
}
|
||||
this[CHECKED_CWD] = true
|
||||
start()
|
||||
})
|
||||
}
|
||||
|
||||
const start = () => {
|
||||
if (entry.absolute !== this.cwd) {
|
||||
const parent = normPath(path.dirname(entry.absolute))
|
||||
if (parent !== this.cwd) {
|
||||
return this[MKDIR](parent, this.dmode, er => {
|
||||
if (er) {
|
||||
this[ONERROR](er, entry)
|
||||
done()
|
||||
return
|
||||
}
|
||||
afterMakeParent()
|
||||
})
|
||||
}
|
||||
}
|
||||
afterMakeParent()
|
||||
}
|
||||
|
||||
const afterMakeParent = () => {
|
||||
fs.lstat(entry.absolute, (lstatEr, st) => {
|
||||
if (st && (this.keep || this.newer && st.mtime > entry.mtime)) {
|
||||
this[SKIP](entry)
|
||||
done()
|
||||
return
|
||||
}
|
||||
if (lstatEr || this[ISREUSABLE](entry, st)) {
|
||||
return this[MAKEFS](null, entry, done)
|
||||
}
|
||||
|
||||
if (st.isDirectory()) {
|
||||
if (entry.type === 'Directory') {
|
||||
const needChmod = !this.noChmod &&
|
||||
entry.mode &&
|
||||
(st.mode & 0o7777) !== entry.mode
|
||||
const afterChmod = er => this[MAKEFS](er, entry, done)
|
||||
if (!needChmod) {
|
||||
return afterChmod()
|
||||
}
|
||||
return fs.chmod(entry.absolute, entry.mode, afterChmod)
|
||||
}
|
||||
// Not a dir entry, have to remove it.
|
||||
// NB: the only way to end up with an entry that is the cwd
|
||||
// itself, in such a way that == does not detect, is a
|
||||
// tricky windows absolute path with UNC or 8.3 parts (and
|
||||
// preservePaths:true, or else it will have been stripped).
|
||||
// In that case, the user has opted out of path protections
|
||||
// explicitly, so if they blow away the cwd, c'est la vie.
|
||||
if (entry.absolute !== this.cwd) {
|
||||
return fs.rmdir(entry.absolute, er =>
|
||||
this[MAKEFS](er, entry, done))
|
||||
}
|
||||
}
|
||||
|
||||
// not a dir, and not reusable
|
||||
// don't remove if the cwd, we want that error
|
||||
if (entry.absolute === this.cwd) {
|
||||
return this[MAKEFS](null, entry, done)
|
||||
}
|
||||
|
||||
unlinkFile(entry.absolute, er =>
|
||||
this[MAKEFS](er, entry, done))
|
||||
})
|
||||
}
|
||||
|
||||
if (this[CHECKED_CWD]) {
|
||||
start()
|
||||
} else {
|
||||
checkCwd()
|
||||
}
|
||||
}
|
||||
|
||||
[MAKEFS] (er, entry, done) {
|
||||
if (er) {
|
||||
this[ONERROR](er, entry)
|
||||
done()
|
||||
return
|
||||
}
|
||||
|
||||
switch (entry.type) {
|
||||
case 'File':
|
||||
case 'OldFile':
|
||||
case 'ContiguousFile':
|
||||
return this[FILE](entry, done)
|
||||
|
||||
case 'Link':
|
||||
return this[HARDLINK](entry, done)
|
||||
|
||||
case 'SymbolicLink':
|
||||
return this[SYMLINK](entry, done)
|
||||
|
||||
case 'Directory':
|
||||
case 'GNUDumpDir':
|
||||
return this[DIRECTORY](entry, done)
|
||||
}
|
||||
}
|
||||
|
||||
[LINK] (entry, linkpath, link, done) {
|
||||
// XXX: get the type ('symlink' or 'junction') for windows
|
||||
fs[link](linkpath, entry.absolute, er => {
|
||||
if (er) {
|
||||
this[ONERROR](er, entry)
|
||||
} else {
|
||||
this[UNPEND]()
|
||||
entry.resume()
|
||||
}
|
||||
done()
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
const callSync = fn => {
|
||||
try {
|
||||
return [null, fn()]
|
||||
} catch (er) {
|
||||
return [er, null]
|
||||
}
|
||||
}
|
||||
class UnpackSync extends Unpack {
|
||||
[MAKEFS] (er, entry) {
|
||||
return super[MAKEFS](er, entry, () => {})
|
||||
}
|
||||
|
||||
[CHECKFS] (entry) {
|
||||
this[PRUNECACHE](entry)
|
||||
|
||||
if (!this[CHECKED_CWD]) {
|
||||
const er = this[MKDIR](this.cwd, this.dmode)
|
||||
if (er) {
|
||||
return this[ONERROR](er, entry)
|
||||
}
|
||||
this[CHECKED_CWD] = true
|
||||
}
|
||||
|
||||
// don't bother to make the parent if the current entry is the cwd,
|
||||
// we've already checked it.
|
||||
if (entry.absolute !== this.cwd) {
|
||||
const parent = normPath(path.dirname(entry.absolute))
|
||||
if (parent !== this.cwd) {
|
||||
const mkParent = this[MKDIR](parent, this.dmode)
|
||||
if (mkParent) {
|
||||
return this[ONERROR](mkParent, entry)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const [lstatEr, st] = callSync(() => fs.lstatSync(entry.absolute))
|
||||
if (st && (this.keep || this.newer && st.mtime > entry.mtime)) {
|
||||
return this[SKIP](entry)
|
||||
}
|
||||
|
||||
if (lstatEr || this[ISREUSABLE](entry, st)) {
|
||||
return this[MAKEFS](null, entry)
|
||||
}
|
||||
|
||||
if (st.isDirectory()) {
|
||||
if (entry.type === 'Directory') {
|
||||
const needChmod = !this.noChmod &&
|
||||
entry.mode &&
|
||||
(st.mode & 0o7777) !== entry.mode
|
||||
const [er] = needChmod ? callSync(() => {
|
||||
fs.chmodSync(entry.absolute, entry.mode)
|
||||
}) : []
|
||||
return this[MAKEFS](er, entry)
|
||||
}
|
||||
// not a dir entry, have to remove it
|
||||
const [er] = callSync(() => fs.rmdirSync(entry.absolute))
|
||||
this[MAKEFS](er, entry)
|
||||
}
|
||||
|
||||
// not a dir, and not reusable.
|
||||
// don't remove if it's the cwd, since we want that error.
|
||||
const [er] = entry.absolute === this.cwd ? []
|
||||
: callSync(() => unlinkFileSync(entry.absolute))
|
||||
this[MAKEFS](er, entry)
|
||||
}
|
||||
|
||||
[FILE] (entry, done) {
|
||||
const mode = entry.mode & 0o7777 || this.fmode
|
||||
|
||||
const oner = er => {
|
||||
let closeError
|
||||
try {
|
||||
fs.closeSync(fd)
|
||||
} catch (e) {
|
||||
closeError = e
|
||||
}
|
||||
if (er || closeError) {
|
||||
this[ONERROR](er || closeError, entry)
|
||||
}
|
||||
done()
|
||||
}
|
||||
|
||||
let fd
|
||||
try {
|
||||
fd = fs.openSync(entry.absolute, getFlag(entry.size), mode)
|
||||
} catch (er) {
|
||||
return oner(er)
|
||||
}
|
||||
const tx = this.transform ? this.transform(entry) || entry : entry
|
||||
if (tx !== entry) {
|
||||
tx.on('error', er => this[ONERROR](er, entry))
|
||||
entry.pipe(tx)
|
||||
}
|
||||
|
||||
tx.on('data', chunk => {
|
||||
try {
|
||||
fs.writeSync(fd, chunk, 0, chunk.length)
|
||||
} catch (er) {
|
||||
oner(er)
|
||||
}
|
||||
})
|
||||
|
||||
tx.on('end', _ => {
|
||||
let er = null
|
||||
// try both, falling futimes back to utimes
|
||||
// if either fails, handle the first error
|
||||
if (entry.mtime && !this.noMtime) {
|
||||
const atime = entry.atime || new Date()
|
||||
const mtime = entry.mtime
|
||||
try {
|
||||
fs.futimesSync(fd, atime, mtime)
|
||||
} catch (futimeser) {
|
||||
try {
|
||||
fs.utimesSync(entry.absolute, atime, mtime)
|
||||
} catch (utimeser) {
|
||||
er = futimeser
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (this[DOCHOWN](entry)) {
|
||||
const uid = this[UID](entry)
|
||||
const gid = this[GID](entry)
|
||||
|
||||
try {
|
||||
fs.fchownSync(fd, uid, gid)
|
||||
} catch (fchowner) {
|
||||
try {
|
||||
fs.chownSync(entry.absolute, uid, gid)
|
||||
} catch (chowner) {
|
||||
er = er || fchowner
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
oner(er)
|
||||
})
|
||||
}
|
||||
|
||||
[DIRECTORY] (entry, done) {
|
||||
const mode = entry.mode & 0o7777 || this.dmode
|
||||
const er = this[MKDIR](entry.absolute, mode)
|
||||
if (er) {
|
||||
this[ONERROR](er, entry)
|
||||
done()
|
||||
return
|
||||
}
|
||||
if (entry.mtime && !this.noMtime) {
|
||||
try {
|
||||
fs.utimesSync(entry.absolute, entry.atime || new Date(), entry.mtime)
|
||||
} catch (er) {}
|
||||
}
|
||||
if (this[DOCHOWN](entry)) {
|
||||
try {
|
||||
fs.chownSync(entry.absolute, this[UID](entry), this[GID](entry))
|
||||
} catch (er) {}
|
||||
}
|
||||
done()
|
||||
entry.resume()
|
||||
}
|
||||
|
||||
[MKDIR] (dir, mode) {
|
||||
try {
|
||||
return mkdir.sync(normPath(dir), {
|
||||
uid: this.uid,
|
||||
gid: this.gid,
|
||||
processUid: this.processUid,
|
||||
processGid: this.processGid,
|
||||
umask: this.processUmask,
|
||||
preserve: this.preservePaths,
|
||||
unlink: this.unlink,
|
||||
cache: this.dirCache,
|
||||
cwd: this.cwd,
|
||||
mode: mode,
|
||||
})
|
||||
} catch (er) {
|
||||
return er
|
||||
}
|
||||
}
|
||||
|
||||
[LINK] (entry, linkpath, link, done) {
|
||||
try {
|
||||
fs[link + 'Sync'](linkpath, entry.absolute)
|
||||
done()
|
||||
entry.resume()
|
||||
} catch (er) {
|
||||
return this[ONERROR](er, entry)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Unpack.Sync = UnpackSync
|
||||
module.exports = Unpack
|
||||
40
electron/node_modules/cacache/node_modules/tar/lib/update.js
generated
vendored
Normal file
40
electron/node_modules/cacache/node_modules/tar/lib/update.js
generated
vendored
Normal file
|
|
@ -0,0 +1,40 @@
|
|||
'use strict'
|
||||
|
||||
// tar -u
|
||||
|
||||
const hlo = require('./high-level-opt.js')
|
||||
const r = require('./replace.js')
|
||||
// just call tar.r with the filter and mtimeCache
|
||||
|
||||
module.exports = (opt_, files, cb) => {
|
||||
const opt = hlo(opt_)
|
||||
|
||||
if (!opt.file) {
|
||||
throw new TypeError('file is required')
|
||||
}
|
||||
|
||||
if (opt.gzip || opt.brotli || opt.file.endsWith('.br') || opt.file.endsWith('.tbr')) {
|
||||
throw new TypeError('cannot append to compressed archives')
|
||||
}
|
||||
|
||||
if (!files || !Array.isArray(files) || !files.length) {
|
||||
throw new TypeError('no files or directories specified')
|
||||
}
|
||||
|
||||
files = Array.from(files)
|
||||
|
||||
mtimeFilter(opt)
|
||||
return r(opt, files, cb)
|
||||
}
|
||||
|
||||
const mtimeFilter = opt => {
|
||||
const filter = opt.filter
|
||||
|
||||
if (!opt.mtimeCache) {
|
||||
opt.mtimeCache = new Map()
|
||||
}
|
||||
|
||||
opt.filter = filter ? (path, stat) =>
|
||||
filter(path, stat) && !(opt.mtimeCache.get(path) > stat.mtime)
|
||||
: (path, stat) => !(opt.mtimeCache.get(path) > stat.mtime)
|
||||
}
|
||||
24
electron/node_modules/cacache/node_modules/tar/lib/warn-mixin.js
generated
vendored
Normal file
24
electron/node_modules/cacache/node_modules/tar/lib/warn-mixin.js
generated
vendored
Normal file
|
|
@ -0,0 +1,24 @@
|
|||
'use strict'
|
||||
module.exports = Base => class extends Base {
|
||||
warn (code, message, data = {}) {
|
||||
if (this.file) {
|
||||
data.file = this.file
|
||||
}
|
||||
if (this.cwd) {
|
||||
data.cwd = this.cwd
|
||||
}
|
||||
data.code = message instanceof Error && message.code || code
|
||||
data.tarCode = code
|
||||
if (!this.strict && data.recoverable !== false) {
|
||||
if (message instanceof Error) {
|
||||
data = Object.assign(message, data)
|
||||
message = message.message
|
||||
}
|
||||
this.emit('warn', data.tarCode, message, data)
|
||||
} else if (message instanceof Error) {
|
||||
this.emit('error', Object.assign(message, data))
|
||||
} else {
|
||||
this.emit('error', Object.assign(new Error(`${code}: ${message}`), data))
|
||||
}
|
||||
}
|
||||
}
|
||||
23
electron/node_modules/cacache/node_modules/tar/lib/winchars.js
generated
vendored
Normal file
23
electron/node_modules/cacache/node_modules/tar/lib/winchars.js
generated
vendored
Normal file
|
|
@ -0,0 +1,23 @@
|
|||
'use strict'
|
||||
|
||||
// When writing files on Windows, translate the characters to their
|
||||
// 0xf000 higher-encoded versions.
|
||||
|
||||
const raw = [
|
||||
'|',
|
||||
'<',
|
||||
'>',
|
||||
'?',
|
||||
':',
|
||||
]
|
||||
|
||||
const win = raw.map(char =>
|
||||
String.fromCharCode(0xf000 + char.charCodeAt(0)))
|
||||
|
||||
const toWin = new Map(raw.map((char, i) => [char, win[i]]))
|
||||
const toRaw = new Map(win.map((char, i) => [char, raw[i]]))
|
||||
|
||||
module.exports = {
|
||||
encode: s => raw.reduce((s, c) => s.split(c).join(toWin.get(c)), s),
|
||||
decode: s => win.reduce((s, c) => s.split(c).join(toRaw.get(c)), s),
|
||||
}
|
||||
546
electron/node_modules/cacache/node_modules/tar/lib/write-entry.js
generated
vendored
Normal file
546
electron/node_modules/cacache/node_modules/tar/lib/write-entry.js
generated
vendored
Normal file
|
|
@ -0,0 +1,546 @@
|
|||
'use strict'
|
||||
const { Minipass } = require('minipass')
|
||||
const Pax = require('./pax.js')
|
||||
const Header = require('./header.js')
|
||||
const fs = require('fs')
|
||||
const path = require('path')
|
||||
const normPath = require('./normalize-windows-path.js')
|
||||
const stripSlash = require('./strip-trailing-slashes.js')
|
||||
|
||||
const prefixPath = (path, prefix) => {
|
||||
if (!prefix) {
|
||||
return normPath(path)
|
||||
}
|
||||
path = normPath(path).replace(/^\.(\/|$)/, '')
|
||||
return stripSlash(prefix) + '/' + path
|
||||
}
|
||||
|
||||
const maxReadSize = 16 * 1024 * 1024
|
||||
const PROCESS = Symbol('process')
|
||||
const FILE = Symbol('file')
|
||||
const DIRECTORY = Symbol('directory')
|
||||
const SYMLINK = Symbol('symlink')
|
||||
const HARDLINK = Symbol('hardlink')
|
||||
const HEADER = Symbol('header')
|
||||
const READ = Symbol('read')
|
||||
const LSTAT = Symbol('lstat')
|
||||
const ONLSTAT = Symbol('onlstat')
|
||||
const ONREAD = Symbol('onread')
|
||||
const ONREADLINK = Symbol('onreadlink')
|
||||
const OPENFILE = Symbol('openfile')
|
||||
const ONOPENFILE = Symbol('onopenfile')
|
||||
const CLOSE = Symbol('close')
|
||||
const MODE = Symbol('mode')
|
||||
const AWAITDRAIN = Symbol('awaitDrain')
|
||||
const ONDRAIN = Symbol('ondrain')
|
||||
const PREFIX = Symbol('prefix')
|
||||
const HAD_ERROR = Symbol('hadError')
|
||||
const warner = require('./warn-mixin.js')
|
||||
const winchars = require('./winchars.js')
|
||||
const stripAbsolutePath = require('./strip-absolute-path.js')
|
||||
|
||||
const modeFix = require('./mode-fix.js')
|
||||
|
||||
const WriteEntry = warner(class WriteEntry extends Minipass {
|
||||
constructor (p, opt) {
|
||||
opt = opt || {}
|
||||
super(opt)
|
||||
if (typeof p !== 'string') {
|
||||
throw new TypeError('path is required')
|
||||
}
|
||||
this.path = normPath(p)
|
||||
// suppress atime, ctime, uid, gid, uname, gname
|
||||
this.portable = !!opt.portable
|
||||
// until node has builtin pwnam functions, this'll have to do
|
||||
this.myuid = process.getuid && process.getuid() || 0
|
||||
this.myuser = process.env.USER || ''
|
||||
this.maxReadSize = opt.maxReadSize || maxReadSize
|
||||
this.linkCache = opt.linkCache || new Map()
|
||||
this.statCache = opt.statCache || new Map()
|
||||
this.preservePaths = !!opt.preservePaths
|
||||
this.cwd = normPath(opt.cwd || process.cwd())
|
||||
this.strict = !!opt.strict
|
||||
this.noPax = !!opt.noPax
|
||||
this.noMtime = !!opt.noMtime
|
||||
this.mtime = opt.mtime || null
|
||||
this.prefix = opt.prefix ? normPath(opt.prefix) : null
|
||||
|
||||
this.fd = null
|
||||
this.blockLen = null
|
||||
this.blockRemain = null
|
||||
this.buf = null
|
||||
this.offset = null
|
||||
this.length = null
|
||||
this.pos = null
|
||||
this.remain = null
|
||||
|
||||
if (typeof opt.onwarn === 'function') {
|
||||
this.on('warn', opt.onwarn)
|
||||
}
|
||||
|
||||
let pathWarn = false
|
||||
if (!this.preservePaths) {
|
||||
const [root, stripped] = stripAbsolutePath(this.path)
|
||||
if (root) {
|
||||
this.path = stripped
|
||||
pathWarn = root
|
||||
}
|
||||
}
|
||||
|
||||
this.win32 = !!opt.win32 || process.platform === 'win32'
|
||||
if (this.win32) {
|
||||
// force the \ to / normalization, since we might not *actually*
|
||||
// be on windows, but want \ to be considered a path separator.
|
||||
this.path = winchars.decode(this.path.replace(/\\/g, '/'))
|
||||
p = p.replace(/\\/g, '/')
|
||||
}
|
||||
|
||||
this.absolute = normPath(opt.absolute || path.resolve(this.cwd, p))
|
||||
|
||||
if (this.path === '') {
|
||||
this.path = './'
|
||||
}
|
||||
|
||||
if (pathWarn) {
|
||||
this.warn('TAR_ENTRY_INFO', `stripping ${pathWarn} from absolute path`, {
|
||||
entry: this,
|
||||
path: pathWarn + this.path,
|
||||
})
|
||||
}
|
||||
|
||||
if (this.statCache.has(this.absolute)) {
|
||||
this[ONLSTAT](this.statCache.get(this.absolute))
|
||||
} else {
|
||||
this[LSTAT]()
|
||||
}
|
||||
}
|
||||
|
||||
emit (ev, ...data) {
|
||||
if (ev === 'error') {
|
||||
this[HAD_ERROR] = true
|
||||
}
|
||||
return super.emit(ev, ...data)
|
||||
}
|
||||
|
||||
[LSTAT] () {
|
||||
fs.lstat(this.absolute, (er, stat) => {
|
||||
if (er) {
|
||||
return this.emit('error', er)
|
||||
}
|
||||
this[ONLSTAT](stat)
|
||||
})
|
||||
}
|
||||
|
||||
[ONLSTAT] (stat) {
|
||||
this.statCache.set(this.absolute, stat)
|
||||
this.stat = stat
|
||||
if (!stat.isFile()) {
|
||||
stat.size = 0
|
||||
}
|
||||
this.type = getType(stat)
|
||||
this.emit('stat', stat)
|
||||
this[PROCESS]()
|
||||
}
|
||||
|
||||
[PROCESS] () {
|
||||
switch (this.type) {
|
||||
case 'File': return this[FILE]()
|
||||
case 'Directory': return this[DIRECTORY]()
|
||||
case 'SymbolicLink': return this[SYMLINK]()
|
||||
// unsupported types are ignored.
|
||||
default: return this.end()
|
||||
}
|
||||
}
|
||||
|
||||
[MODE] (mode) {
|
||||
return modeFix(mode, this.type === 'Directory', this.portable)
|
||||
}
|
||||
|
||||
[PREFIX] (path) {
|
||||
return prefixPath(path, this.prefix)
|
||||
}
|
||||
|
||||
[HEADER] () {
|
||||
if (this.type === 'Directory' && this.portable) {
|
||||
this.noMtime = true
|
||||
}
|
||||
|
||||
this.header = new Header({
|
||||
path: this[PREFIX](this.path),
|
||||
// only apply the prefix to hard links.
|
||||
linkpath: this.type === 'Link' ? this[PREFIX](this.linkpath)
|
||||
: this.linkpath,
|
||||
// only the permissions and setuid/setgid/sticky bitflags
|
||||
// not the higher-order bits that specify file type
|
||||
mode: this[MODE](this.stat.mode),
|
||||
uid: this.portable ? null : this.stat.uid,
|
||||
gid: this.portable ? null : this.stat.gid,
|
||||
size: this.stat.size,
|
||||
mtime: this.noMtime ? null : this.mtime || this.stat.mtime,
|
||||
type: this.type,
|
||||
uname: this.portable ? null :
|
||||
this.stat.uid === this.myuid ? this.myuser : '',
|
||||
atime: this.portable ? null : this.stat.atime,
|
||||
ctime: this.portable ? null : this.stat.ctime,
|
||||
})
|
||||
|
||||
if (this.header.encode() && !this.noPax) {
|
||||
super.write(new Pax({
|
||||
atime: this.portable ? null : this.header.atime,
|
||||
ctime: this.portable ? null : this.header.ctime,
|
||||
gid: this.portable ? null : this.header.gid,
|
||||
mtime: this.noMtime ? null : this.mtime || this.header.mtime,
|
||||
path: this[PREFIX](this.path),
|
||||
linkpath: this.type === 'Link' ? this[PREFIX](this.linkpath)
|
||||
: this.linkpath,
|
||||
size: this.header.size,
|
||||
uid: this.portable ? null : this.header.uid,
|
||||
uname: this.portable ? null : this.header.uname,
|
||||
dev: this.portable ? null : this.stat.dev,
|
||||
ino: this.portable ? null : this.stat.ino,
|
||||
nlink: this.portable ? null : this.stat.nlink,
|
||||
}).encode())
|
||||
}
|
||||
super.write(this.header.block)
|
||||
}
|
||||
|
||||
[DIRECTORY] () {
|
||||
if (this.path.slice(-1) !== '/') {
|
||||
this.path += '/'
|
||||
}
|
||||
this.stat.size = 0
|
||||
this[HEADER]()
|
||||
this.end()
|
||||
}
|
||||
|
||||
[SYMLINK] () {
|
||||
fs.readlink(this.absolute, (er, linkpath) => {
|
||||
if (er) {
|
||||
return this.emit('error', er)
|
||||
}
|
||||
this[ONREADLINK](linkpath)
|
||||
})
|
||||
}
|
||||
|
||||
[ONREADLINK] (linkpath) {
|
||||
this.linkpath = normPath(linkpath)
|
||||
this[HEADER]()
|
||||
this.end()
|
||||
}
|
||||
|
||||
[HARDLINK] (linkpath) {
|
||||
this.type = 'Link'
|
||||
this.linkpath = normPath(path.relative(this.cwd, linkpath))
|
||||
this.stat.size = 0
|
||||
this[HEADER]()
|
||||
this.end()
|
||||
}
|
||||
|
||||
[FILE] () {
|
||||
if (this.stat.nlink > 1) {
|
||||
const linkKey = this.stat.dev + ':' + this.stat.ino
|
||||
if (this.linkCache.has(linkKey)) {
|
||||
const linkpath = this.linkCache.get(linkKey)
|
||||
if (linkpath.indexOf(this.cwd) === 0) {
|
||||
return this[HARDLINK](linkpath)
|
||||
}
|
||||
}
|
||||
this.linkCache.set(linkKey, this.absolute)
|
||||
}
|
||||
|
||||
this[HEADER]()
|
||||
if (this.stat.size === 0) {
|
||||
return this.end()
|
||||
}
|
||||
|
||||
this[OPENFILE]()
|
||||
}
|
||||
|
||||
[OPENFILE] () {
|
||||
fs.open(this.absolute, 'r', (er, fd) => {
|
||||
if (er) {
|
||||
return this.emit('error', er)
|
||||
}
|
||||
this[ONOPENFILE](fd)
|
||||
})
|
||||
}
|
||||
|
||||
[ONOPENFILE] (fd) {
|
||||
this.fd = fd
|
||||
if (this[HAD_ERROR]) {
|
||||
return this[CLOSE]()
|
||||
}
|
||||
|
||||
this.blockLen = 512 * Math.ceil(this.stat.size / 512)
|
||||
this.blockRemain = this.blockLen
|
||||
const bufLen = Math.min(this.blockLen, this.maxReadSize)
|
||||
this.buf = Buffer.allocUnsafe(bufLen)
|
||||
this.offset = 0
|
||||
this.pos = 0
|
||||
this.remain = this.stat.size
|
||||
this.length = this.buf.length
|
||||
this[READ]()
|
||||
}
|
||||
|
||||
[READ] () {
|
||||
const { fd, buf, offset, length, pos } = this
|
||||
fs.read(fd, buf, offset, length, pos, (er, bytesRead) => {
|
||||
if (er) {
|
||||
// ignoring the error from close(2) is a bad practice, but at
|
||||
// this point we already have an error, don't need another one
|
||||
return this[CLOSE](() => this.emit('error', er))
|
||||
}
|
||||
this[ONREAD](bytesRead)
|
||||
})
|
||||
}
|
||||
|
||||
[CLOSE] (cb) {
|
||||
fs.close(this.fd, cb)
|
||||
}
|
||||
|
||||
[ONREAD] (bytesRead) {
|
||||
if (bytesRead <= 0 && this.remain > 0) {
|
||||
const er = new Error('encountered unexpected EOF')
|
||||
er.path = this.absolute
|
||||
er.syscall = 'read'
|
||||
er.code = 'EOF'
|
||||
return this[CLOSE](() => this.emit('error', er))
|
||||
}
|
||||
|
||||
if (bytesRead > this.remain) {
|
||||
const er = new Error('did not encounter expected EOF')
|
||||
er.path = this.absolute
|
||||
er.syscall = 'read'
|
||||
er.code = 'EOF'
|
||||
return this[CLOSE](() => this.emit('error', er))
|
||||
}
|
||||
|
||||
// null out the rest of the buffer, if we could fit the block padding
|
||||
// at the end of this loop, we've incremented bytesRead and this.remain
|
||||
// to be incremented up to the blockRemain level, as if we had expected
|
||||
// to get a null-padded file, and read it until the end. then we will
|
||||
// decrement both remain and blockRemain by bytesRead, and know that we
|
||||
// reached the expected EOF, without any null buffer to append.
|
||||
if (bytesRead === this.remain) {
|
||||
for (let i = bytesRead; i < this.length && bytesRead < this.blockRemain; i++) {
|
||||
this.buf[i + this.offset] = 0
|
||||
bytesRead++
|
||||
this.remain++
|
||||
}
|
||||
}
|
||||
|
||||
const writeBuf = this.offset === 0 && bytesRead === this.buf.length ?
|
||||
this.buf : this.buf.slice(this.offset, this.offset + bytesRead)
|
||||
|
||||
const flushed = this.write(writeBuf)
|
||||
if (!flushed) {
|
||||
this[AWAITDRAIN](() => this[ONDRAIN]())
|
||||
} else {
|
||||
this[ONDRAIN]()
|
||||
}
|
||||
}
|
||||
|
||||
[AWAITDRAIN] (cb) {
|
||||
this.once('drain', cb)
|
||||
}
|
||||
|
||||
write (writeBuf) {
|
||||
if (this.blockRemain < writeBuf.length) {
|
||||
const er = new Error('writing more data than expected')
|
||||
er.path = this.absolute
|
||||
return this.emit('error', er)
|
||||
}
|
||||
this.remain -= writeBuf.length
|
||||
this.blockRemain -= writeBuf.length
|
||||
this.pos += writeBuf.length
|
||||
this.offset += writeBuf.length
|
||||
return super.write(writeBuf)
|
||||
}
|
||||
|
||||
[ONDRAIN] () {
|
||||
if (!this.remain) {
|
||||
if (this.blockRemain) {
|
||||
super.write(Buffer.alloc(this.blockRemain))
|
||||
}
|
||||
return this[CLOSE](er => er ? this.emit('error', er) : this.end())
|
||||
}
|
||||
|
||||
if (this.offset >= this.length) {
|
||||
// if we only have a smaller bit left to read, alloc a smaller buffer
|
||||
// otherwise, keep it the same length it was before.
|
||||
this.buf = Buffer.allocUnsafe(Math.min(this.blockRemain, this.buf.length))
|
||||
this.offset = 0
|
||||
}
|
||||
this.length = this.buf.length - this.offset
|
||||
this[READ]()
|
||||
}
|
||||
})
|
||||
|
||||
class WriteEntrySync extends WriteEntry {
|
||||
[LSTAT] () {
|
||||
this[ONLSTAT](fs.lstatSync(this.absolute))
|
||||
}
|
||||
|
||||
[SYMLINK] () {
|
||||
this[ONREADLINK](fs.readlinkSync(this.absolute))
|
||||
}
|
||||
|
||||
[OPENFILE] () {
|
||||
this[ONOPENFILE](fs.openSync(this.absolute, 'r'))
|
||||
}
|
||||
|
||||
[READ] () {
|
||||
let threw = true
|
||||
try {
|
||||
const { fd, buf, offset, length, pos } = this
|
||||
const bytesRead = fs.readSync(fd, buf, offset, length, pos)
|
||||
this[ONREAD](bytesRead)
|
||||
threw = false
|
||||
} finally {
|
||||
// ignoring the error from close(2) is a bad practice, but at
|
||||
// this point we already have an error, don't need another one
|
||||
if (threw) {
|
||||
try {
|
||||
this[CLOSE](() => {})
|
||||
} catch (er) {}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
[AWAITDRAIN] (cb) {
|
||||
cb()
|
||||
}
|
||||
|
||||
[CLOSE] (cb) {
|
||||
fs.closeSync(this.fd)
|
||||
cb()
|
||||
}
|
||||
}
|
||||
|
||||
const WriteEntryTar = warner(class WriteEntryTar extends Minipass {
|
||||
constructor (readEntry, opt) {
|
||||
opt = opt || {}
|
||||
super(opt)
|
||||
this.preservePaths = !!opt.preservePaths
|
||||
this.portable = !!opt.portable
|
||||
this.strict = !!opt.strict
|
||||
this.noPax = !!opt.noPax
|
||||
this.noMtime = !!opt.noMtime
|
||||
|
||||
this.readEntry = readEntry
|
||||
this.type = readEntry.type
|
||||
if (this.type === 'Directory' && this.portable) {
|
||||
this.noMtime = true
|
||||
}
|
||||
|
||||
this.prefix = opt.prefix || null
|
||||
|
||||
this.path = normPath(readEntry.path)
|
||||
this.mode = this[MODE](readEntry.mode)
|
||||
this.uid = this.portable ? null : readEntry.uid
|
||||
this.gid = this.portable ? null : readEntry.gid
|
||||
this.uname = this.portable ? null : readEntry.uname
|
||||
this.gname = this.portable ? null : readEntry.gname
|
||||
this.size = readEntry.size
|
||||
this.mtime = this.noMtime ? null : opt.mtime || readEntry.mtime
|
||||
this.atime = this.portable ? null : readEntry.atime
|
||||
this.ctime = this.portable ? null : readEntry.ctime
|
||||
this.linkpath = normPath(readEntry.linkpath)
|
||||
|
||||
if (typeof opt.onwarn === 'function') {
|
||||
this.on('warn', opt.onwarn)
|
||||
}
|
||||
|
||||
let pathWarn = false
|
||||
if (!this.preservePaths) {
|
||||
const [root, stripped] = stripAbsolutePath(this.path)
|
||||
if (root) {
|
||||
this.path = stripped
|
||||
pathWarn = root
|
||||
}
|
||||
}
|
||||
|
||||
this.remain = readEntry.size
|
||||
this.blockRemain = readEntry.startBlockSize
|
||||
|
||||
this.header = new Header({
|
||||
path: this[PREFIX](this.path),
|
||||
linkpath: this.type === 'Link' ? this[PREFIX](this.linkpath)
|
||||
: this.linkpath,
|
||||
// only the permissions and setuid/setgid/sticky bitflags
|
||||
// not the higher-order bits that specify file type
|
||||
mode: this.mode,
|
||||
uid: this.portable ? null : this.uid,
|
||||
gid: this.portable ? null : this.gid,
|
||||
size: this.size,
|
||||
mtime: this.noMtime ? null : this.mtime,
|
||||
type: this.type,
|
||||
uname: this.portable ? null : this.uname,
|
||||
atime: this.portable ? null : this.atime,
|
||||
ctime: this.portable ? null : this.ctime,
|
||||
})
|
||||
|
||||
if (pathWarn) {
|
||||
this.warn('TAR_ENTRY_INFO', `stripping ${pathWarn} from absolute path`, {
|
||||
entry: this,
|
||||
path: pathWarn + this.path,
|
||||
})
|
||||
}
|
||||
|
||||
if (this.header.encode() && !this.noPax) {
|
||||
super.write(new Pax({
|
||||
atime: this.portable ? null : this.atime,
|
||||
ctime: this.portable ? null : this.ctime,
|
||||
gid: this.portable ? null : this.gid,
|
||||
mtime: this.noMtime ? null : this.mtime,
|
||||
path: this[PREFIX](this.path),
|
||||
linkpath: this.type === 'Link' ? this[PREFIX](this.linkpath)
|
||||
: this.linkpath,
|
||||
size: this.size,
|
||||
uid: this.portable ? null : this.uid,
|
||||
uname: this.portable ? null : this.uname,
|
||||
dev: this.portable ? null : this.readEntry.dev,
|
||||
ino: this.portable ? null : this.readEntry.ino,
|
||||
nlink: this.portable ? null : this.readEntry.nlink,
|
||||
}).encode())
|
||||
}
|
||||
|
||||
super.write(this.header.block)
|
||||
readEntry.pipe(this)
|
||||
}
|
||||
|
||||
[PREFIX] (path) {
|
||||
return prefixPath(path, this.prefix)
|
||||
}
|
||||
|
||||
[MODE] (mode) {
|
||||
return modeFix(mode, this.type === 'Directory', this.portable)
|
||||
}
|
||||
|
||||
write (data) {
|
||||
const writeLen = data.length
|
||||
if (writeLen > this.blockRemain) {
|
||||
throw new Error('writing more to entry than is appropriate')
|
||||
}
|
||||
this.blockRemain -= writeLen
|
||||
return super.write(data)
|
||||
}
|
||||
|
||||
end () {
|
||||
if (this.blockRemain) {
|
||||
super.write(Buffer.alloc(this.blockRemain))
|
||||
}
|
||||
return super.end()
|
||||
}
|
||||
})
|
||||
|
||||
WriteEntry.Sync = WriteEntrySync
|
||||
WriteEntry.Tar = WriteEntryTar
|
||||
|
||||
const getType = stat =>
|
||||
stat.isFile() ? 'File'
|
||||
: stat.isDirectory() ? 'Directory'
|
||||
: stat.isSymbolicLink() ? 'SymbolicLink'
|
||||
: 'Unsupported'
|
||||
|
||||
module.exports = WriteEntry
|
||||
15
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/LICENSE
generated
vendored
Normal file
15
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/LICENSE
generated
vendored
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
The ISC License
|
||||
|
||||
Copyright (c) 2017-2023 npm, Inc., Isaac Z. Schlueter, and Contributors
|
||||
|
||||
Permission to use, copy, modify, and/or distribute this software for any
|
||||
purpose with or without fee is hereby granted, provided that the above
|
||||
copyright notice and this permission notice appear in all copies.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
||||
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
||||
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
||||
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
||||
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR
|
||||
IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
769
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/README.md
generated
vendored
Normal file
769
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/README.md
generated
vendored
Normal file
|
|
@ -0,0 +1,769 @@
|
|||
# minipass
|
||||
|
||||
A _very_ minimal implementation of a [PassThrough
|
||||
stream](https://nodejs.org/api/stream.html#stream_class_stream_passthrough)
|
||||
|
||||
[It's very
|
||||
fast](https://docs.google.com/spreadsheets/d/1K_HR5oh3r80b8WVMWCPPjfuWXUgfkmhlX7FGI6JJ8tY/edit?usp=sharing)
|
||||
for objects, strings, and buffers.
|
||||
|
||||
Supports `pipe()`ing (including multi-`pipe()` and backpressure
|
||||
transmission), buffering data until either a `data` event handler
|
||||
or `pipe()` is added (so you don't lose the first chunk), and
|
||||
most other cases where PassThrough is a good idea.
|
||||
|
||||
There is a `read()` method, but it's much more efficient to
|
||||
consume data from this stream via `'data'` events or by calling
|
||||
`pipe()` into some other stream. Calling `read()` requires the
|
||||
buffer to be flattened in some cases, which requires copying
|
||||
memory.
|
||||
|
||||
If you set `objectMode: true` in the options, then whatever is
|
||||
written will be emitted. Otherwise, it'll do a minimal amount of
|
||||
Buffer copying to ensure proper Streams semantics when `read(n)`
|
||||
is called.
|
||||
|
||||
`objectMode` can also be set by doing `stream.objectMode = true`,
|
||||
or by writing any non-string/non-buffer data. `objectMode` cannot
|
||||
be set to false once it is set.
|
||||
|
||||
This is not a `through` or `through2` stream. It doesn't
|
||||
transform the data, it just passes it right through. If you want
|
||||
to transform the data, extend the class, and override the
|
||||
`write()` method. Once you're done transforming the data however
|
||||
you want, call `super.write()` with the transform output.
|
||||
|
||||
For some examples of streams that extend Minipass in various
|
||||
ways, check out:
|
||||
|
||||
- [minizlib](http://npm.im/minizlib)
|
||||
- [fs-minipass](http://npm.im/fs-minipass)
|
||||
- [tar](http://npm.im/tar)
|
||||
- [minipass-collect](http://npm.im/minipass-collect)
|
||||
- [minipass-flush](http://npm.im/minipass-flush)
|
||||
- [minipass-pipeline](http://npm.im/minipass-pipeline)
|
||||
- [tap](http://npm.im/tap)
|
||||
- [tap-parser](http://npm.im/tap-parser)
|
||||
- [treport](http://npm.im/treport)
|
||||
- [minipass-fetch](http://npm.im/minipass-fetch)
|
||||
- [pacote](http://npm.im/pacote)
|
||||
- [make-fetch-happen](http://npm.im/make-fetch-happen)
|
||||
- [cacache](http://npm.im/cacache)
|
||||
- [ssri](http://npm.im/ssri)
|
||||
- [npm-registry-fetch](http://npm.im/npm-registry-fetch)
|
||||
- [minipass-json-stream](http://npm.im/minipass-json-stream)
|
||||
- [minipass-sized](http://npm.im/minipass-sized)
|
||||
|
||||
## Differences from Node.js Streams
|
||||
|
||||
There are several things that make Minipass streams different
|
||||
from (and in some ways superior to) Node.js core streams.
|
||||
|
||||
Please read these caveats if you are familiar with node-core
|
||||
streams and intend to use Minipass streams in your programs.
|
||||
|
||||
You can avoid most of these differences entirely (for a very
|
||||
small performance penalty) by setting `{async: true}` in the
|
||||
constructor options.
|
||||
|
||||
### Timing
|
||||
|
||||
Minipass streams are designed to support synchronous use-cases.
|
||||
Thus, data is emitted as soon as it is available, always. It is
|
||||
buffered until read, but no longer. Another way to look at it is
|
||||
that Minipass streams are exactly as synchronous as the logic
|
||||
that writes into them.
|
||||
|
||||
This can be surprising if your code relies on
|
||||
`PassThrough.write()` always providing data on the next tick
|
||||
rather than the current one, or being able to call `resume()` and
|
||||
not have the entire buffer disappear immediately.
|
||||
|
||||
However, without this synchronicity guarantee, there would be no
|
||||
way for Minipass to achieve the speeds it does, or support the
|
||||
synchronous use cases that it does. Simply put, waiting takes
|
||||
time.
|
||||
|
||||
This non-deferring approach makes Minipass streams much easier to
|
||||
reason about, especially in the context of Promises and other
|
||||
flow-control mechanisms.
|
||||
|
||||
Example:
|
||||
|
||||
```js
|
||||
// hybrid module, either works
|
||||
import { Minipass } from 'minipass'
|
||||
// or:
|
||||
const { Minipass } = require('minipass')
|
||||
|
||||
const stream = new Minipass()
|
||||
stream.on('data', () => console.log('data event'))
|
||||
console.log('before write')
|
||||
stream.write('hello')
|
||||
console.log('after write')
|
||||
// output:
|
||||
// before write
|
||||
// data event
|
||||
// after write
|
||||
```
|
||||
|
||||
### Exception: Async Opt-In
|
||||
|
||||
If you wish to have a Minipass stream with behavior that more
|
||||
closely mimics Node.js core streams, you can set the stream in
|
||||
async mode either by setting `async: true` in the constructor
|
||||
options, or by setting `stream.async = true` later on.
|
||||
|
||||
```js
|
||||
// hybrid module, either works
|
||||
import { Minipass } from 'minipass'
|
||||
// or:
|
||||
const { Minipass } = require('minipass')
|
||||
|
||||
const asyncStream = new Minipass({ async: true })
|
||||
asyncStream.on('data', () => console.log('data event'))
|
||||
console.log('before write')
|
||||
asyncStream.write('hello')
|
||||
console.log('after write')
|
||||
// output:
|
||||
// before write
|
||||
// after write
|
||||
// data event <-- this is deferred until the next tick
|
||||
```
|
||||
|
||||
Switching _out_ of async mode is unsafe, as it could cause data
|
||||
corruption, and so is not enabled. Example:
|
||||
|
||||
```js
|
||||
import { Minipass } from 'minipass'
|
||||
const stream = new Minipass({ encoding: 'utf8' })
|
||||
stream.on('data', chunk => console.log(chunk))
|
||||
stream.async = true
|
||||
console.log('before writes')
|
||||
stream.write('hello')
|
||||
setStreamSyncAgainSomehow(stream) // <-- this doesn't actually exist!
|
||||
stream.write('world')
|
||||
console.log('after writes')
|
||||
// hypothetical output would be:
|
||||
// before writes
|
||||
// world
|
||||
// after writes
|
||||
// hello
|
||||
// NOT GOOD!
|
||||
```
|
||||
|
||||
To avoid this problem, once set into async mode, any attempt to
|
||||
make the stream sync again will be ignored.
|
||||
|
||||
```js
|
||||
const { Minipass } = require('minipass')
|
||||
const stream = new Minipass({ encoding: 'utf8' })
|
||||
stream.on('data', chunk => console.log(chunk))
|
||||
stream.async = true
|
||||
console.log('before writes')
|
||||
stream.write('hello')
|
||||
stream.async = false // <-- no-op, stream already async
|
||||
stream.write('world')
|
||||
console.log('after writes')
|
||||
// actual output:
|
||||
// before writes
|
||||
// after writes
|
||||
// hello
|
||||
// world
|
||||
```
|
||||
|
||||
### No High/Low Water Marks
|
||||
|
||||
Node.js core streams will optimistically fill up a buffer,
|
||||
returning `true` on all writes until the limit is hit, even if
|
||||
the data has nowhere to go. Then, they will not attempt to draw
|
||||
more data in until the buffer size dips below a minimum value.
|
||||
|
||||
Minipass streams are much simpler. The `write()` method will
|
||||
return `true` if the data has somewhere to go (which is to say,
|
||||
given the timing guarantees, that the data is already there by
|
||||
the time `write()` returns).
|
||||
|
||||
If the data has nowhere to go, then `write()` returns false, and
|
||||
the data sits in a buffer, to be drained out immediately as soon
|
||||
as anyone consumes it.
|
||||
|
||||
Since nothing is ever buffered unnecessarily, there is much less
|
||||
copying data, and less bookkeeping about buffer capacity levels.
|
||||
|
||||
### Hazards of Buffering (or: Why Minipass Is So Fast)
|
||||
|
||||
Since data written to a Minipass stream is immediately written
|
||||
all the way through the pipeline, and `write()` always returns
|
||||
true/false based on whether the data was fully flushed,
|
||||
backpressure is communicated immediately to the upstream caller.
|
||||
This minimizes buffering.
|
||||
|
||||
Consider this case:
|
||||
|
||||
```js
|
||||
const { PassThrough } = require('stream')
|
||||
const p1 = new PassThrough({ highWaterMark: 1024 })
|
||||
const p2 = new PassThrough({ highWaterMark: 1024 })
|
||||
const p3 = new PassThrough({ highWaterMark: 1024 })
|
||||
const p4 = new PassThrough({ highWaterMark: 1024 })
|
||||
|
||||
p1.pipe(p2).pipe(p3).pipe(p4)
|
||||
p4.on('data', () => console.log('made it through'))
|
||||
|
||||
// this returns false and buffers, then writes to p2 on next tick (1)
|
||||
// p2 returns false and buffers, pausing p1, then writes to p3 on next tick (2)
|
||||
// p3 returns false and buffers, pausing p2, then writes to p4 on next tick (3)
|
||||
// p4 returns false and buffers, pausing p3, then emits 'data' and 'drain'
|
||||
// on next tick (4)
|
||||
// p3 sees p4's 'drain' event, and calls resume(), emitting 'resume' and
|
||||
// 'drain' on next tick (5)
|
||||
// p2 sees p3's 'drain', calls resume(), emits 'resume' and 'drain' on next tick (6)
|
||||
// p1 sees p2's 'drain', calls resume(), emits 'resume' and 'drain' on next
|
||||
// tick (7)
|
||||
|
||||
p1.write(Buffer.alloc(2048)) // returns false
|
||||
```
|
||||
|
||||
Along the way, the data was buffered and deferred at each stage,
|
||||
and multiple event deferrals happened, for an unblocked pipeline
|
||||
where it was perfectly safe to write all the way through!
|
||||
|
||||
Furthermore, setting a `highWaterMark` of `1024` might lead
|
||||
someone reading the code to think an advisory maximum of 1KiB is
|
||||
being set for the pipeline. However, the actual advisory
|
||||
buffering level is the _sum_ of `highWaterMark` values, since
|
||||
each one has its own bucket.
|
||||
|
||||
Consider the Minipass case:
|
||||
|
||||
```js
|
||||
const m1 = new Minipass()
|
||||
const m2 = new Minipass()
|
||||
const m3 = new Minipass()
|
||||
const m4 = new Minipass()
|
||||
|
||||
m1.pipe(m2).pipe(m3).pipe(m4)
|
||||
m4.on('data', () => console.log('made it through'))
|
||||
|
||||
// m1 is flowing, so it writes the data to m2 immediately
|
||||
// m2 is flowing, so it writes the data to m3 immediately
|
||||
// m3 is flowing, so it writes the data to m4 immediately
|
||||
// m4 is flowing, so it fires the 'data' event immediately, returns true
|
||||
// m4's write returned true, so m3 is still flowing, returns true
|
||||
// m3's write returned true, so m2 is still flowing, returns true
|
||||
// m2's write returned true, so m1 is still flowing, returns true
|
||||
// No event deferrals or buffering along the way!
|
||||
|
||||
m1.write(Buffer.alloc(2048)) // returns true
|
||||
```
|
||||
|
||||
It is extremely unlikely that you _don't_ want to buffer any data
|
||||
written, or _ever_ buffer data that can be flushed all the way
|
||||
through. Neither node-core streams nor Minipass ever fail to
|
||||
buffer written data, but node-core streams do a lot of
|
||||
unnecessary buffering and pausing.
|
||||
|
||||
As always, the faster implementation is the one that does less
|
||||
stuff and waits less time to do it.
|
||||
|
||||
### Immediately emit `end` for empty streams (when not paused)
|
||||
|
||||
If a stream is not paused, and `end()` is called before writing
|
||||
any data into it, then it will emit `end` immediately.
|
||||
|
||||
If you have logic that occurs on the `end` event which you don't
|
||||
want to potentially happen immediately (for example, closing file
|
||||
descriptors, moving on to the next entry in an archive parse
|
||||
stream, etc.) then be sure to call `stream.pause()` on creation,
|
||||
and then `stream.resume()` once you are ready to respond to the
|
||||
`end` event.
|
||||
|
||||
However, this is _usually_ not a problem because:
|
||||
|
||||
### Emit `end` When Asked
|
||||
|
||||
One hazard of immediately emitting `'end'` is that you may not
|
||||
yet have had a chance to add a listener. In order to avoid this
|
||||
hazard, Minipass streams safely re-emit the `'end'` event if a
|
||||
new listener is added after `'end'` has been emitted.
|
||||
|
||||
Ie, if you do `stream.on('end', someFunction)`, and the stream
|
||||
has already emitted `end`, then it will call the handler right
|
||||
away. (You can think of this somewhat like attaching a new
|
||||
`.then(fn)` to a previously-resolved Promise.)
|
||||
|
||||
To prevent calling handlers multiple times who would not expect
|
||||
multiple ends to occur, all listeners are removed from the
|
||||
`'end'` event whenever it is emitted.
|
||||
|
||||
### Emit `error` When Asked
|
||||
|
||||
The most recent error object passed to the `'error'` event is
|
||||
stored on the stream. If a new `'error'` event handler is added,
|
||||
and an error was previously emitted, then the event handler will
|
||||
be called immediately (or on `process.nextTick` in the case of
|
||||
async streams).
|
||||
|
||||
This makes it much more difficult to end up trying to interact
|
||||
with a broken stream, if the error handler is added after an
|
||||
error was previously emitted.
|
||||
|
||||
### Impact of "immediate flow" on Tee-streams
|
||||
|
||||
A "tee stream" is a stream piping to multiple destinations:
|
||||
|
||||
```js
|
||||
const tee = new Minipass()
|
||||
t.pipe(dest1)
|
||||
t.pipe(dest2)
|
||||
t.write('foo') // goes to both destinations
|
||||
```
|
||||
|
||||
Since Minipass streams _immediately_ process any pending data
|
||||
through the pipeline when a new pipe destination is added, this
|
||||
can have surprising effects, especially when a stream comes in
|
||||
from some other function and may or may not have data in its
|
||||
buffer.
|
||||
|
||||
```js
|
||||
// WARNING! WILL LOSE DATA!
|
||||
const src = new Minipass()
|
||||
src.write('foo')
|
||||
src.pipe(dest1) // 'foo' chunk flows to dest1 immediately, and is gone
|
||||
src.pipe(dest2) // gets nothing!
|
||||
```
|
||||
|
||||
One solution is to create a dedicated tee-stream junction that
|
||||
pipes to both locations, and then pipe to _that_ instead.
|
||||
|
||||
```js
|
||||
// Safe example: tee to both places
|
||||
const src = new Minipass()
|
||||
src.write('foo')
|
||||
const tee = new Minipass()
|
||||
tee.pipe(dest1)
|
||||
tee.pipe(dest2)
|
||||
src.pipe(tee) // tee gets 'foo', pipes to both locations
|
||||
```
|
||||
|
||||
The same caveat applies to `on('data')` event listeners. The
|
||||
first one added will _immediately_ receive all of the data,
|
||||
leaving nothing for the second:
|
||||
|
||||
```js
|
||||
// WARNING! WILL LOSE DATA!
|
||||
const src = new Minipass()
|
||||
src.write('foo')
|
||||
src.on('data', handler1) // receives 'foo' right away
|
||||
src.on('data', handler2) // nothing to see here!
|
||||
```
|
||||
|
||||
Using a dedicated tee-stream can be used in this case as well:
|
||||
|
||||
```js
|
||||
// Safe example: tee to both data handlers
|
||||
const src = new Minipass()
|
||||
src.write('foo')
|
||||
const tee = new Minipass()
|
||||
tee.on('data', handler1)
|
||||
tee.on('data', handler2)
|
||||
src.pipe(tee)
|
||||
```
|
||||
|
||||
All of the hazards in this section are avoided by setting `{
|
||||
async: true }` in the Minipass constructor, or by setting
|
||||
`stream.async = true` afterwards. Note that this does add some
|
||||
overhead, so should only be done in cases where you are willing
|
||||
to lose a bit of performance in order to avoid having to refactor
|
||||
program logic.
|
||||
|
||||
## USAGE
|
||||
|
||||
It's a stream! Use it like a stream and it'll most likely do what
|
||||
you want.
|
||||
|
||||
```js
|
||||
import { Minipass } from 'minipass'
|
||||
const mp = new Minipass(options) // optional: { encoding, objectMode }
|
||||
mp.write('foo')
|
||||
mp.pipe(someOtherStream)
|
||||
mp.end('bar')
|
||||
```
|
||||
|
||||
### OPTIONS
|
||||
|
||||
- `encoding` How would you like the data coming _out_ of the
|
||||
stream to be encoded? Accepts any values that can be passed to
|
||||
`Buffer.toString()`.
|
||||
- `objectMode` Emit data exactly as it comes in. This will be
|
||||
flipped on by default if you write() something other than a
|
||||
string or Buffer at any point. Setting `objectMode: true` will
|
||||
prevent setting any encoding value.
|
||||
- `async` Defaults to `false`. Set to `true` to defer data
|
||||
emission until next tick. This reduces performance slightly,
|
||||
but makes Minipass streams use timing behavior closer to Node
|
||||
core streams. See [Timing](#timing) for more details.
|
||||
- `signal` An `AbortSignal` that will cause the stream to unhook
|
||||
itself from everything and become as inert as possible. Note
|
||||
that providing a `signal` parameter will make `'error'` events
|
||||
no longer throw if they are unhandled, but they will still be
|
||||
emitted to handlers if any are attached.
|
||||
|
||||
### API
|
||||
|
||||
Implements the user-facing portions of Node.js's `Readable` and
|
||||
`Writable` streams.
|
||||
|
||||
### Methods
|
||||
|
||||
- `write(chunk, [encoding], [callback])` - Put data in. (Note
|
||||
that, in the base Minipass class, the same data will come out.)
|
||||
Returns `false` if the stream will buffer the next write, or
|
||||
true if it's still in "flowing" mode.
|
||||
- `end([chunk, [encoding]], [callback])` - Signal that you have
|
||||
no more data to write. This will queue an `end` event to be
|
||||
fired when all the data has been consumed.
|
||||
- `setEncoding(encoding)` - Set the encoding for data coming of
|
||||
the stream. This can only be done once.
|
||||
- `pause()` - No more data for a while, please. This also
|
||||
prevents `end` from being emitted for empty streams until the
|
||||
stream is resumed.
|
||||
- `resume()` - Resume the stream. If there's data in the buffer,
|
||||
it is all discarded. Any buffered events are immediately
|
||||
emitted.
|
||||
- `pipe(dest)` - Send all output to the stream provided. When
|
||||
data is emitted, it is immediately written to any and all pipe
|
||||
destinations. (Or written on next tick in `async` mode.)
|
||||
- `unpipe(dest)` - Stop piping to the destination stream. This is
|
||||
immediate, meaning that any asynchronously queued data will
|
||||
_not_ make it to the destination when running in `async` mode.
|
||||
- `options.end` - Boolean, end the destination stream when the
|
||||
source stream ends. Default `true`.
|
||||
- `options.proxyErrors` - Boolean, proxy `error` events from
|
||||
the source stream to the destination stream. Note that errors
|
||||
are _not_ proxied after the pipeline terminates, either due
|
||||
to the source emitting `'end'` or manually unpiping with
|
||||
`src.unpipe(dest)`. Default `false`.
|
||||
- `on(ev, fn)`, `emit(ev, fn)` - Minipass streams are
|
||||
EventEmitters. Some events are given special treatment,
|
||||
however. (See below under "events".)
|
||||
- `promise()` - Returns a Promise that resolves when the stream
|
||||
emits `end`, or rejects if the stream emits `error`.
|
||||
- `collect()` - Return a Promise that resolves on `end` with an
|
||||
array containing each chunk of data that was emitted, or
|
||||
rejects if the stream emits `error`. Note that this consumes
|
||||
the stream data.
|
||||
- `concat()` - Same as `collect()`, but concatenates the data
|
||||
into a single Buffer object. Will reject the returned promise
|
||||
if the stream is in objectMode, or if it goes into objectMode
|
||||
by the end of the data.
|
||||
- `read(n)` - Consume `n` bytes of data out of the buffer. If `n`
|
||||
is not provided, then consume all of it. If `n` bytes are not
|
||||
available, then it returns null. **Note** consuming streams in
|
||||
this way is less efficient, and can lead to unnecessary Buffer
|
||||
copying.
|
||||
- `destroy([er])` - Destroy the stream. If an error is provided,
|
||||
then an `'error'` event is emitted. If the stream has a
|
||||
`close()` method, and has not emitted a `'close'` event yet,
|
||||
then `stream.close()` will be called. Any Promises returned by
|
||||
`.promise()`, `.collect()` or `.concat()` will be rejected.
|
||||
After being destroyed, writing to the stream will emit an
|
||||
error. No more data will be emitted if the stream is destroyed,
|
||||
even if it was previously buffered.
|
||||
|
||||
### Properties
|
||||
|
||||
- `bufferLength` Read-only. Total number of bytes buffered, or in
|
||||
the case of objectMode, the total number of objects.
|
||||
- `encoding` The encoding that has been set. (Setting this is
|
||||
equivalent to calling `setEncoding(enc)` and has the same
|
||||
prohibition against setting multiple times.)
|
||||
- `flowing` Read-only. Boolean indicating whether a chunk written
|
||||
to the stream will be immediately emitted.
|
||||
- `emittedEnd` Read-only. Boolean indicating whether the end-ish
|
||||
events (ie, `end`, `prefinish`, `finish`) have been emitted.
|
||||
Note that listening on any end-ish event will immediateyl
|
||||
re-emit it if it has already been emitted.
|
||||
- `writable` Whether the stream is writable. Default `true`. Set
|
||||
to `false` when `end()`
|
||||
- `readable` Whether the stream is readable. Default `true`.
|
||||
- `pipes` An array of Pipe objects referencing streams that this
|
||||
stream is piping into.
|
||||
- `destroyed` A getter that indicates whether the stream was
|
||||
destroyed.
|
||||
- `paused` True if the stream has been explicitly paused,
|
||||
otherwise false.
|
||||
- `objectMode` Indicates whether the stream is in `objectMode`.
|
||||
Once set to `true`, it cannot be set to `false`.
|
||||
- `aborted` Readonly property set when the `AbortSignal`
|
||||
dispatches an `abort` event.
|
||||
|
||||
### Events
|
||||
|
||||
- `data` Emitted when there's data to read. Argument is the data
|
||||
to read. This is never emitted while not flowing. If a listener
|
||||
is attached, that will resume the stream.
|
||||
- `end` Emitted when there's no more data to read. This will be
|
||||
emitted immediately for empty streams when `end()` is called.
|
||||
If a listener is attached, and `end` was already emitted, then
|
||||
it will be emitted again. All listeners are removed when `end`
|
||||
is emitted.
|
||||
- `prefinish` An end-ish event that follows the same logic as
|
||||
`end` and is emitted in the same conditions where `end` is
|
||||
emitted. Emitted after `'end'`.
|
||||
- `finish` An end-ish event that follows the same logic as `end`
|
||||
and is emitted in the same conditions where `end` is emitted.
|
||||
Emitted after `'prefinish'`.
|
||||
- `close` An indication that an underlying resource has been
|
||||
released. Minipass does not emit this event, but will defer it
|
||||
until after `end` has been emitted, since it throws off some
|
||||
stream libraries otherwise.
|
||||
- `drain` Emitted when the internal buffer empties, and it is
|
||||
again suitable to `write()` into the stream.
|
||||
- `readable` Emitted when data is buffered and ready to be read
|
||||
by a consumer.
|
||||
- `resume` Emitted when stream changes state from buffering to
|
||||
flowing mode. (Ie, when `resume` is called, `pipe` is called,
|
||||
or a `data` event listener is added.)
|
||||
|
||||
### Static Methods
|
||||
|
||||
- `Minipass.isStream(stream)` Returns `true` if the argument is a
|
||||
stream, and false otherwise. To be considered a stream, the
|
||||
object must be either an instance of Minipass, or an
|
||||
EventEmitter that has either a `pipe()` method, or both
|
||||
`write()` and `end()` methods. (Pretty much any stream in
|
||||
node-land will return `true` for this.)
|
||||
|
||||
## EXAMPLES
|
||||
|
||||
Here are some examples of things you can do with Minipass
|
||||
streams.
|
||||
|
||||
### simple "are you done yet" promise
|
||||
|
||||
```js
|
||||
mp.promise().then(
|
||||
() => {
|
||||
// stream is finished
|
||||
},
|
||||
er => {
|
||||
// stream emitted an error
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
### collecting
|
||||
|
||||
```js
|
||||
mp.collect().then(all => {
|
||||
// all is an array of all the data emitted
|
||||
// encoding is supported in this case, so
|
||||
// so the result will be a collection of strings if
|
||||
// an encoding is specified, or buffers/objects if not.
|
||||
//
|
||||
// In an async function, you may do
|
||||
// const data = await stream.collect()
|
||||
})
|
||||
```
|
||||
|
||||
### collecting into a single blob
|
||||
|
||||
This is a bit slower because it concatenates the data into one
|
||||
chunk for you, but if you're going to do it yourself anyway, it's
|
||||
convenient this way:
|
||||
|
||||
```js
|
||||
mp.concat().then(onebigchunk => {
|
||||
// onebigchunk is a string if the stream
|
||||
// had an encoding set, or a buffer otherwise.
|
||||
})
|
||||
```
|
||||
|
||||
### iteration
|
||||
|
||||
You can iterate over streams synchronously or asynchronously in
|
||||
platforms that support it.
|
||||
|
||||
Synchronous iteration will end when the currently available data
|
||||
is consumed, even if the `end` event has not been reached. In
|
||||
string and buffer mode, the data is concatenated, so unless
|
||||
multiple writes are occurring in the same tick as the `read()`,
|
||||
sync iteration loops will generally only have a single iteration.
|
||||
|
||||
To consume chunks in this way exactly as they have been written,
|
||||
with no flattening, create the stream with the `{ objectMode:
|
||||
true }` option.
|
||||
|
||||
```js
|
||||
const mp = new Minipass({ objectMode: true })
|
||||
mp.write('a')
|
||||
mp.write('b')
|
||||
for (let letter of mp) {
|
||||
console.log(letter) // a, b
|
||||
}
|
||||
mp.write('c')
|
||||
mp.write('d')
|
||||
for (let letter of mp) {
|
||||
console.log(letter) // c, d
|
||||
}
|
||||
mp.write('e')
|
||||
mp.end()
|
||||
for (let letter of mp) {
|
||||
console.log(letter) // e
|
||||
}
|
||||
for (let letter of mp) {
|
||||
console.log(letter) // nothing
|
||||
}
|
||||
```
|
||||
|
||||
Asynchronous iteration will continue until the end event is reached,
|
||||
consuming all of the data.
|
||||
|
||||
```js
|
||||
const mp = new Minipass({ encoding: 'utf8' })
|
||||
|
||||
// some source of some data
|
||||
let i = 5
|
||||
const inter = setInterval(() => {
|
||||
if (i-- > 0) mp.write(Buffer.from('foo\n', 'utf8'))
|
||||
else {
|
||||
mp.end()
|
||||
clearInterval(inter)
|
||||
}
|
||||
}, 100)
|
||||
|
||||
// consume the data with asynchronous iteration
|
||||
async function consume() {
|
||||
for await (let chunk of mp) {
|
||||
console.log(chunk)
|
||||
}
|
||||
return 'ok'
|
||||
}
|
||||
|
||||
consume().then(res => console.log(res))
|
||||
// logs `foo\n` 5 times, and then `ok`
|
||||
```
|
||||
|
||||
### subclass that `console.log()`s everything written into it
|
||||
|
||||
```js
|
||||
class Logger extends Minipass {
|
||||
write(chunk, encoding, callback) {
|
||||
console.log('WRITE', chunk, encoding)
|
||||
return super.write(chunk, encoding, callback)
|
||||
}
|
||||
end(chunk, encoding, callback) {
|
||||
console.log('END', chunk, encoding)
|
||||
return super.end(chunk, encoding, callback)
|
||||
}
|
||||
}
|
||||
|
||||
someSource.pipe(new Logger()).pipe(someDest)
|
||||
```
|
||||
|
||||
### same thing, but using an inline anonymous class
|
||||
|
||||
```js
|
||||
// js classes are fun
|
||||
someSource
|
||||
.pipe(
|
||||
new (class extends Minipass {
|
||||
emit(ev, ...data) {
|
||||
// let's also log events, because debugging some weird thing
|
||||
console.log('EMIT', ev)
|
||||
return super.emit(ev, ...data)
|
||||
}
|
||||
write(chunk, encoding, callback) {
|
||||
console.log('WRITE', chunk, encoding)
|
||||
return super.write(chunk, encoding, callback)
|
||||
}
|
||||
end(chunk, encoding, callback) {
|
||||
console.log('END', chunk, encoding)
|
||||
return super.end(chunk, encoding, callback)
|
||||
}
|
||||
})()
|
||||
)
|
||||
.pipe(someDest)
|
||||
```
|
||||
|
||||
### subclass that defers 'end' for some reason
|
||||
|
||||
```js
|
||||
class SlowEnd extends Minipass {
|
||||
emit(ev, ...args) {
|
||||
if (ev === 'end') {
|
||||
console.log('going to end, hold on a sec')
|
||||
setTimeout(() => {
|
||||
console.log('ok, ready to end now')
|
||||
super.emit('end', ...args)
|
||||
}, 100)
|
||||
} else {
|
||||
return super.emit(ev, ...args)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### transform that creates newline-delimited JSON
|
||||
|
||||
```js
|
||||
class NDJSONEncode extends Minipass {
|
||||
write(obj, cb) {
|
||||
try {
|
||||
// JSON.stringify can throw, emit an error on that
|
||||
return super.write(JSON.stringify(obj) + '\n', 'utf8', cb)
|
||||
} catch (er) {
|
||||
this.emit('error', er)
|
||||
}
|
||||
}
|
||||
end(obj, cb) {
|
||||
if (typeof obj === 'function') {
|
||||
cb = obj
|
||||
obj = undefined
|
||||
}
|
||||
if (obj !== undefined) {
|
||||
this.write(obj)
|
||||
}
|
||||
return super.end(cb)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### transform that parses newline-delimited JSON
|
||||
|
||||
```js
|
||||
class NDJSONDecode extends Minipass {
|
||||
constructor (options) {
|
||||
// always be in object mode, as far as Minipass is concerned
|
||||
super({ objectMode: true })
|
||||
this._jsonBuffer = ''
|
||||
}
|
||||
write (chunk, encoding, cb) {
|
||||
if (typeof chunk === 'string' &&
|
||||
typeof encoding === 'string' &&
|
||||
encoding !== 'utf8') {
|
||||
chunk = Buffer.from(chunk, encoding).toString()
|
||||
} else if (Buffer.isBuffer(chunk)) {
|
||||
chunk = chunk.toString()
|
||||
}
|
||||
if (typeof encoding === 'function') {
|
||||
cb = encoding
|
||||
}
|
||||
const jsonData = (this._jsonBuffer + chunk).split('\n')
|
||||
this._jsonBuffer = jsonData.pop()
|
||||
for (let i = 0; i < jsonData.length; i++) {
|
||||
try {
|
||||
// JSON.parse can throw, emit an error on that
|
||||
super.write(JSON.parse(jsonData[i]))
|
||||
} catch (er) {
|
||||
this.emit('error', er)
|
||||
continue
|
||||
}
|
||||
}
|
||||
if (cb)
|
||||
cb()
|
||||
}
|
||||
}
|
||||
```
|
||||
152
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/index.d.ts
generated
vendored
Normal file
152
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/index.d.ts
generated
vendored
Normal file
|
|
@ -0,0 +1,152 @@
|
|||
/// <reference types="node" />
|
||||
|
||||
// Note: marking anything protected or private in the exported
|
||||
// class will limit Minipass's ability to be used as the base
|
||||
// for mixin classes.
|
||||
import { EventEmitter } from 'events'
|
||||
import { Stream } from 'stream'
|
||||
|
||||
export namespace Minipass {
|
||||
export type Encoding = BufferEncoding | 'buffer' | null
|
||||
|
||||
export interface Writable extends EventEmitter {
|
||||
end(): any
|
||||
write(chunk: any, ...args: any[]): any
|
||||
}
|
||||
|
||||
export interface Readable extends EventEmitter {
|
||||
pause(): any
|
||||
resume(): any
|
||||
pipe(): any
|
||||
}
|
||||
|
||||
export type DualIterable<T> = Iterable<T> & AsyncIterable<T>
|
||||
|
||||
export type ContiguousData =
|
||||
| Buffer
|
||||
| ArrayBufferLike
|
||||
| ArrayBufferView
|
||||
| string
|
||||
|
||||
export type BufferOrString = Buffer | string
|
||||
|
||||
export interface SharedOptions {
|
||||
async?: boolean
|
||||
signal?: AbortSignal
|
||||
}
|
||||
|
||||
export interface StringOptions extends SharedOptions {
|
||||
encoding: BufferEncoding
|
||||
objectMode?: boolean
|
||||
}
|
||||
|
||||
export interface BufferOptions extends SharedOptions {
|
||||
encoding?: null | 'buffer'
|
||||
objectMode?: boolean
|
||||
}
|
||||
|
||||
export interface ObjectModeOptions extends SharedOptions {
|
||||
objectMode: true
|
||||
}
|
||||
|
||||
export interface PipeOptions {
|
||||
end?: boolean
|
||||
proxyErrors?: boolean
|
||||
}
|
||||
|
||||
export type Options<T> = T extends string
|
||||
? StringOptions
|
||||
: T extends Buffer
|
||||
? BufferOptions
|
||||
: ObjectModeOptions
|
||||
}
|
||||
|
||||
export class Minipass<
|
||||
RType extends any = Buffer,
|
||||
WType extends any = RType extends Minipass.BufferOrString
|
||||
? Minipass.ContiguousData
|
||||
: RType
|
||||
>
|
||||
extends Stream
|
||||
implements Minipass.DualIterable<RType>
|
||||
{
|
||||
static isStream(stream: any): stream is Minipass.Readable | Minipass.Writable
|
||||
|
||||
readonly bufferLength: number
|
||||
readonly flowing: boolean
|
||||
readonly writable: boolean
|
||||
readonly readable: boolean
|
||||
readonly aborted: boolean
|
||||
readonly paused: boolean
|
||||
readonly emittedEnd: boolean
|
||||
readonly destroyed: boolean
|
||||
|
||||
/**
|
||||
* Technically writable, but mutating it can change the type,
|
||||
* so is not safe to do in TypeScript.
|
||||
*/
|
||||
readonly objectMode: boolean
|
||||
async: boolean
|
||||
|
||||
/**
|
||||
* Note: encoding is not actually read-only, and setEncoding(enc)
|
||||
* exists. However, this type definition will insist that TypeScript
|
||||
* programs declare the type of a Minipass stream up front, and if
|
||||
* that type is string, then an encoding MUST be set in the ctor. If
|
||||
* the type is Buffer, then the encoding must be missing, or set to
|
||||
* 'buffer' or null. If the type is anything else, then objectMode
|
||||
* must be set in the constructor options. So there is effectively
|
||||
* no allowed way that a TS program can set the encoding after
|
||||
* construction, as doing so will destroy any hope of type safety.
|
||||
* TypeScript does not provide many options for changing the type of
|
||||
* an object at run-time, which is what changing the encoding does.
|
||||
*/
|
||||
readonly encoding: Minipass.Encoding
|
||||
// setEncoding(encoding: Encoding): void
|
||||
|
||||
// Options required if not reading buffers
|
||||
constructor(
|
||||
...args: RType extends Buffer
|
||||
? [] | [Minipass.Options<RType>]
|
||||
: [Minipass.Options<RType>]
|
||||
)
|
||||
|
||||
write(chunk: WType, cb?: () => void): boolean
|
||||
write(chunk: WType, encoding?: Minipass.Encoding, cb?: () => void): boolean
|
||||
read(size?: number): RType
|
||||
end(cb?: () => void): this
|
||||
end(chunk: any, cb?: () => void): this
|
||||
end(chunk: any, encoding?: Minipass.Encoding, cb?: () => void): this
|
||||
pause(): void
|
||||
resume(): void
|
||||
promise(): Promise<void>
|
||||
collect(): Promise<RType[]>
|
||||
|
||||
concat(): RType extends Minipass.BufferOrString ? Promise<RType> : never
|
||||
destroy(er?: any): void
|
||||
pipe<W extends Minipass.Writable>(dest: W, opts?: Minipass.PipeOptions): W
|
||||
unpipe<W extends Minipass.Writable>(dest: W): void
|
||||
|
||||
/**
|
||||
* alias for on()
|
||||
*/
|
||||
addEventHandler(event: string, listener: (...args: any[]) => any): this
|
||||
|
||||
on(event: string, listener: (...args: any[]) => any): this
|
||||
on(event: 'data', listener: (chunk: RType) => any): this
|
||||
on(event: 'error', listener: (error: any) => any): this
|
||||
on(
|
||||
event:
|
||||
| 'readable'
|
||||
| 'drain'
|
||||
| 'resume'
|
||||
| 'end'
|
||||
| 'prefinish'
|
||||
| 'finish'
|
||||
| 'close',
|
||||
listener: () => any
|
||||
): this
|
||||
|
||||
[Symbol.iterator](): Generator<RType, void, void>
|
||||
[Symbol.asyncIterator](): AsyncGenerator<RType, void, void>
|
||||
}
|
||||
702
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/index.js
generated
vendored
Normal file
702
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/index.js
generated
vendored
Normal file
|
|
@ -0,0 +1,702 @@
|
|||
'use strict'
|
||||
const proc =
|
||||
typeof process === 'object' && process
|
||||
? process
|
||||
: {
|
||||
stdout: null,
|
||||
stderr: null,
|
||||
}
|
||||
const EE = require('events')
|
||||
const Stream = require('stream')
|
||||
const stringdecoder = require('string_decoder')
|
||||
const SD = stringdecoder.StringDecoder
|
||||
|
||||
const EOF = Symbol('EOF')
|
||||
const MAYBE_EMIT_END = Symbol('maybeEmitEnd')
|
||||
const EMITTED_END = Symbol('emittedEnd')
|
||||
const EMITTING_END = Symbol('emittingEnd')
|
||||
const EMITTED_ERROR = Symbol('emittedError')
|
||||
const CLOSED = Symbol('closed')
|
||||
const READ = Symbol('read')
|
||||
const FLUSH = Symbol('flush')
|
||||
const FLUSHCHUNK = Symbol('flushChunk')
|
||||
const ENCODING = Symbol('encoding')
|
||||
const DECODER = Symbol('decoder')
|
||||
const FLOWING = Symbol('flowing')
|
||||
const PAUSED = Symbol('paused')
|
||||
const RESUME = Symbol('resume')
|
||||
const BUFFER = Symbol('buffer')
|
||||
const PIPES = Symbol('pipes')
|
||||
const BUFFERLENGTH = Symbol('bufferLength')
|
||||
const BUFFERPUSH = Symbol('bufferPush')
|
||||
const BUFFERSHIFT = Symbol('bufferShift')
|
||||
const OBJECTMODE = Symbol('objectMode')
|
||||
// internal event when stream is destroyed
|
||||
const DESTROYED = Symbol('destroyed')
|
||||
// internal event when stream has an error
|
||||
const ERROR = Symbol('error')
|
||||
const EMITDATA = Symbol('emitData')
|
||||
const EMITEND = Symbol('emitEnd')
|
||||
const EMITEND2 = Symbol('emitEnd2')
|
||||
const ASYNC = Symbol('async')
|
||||
const ABORT = Symbol('abort')
|
||||
const ABORTED = Symbol('aborted')
|
||||
const SIGNAL = Symbol('signal')
|
||||
|
||||
const defer = fn => Promise.resolve().then(fn)
|
||||
|
||||
// TODO remove when Node v8 support drops
|
||||
const doIter = global._MP_NO_ITERATOR_SYMBOLS_ !== '1'
|
||||
const ASYNCITERATOR =
|
||||
(doIter && Symbol.asyncIterator) || Symbol('asyncIterator not implemented')
|
||||
const ITERATOR =
|
||||
(doIter && Symbol.iterator) || Symbol('iterator not implemented')
|
||||
|
||||
// events that mean 'the stream is over'
|
||||
// these are treated specially, and re-emitted
|
||||
// if they are listened for after emitting.
|
||||
const isEndish = ev => ev === 'end' || ev === 'finish' || ev === 'prefinish'
|
||||
|
||||
const isArrayBuffer = b =>
|
||||
b instanceof ArrayBuffer ||
|
||||
(typeof b === 'object' &&
|
||||
b.constructor &&
|
||||
b.constructor.name === 'ArrayBuffer' &&
|
||||
b.byteLength >= 0)
|
||||
|
||||
const isArrayBufferView = b => !Buffer.isBuffer(b) && ArrayBuffer.isView(b)
|
||||
|
||||
class Pipe {
|
||||
constructor(src, dest, opts) {
|
||||
this.src = src
|
||||
this.dest = dest
|
||||
this.opts = opts
|
||||
this.ondrain = () => src[RESUME]()
|
||||
dest.on('drain', this.ondrain)
|
||||
}
|
||||
unpipe() {
|
||||
this.dest.removeListener('drain', this.ondrain)
|
||||
}
|
||||
// istanbul ignore next - only here for the prototype
|
||||
proxyErrors() {}
|
||||
end() {
|
||||
this.unpipe()
|
||||
if (this.opts.end) this.dest.end()
|
||||
}
|
||||
}
|
||||
|
||||
class PipeProxyErrors extends Pipe {
|
||||
unpipe() {
|
||||
this.src.removeListener('error', this.proxyErrors)
|
||||
super.unpipe()
|
||||
}
|
||||
constructor(src, dest, opts) {
|
||||
super(src, dest, opts)
|
||||
this.proxyErrors = er => dest.emit('error', er)
|
||||
src.on('error', this.proxyErrors)
|
||||
}
|
||||
}
|
||||
|
||||
class Minipass extends Stream {
|
||||
constructor(options) {
|
||||
super()
|
||||
this[FLOWING] = false
|
||||
// whether we're explicitly paused
|
||||
this[PAUSED] = false
|
||||
this[PIPES] = []
|
||||
this[BUFFER] = []
|
||||
this[OBJECTMODE] = (options && options.objectMode) || false
|
||||
if (this[OBJECTMODE]) this[ENCODING] = null
|
||||
else this[ENCODING] = (options && options.encoding) || null
|
||||
if (this[ENCODING] === 'buffer') this[ENCODING] = null
|
||||
this[ASYNC] = (options && !!options.async) || false
|
||||
this[DECODER] = this[ENCODING] ? new SD(this[ENCODING]) : null
|
||||
this[EOF] = false
|
||||
this[EMITTED_END] = false
|
||||
this[EMITTING_END] = false
|
||||
this[CLOSED] = false
|
||||
this[EMITTED_ERROR] = null
|
||||
this.writable = true
|
||||
this.readable = true
|
||||
this[BUFFERLENGTH] = 0
|
||||
this[DESTROYED] = false
|
||||
if (options && options.debugExposeBuffer === true) {
|
||||
Object.defineProperty(this, 'buffer', { get: () => this[BUFFER] })
|
||||
}
|
||||
if (options && options.debugExposePipes === true) {
|
||||
Object.defineProperty(this, 'pipes', { get: () => this[PIPES] })
|
||||
}
|
||||
this[SIGNAL] = options && options.signal
|
||||
this[ABORTED] = false
|
||||
if (this[SIGNAL]) {
|
||||
this[SIGNAL].addEventListener('abort', () => this[ABORT]())
|
||||
if (this[SIGNAL].aborted) {
|
||||
this[ABORT]()
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
get bufferLength() {
|
||||
return this[BUFFERLENGTH]
|
||||
}
|
||||
|
||||
get encoding() {
|
||||
return this[ENCODING]
|
||||
}
|
||||
set encoding(enc) {
|
||||
if (this[OBJECTMODE]) throw new Error('cannot set encoding in objectMode')
|
||||
|
||||
if (
|
||||
this[ENCODING] &&
|
||||
enc !== this[ENCODING] &&
|
||||
((this[DECODER] && this[DECODER].lastNeed) || this[BUFFERLENGTH])
|
||||
)
|
||||
throw new Error('cannot change encoding')
|
||||
|
||||
if (this[ENCODING] !== enc) {
|
||||
this[DECODER] = enc ? new SD(enc) : null
|
||||
if (this[BUFFER].length)
|
||||
this[BUFFER] = this[BUFFER].map(chunk => this[DECODER].write(chunk))
|
||||
}
|
||||
|
||||
this[ENCODING] = enc
|
||||
}
|
||||
|
||||
setEncoding(enc) {
|
||||
this.encoding = enc
|
||||
}
|
||||
|
||||
get objectMode() {
|
||||
return this[OBJECTMODE]
|
||||
}
|
||||
set objectMode(om) {
|
||||
this[OBJECTMODE] = this[OBJECTMODE] || !!om
|
||||
}
|
||||
|
||||
get ['async']() {
|
||||
return this[ASYNC]
|
||||
}
|
||||
set ['async'](a) {
|
||||
this[ASYNC] = this[ASYNC] || !!a
|
||||
}
|
||||
|
||||
// drop everything and get out of the flow completely
|
||||
[ABORT]() {
|
||||
this[ABORTED] = true
|
||||
this.emit('abort', this[SIGNAL].reason)
|
||||
this.destroy(this[SIGNAL].reason)
|
||||
}
|
||||
|
||||
get aborted() {
|
||||
return this[ABORTED]
|
||||
}
|
||||
set aborted(_) {}
|
||||
|
||||
write(chunk, encoding, cb) {
|
||||
if (this[ABORTED]) return false
|
||||
if (this[EOF]) throw new Error('write after end')
|
||||
|
||||
if (this[DESTROYED]) {
|
||||
this.emit(
|
||||
'error',
|
||||
Object.assign(
|
||||
new Error('Cannot call write after a stream was destroyed'),
|
||||
{ code: 'ERR_STREAM_DESTROYED' }
|
||||
)
|
||||
)
|
||||
return true
|
||||
}
|
||||
|
||||
if (typeof encoding === 'function') (cb = encoding), (encoding = 'utf8')
|
||||
|
||||
if (!encoding) encoding = 'utf8'
|
||||
|
||||
const fn = this[ASYNC] ? defer : f => f()
|
||||
|
||||
// convert array buffers and typed array views into buffers
|
||||
// at some point in the future, we may want to do the opposite!
|
||||
// leave strings and buffers as-is
|
||||
// anything else switches us into object mode
|
||||
if (!this[OBJECTMODE] && !Buffer.isBuffer(chunk)) {
|
||||
if (isArrayBufferView(chunk))
|
||||
chunk = Buffer.from(chunk.buffer, chunk.byteOffset, chunk.byteLength)
|
||||
else if (isArrayBuffer(chunk)) chunk = Buffer.from(chunk)
|
||||
else if (typeof chunk !== 'string')
|
||||
// use the setter so we throw if we have encoding set
|
||||
this.objectMode = true
|
||||
}
|
||||
|
||||
// handle object mode up front, since it's simpler
|
||||
// this yields better performance, fewer checks later.
|
||||
if (this[OBJECTMODE]) {
|
||||
/* istanbul ignore if - maybe impossible? */
|
||||
if (this.flowing && this[BUFFERLENGTH] !== 0) this[FLUSH](true)
|
||||
|
||||
if (this.flowing) this.emit('data', chunk)
|
||||
else this[BUFFERPUSH](chunk)
|
||||
|
||||
if (this[BUFFERLENGTH] !== 0) this.emit('readable')
|
||||
|
||||
if (cb) fn(cb)
|
||||
|
||||
return this.flowing
|
||||
}
|
||||
|
||||
// at this point the chunk is a buffer or string
|
||||
// don't buffer it up or send it to the decoder
|
||||
if (!chunk.length) {
|
||||
if (this[BUFFERLENGTH] !== 0) this.emit('readable')
|
||||
if (cb) fn(cb)
|
||||
return this.flowing
|
||||
}
|
||||
|
||||
// fast-path writing strings of same encoding to a stream with
|
||||
// an empty buffer, skipping the buffer/decoder dance
|
||||
if (
|
||||
typeof chunk === 'string' &&
|
||||
// unless it is a string already ready for us to use
|
||||
!(encoding === this[ENCODING] && !this[DECODER].lastNeed)
|
||||
) {
|
||||
chunk = Buffer.from(chunk, encoding)
|
||||
}
|
||||
|
||||
if (Buffer.isBuffer(chunk) && this[ENCODING])
|
||||
chunk = this[DECODER].write(chunk)
|
||||
|
||||
// Note: flushing CAN potentially switch us into not-flowing mode
|
||||
if (this.flowing && this[BUFFERLENGTH] !== 0) this[FLUSH](true)
|
||||
|
||||
if (this.flowing) this.emit('data', chunk)
|
||||
else this[BUFFERPUSH](chunk)
|
||||
|
||||
if (this[BUFFERLENGTH] !== 0) this.emit('readable')
|
||||
|
||||
if (cb) fn(cb)
|
||||
|
||||
return this.flowing
|
||||
}
|
||||
|
||||
read(n) {
|
||||
if (this[DESTROYED]) return null
|
||||
|
||||
if (this[BUFFERLENGTH] === 0 || n === 0 || n > this[BUFFERLENGTH]) {
|
||||
this[MAYBE_EMIT_END]()
|
||||
return null
|
||||
}
|
||||
|
||||
if (this[OBJECTMODE]) n = null
|
||||
|
||||
if (this[BUFFER].length > 1 && !this[OBJECTMODE]) {
|
||||
if (this.encoding) this[BUFFER] = [this[BUFFER].join('')]
|
||||
else this[BUFFER] = [Buffer.concat(this[BUFFER], this[BUFFERLENGTH])]
|
||||
}
|
||||
|
||||
const ret = this[READ](n || null, this[BUFFER][0])
|
||||
this[MAYBE_EMIT_END]()
|
||||
return ret
|
||||
}
|
||||
|
||||
[READ](n, chunk) {
|
||||
if (n === chunk.length || n === null) this[BUFFERSHIFT]()
|
||||
else {
|
||||
this[BUFFER][0] = chunk.slice(n)
|
||||
chunk = chunk.slice(0, n)
|
||||
this[BUFFERLENGTH] -= n
|
||||
}
|
||||
|
||||
this.emit('data', chunk)
|
||||
|
||||
if (!this[BUFFER].length && !this[EOF]) this.emit('drain')
|
||||
|
||||
return chunk
|
||||
}
|
||||
|
||||
end(chunk, encoding, cb) {
|
||||
if (typeof chunk === 'function') (cb = chunk), (chunk = null)
|
||||
if (typeof encoding === 'function') (cb = encoding), (encoding = 'utf8')
|
||||
if (chunk) this.write(chunk, encoding)
|
||||
if (cb) this.once('end', cb)
|
||||
this[EOF] = true
|
||||
this.writable = false
|
||||
|
||||
// if we haven't written anything, then go ahead and emit,
|
||||
// even if we're not reading.
|
||||
// we'll re-emit if a new 'end' listener is added anyway.
|
||||
// This makes MP more suitable to write-only use cases.
|
||||
if (this.flowing || !this[PAUSED]) this[MAYBE_EMIT_END]()
|
||||
return this
|
||||
}
|
||||
|
||||
// don't let the internal resume be overwritten
|
||||
[RESUME]() {
|
||||
if (this[DESTROYED]) return
|
||||
|
||||
this[PAUSED] = false
|
||||
this[FLOWING] = true
|
||||
this.emit('resume')
|
||||
if (this[BUFFER].length) this[FLUSH]()
|
||||
else if (this[EOF]) this[MAYBE_EMIT_END]()
|
||||
else this.emit('drain')
|
||||
}
|
||||
|
||||
resume() {
|
||||
return this[RESUME]()
|
||||
}
|
||||
|
||||
pause() {
|
||||
this[FLOWING] = false
|
||||
this[PAUSED] = true
|
||||
}
|
||||
|
||||
get destroyed() {
|
||||
return this[DESTROYED]
|
||||
}
|
||||
|
||||
get flowing() {
|
||||
return this[FLOWING]
|
||||
}
|
||||
|
||||
get paused() {
|
||||
return this[PAUSED]
|
||||
}
|
||||
|
||||
[BUFFERPUSH](chunk) {
|
||||
if (this[OBJECTMODE]) this[BUFFERLENGTH] += 1
|
||||
else this[BUFFERLENGTH] += chunk.length
|
||||
this[BUFFER].push(chunk)
|
||||
}
|
||||
|
||||
[BUFFERSHIFT]() {
|
||||
if (this[OBJECTMODE]) this[BUFFERLENGTH] -= 1
|
||||
else this[BUFFERLENGTH] -= this[BUFFER][0].length
|
||||
return this[BUFFER].shift()
|
||||
}
|
||||
|
||||
[FLUSH](noDrain) {
|
||||
do {} while (this[FLUSHCHUNK](this[BUFFERSHIFT]()) && this[BUFFER].length)
|
||||
|
||||
if (!noDrain && !this[BUFFER].length && !this[EOF]) this.emit('drain')
|
||||
}
|
||||
|
||||
[FLUSHCHUNK](chunk) {
|
||||
this.emit('data', chunk)
|
||||
return this.flowing
|
||||
}
|
||||
|
||||
pipe(dest, opts) {
|
||||
if (this[DESTROYED]) return
|
||||
|
||||
const ended = this[EMITTED_END]
|
||||
opts = opts || {}
|
||||
if (dest === proc.stdout || dest === proc.stderr) opts.end = false
|
||||
else opts.end = opts.end !== false
|
||||
opts.proxyErrors = !!opts.proxyErrors
|
||||
|
||||
// piping an ended stream ends immediately
|
||||
if (ended) {
|
||||
if (opts.end) dest.end()
|
||||
} else {
|
||||
this[PIPES].push(
|
||||
!opts.proxyErrors
|
||||
? new Pipe(this, dest, opts)
|
||||
: new PipeProxyErrors(this, dest, opts)
|
||||
)
|
||||
if (this[ASYNC]) defer(() => this[RESUME]())
|
||||
else this[RESUME]()
|
||||
}
|
||||
|
||||
return dest
|
||||
}
|
||||
|
||||
unpipe(dest) {
|
||||
const p = this[PIPES].find(p => p.dest === dest)
|
||||
if (p) {
|
||||
this[PIPES].splice(this[PIPES].indexOf(p), 1)
|
||||
p.unpipe()
|
||||
}
|
||||
}
|
||||
|
||||
addListener(ev, fn) {
|
||||
return this.on(ev, fn)
|
||||
}
|
||||
|
||||
on(ev, fn) {
|
||||
const ret = super.on(ev, fn)
|
||||
if (ev === 'data' && !this[PIPES].length && !this.flowing) this[RESUME]()
|
||||
else if (ev === 'readable' && this[BUFFERLENGTH] !== 0)
|
||||
super.emit('readable')
|
||||
else if (isEndish(ev) && this[EMITTED_END]) {
|
||||
super.emit(ev)
|
||||
this.removeAllListeners(ev)
|
||||
} else if (ev === 'error' && this[EMITTED_ERROR]) {
|
||||
if (this[ASYNC]) defer(() => fn.call(this, this[EMITTED_ERROR]))
|
||||
else fn.call(this, this[EMITTED_ERROR])
|
||||
}
|
||||
return ret
|
||||
}
|
||||
|
||||
get emittedEnd() {
|
||||
return this[EMITTED_END]
|
||||
}
|
||||
|
||||
[MAYBE_EMIT_END]() {
|
||||
if (
|
||||
!this[EMITTING_END] &&
|
||||
!this[EMITTED_END] &&
|
||||
!this[DESTROYED] &&
|
||||
this[BUFFER].length === 0 &&
|
||||
this[EOF]
|
||||
) {
|
||||
this[EMITTING_END] = true
|
||||
this.emit('end')
|
||||
this.emit('prefinish')
|
||||
this.emit('finish')
|
||||
if (this[CLOSED]) this.emit('close')
|
||||
this[EMITTING_END] = false
|
||||
}
|
||||
}
|
||||
|
||||
emit(ev, data, ...extra) {
|
||||
// error and close are only events allowed after calling destroy()
|
||||
if (ev !== 'error' && ev !== 'close' && ev !== DESTROYED && this[DESTROYED])
|
||||
return
|
||||
else if (ev === 'data') {
|
||||
return !this[OBJECTMODE] && !data
|
||||
? false
|
||||
: this[ASYNC]
|
||||
? defer(() => this[EMITDATA](data))
|
||||
: this[EMITDATA](data)
|
||||
} else if (ev === 'end') {
|
||||
return this[EMITEND]()
|
||||
} else if (ev === 'close') {
|
||||
this[CLOSED] = true
|
||||
// don't emit close before 'end' and 'finish'
|
||||
if (!this[EMITTED_END] && !this[DESTROYED]) return
|
||||
const ret = super.emit('close')
|
||||
this.removeAllListeners('close')
|
||||
return ret
|
||||
} else if (ev === 'error') {
|
||||
this[EMITTED_ERROR] = data
|
||||
super.emit(ERROR, data)
|
||||
const ret =
|
||||
!this[SIGNAL] || this.listeners('error').length
|
||||
? super.emit('error', data)
|
||||
: false
|
||||
this[MAYBE_EMIT_END]()
|
||||
return ret
|
||||
} else if (ev === 'resume') {
|
||||
const ret = super.emit('resume')
|
||||
this[MAYBE_EMIT_END]()
|
||||
return ret
|
||||
} else if (ev === 'finish' || ev === 'prefinish') {
|
||||
const ret = super.emit(ev)
|
||||
this.removeAllListeners(ev)
|
||||
return ret
|
||||
}
|
||||
|
||||
// Some other unknown event
|
||||
const ret = super.emit(ev, data, ...extra)
|
||||
this[MAYBE_EMIT_END]()
|
||||
return ret
|
||||
}
|
||||
|
||||
[EMITDATA](data) {
|
||||
for (const p of this[PIPES]) {
|
||||
if (p.dest.write(data) === false) this.pause()
|
||||
}
|
||||
const ret = super.emit('data', data)
|
||||
this[MAYBE_EMIT_END]()
|
||||
return ret
|
||||
}
|
||||
|
||||
[EMITEND]() {
|
||||
if (this[EMITTED_END]) return
|
||||
|
||||
this[EMITTED_END] = true
|
||||
this.readable = false
|
||||
if (this[ASYNC]) defer(() => this[EMITEND2]())
|
||||
else this[EMITEND2]()
|
||||
}
|
||||
|
||||
[EMITEND2]() {
|
||||
if (this[DECODER]) {
|
||||
const data = this[DECODER].end()
|
||||
if (data) {
|
||||
for (const p of this[PIPES]) {
|
||||
p.dest.write(data)
|
||||
}
|
||||
super.emit('data', data)
|
||||
}
|
||||
}
|
||||
|
||||
for (const p of this[PIPES]) {
|
||||
p.end()
|
||||
}
|
||||
const ret = super.emit('end')
|
||||
this.removeAllListeners('end')
|
||||
return ret
|
||||
}
|
||||
|
||||
// const all = await stream.collect()
|
||||
collect() {
|
||||
const buf = []
|
||||
if (!this[OBJECTMODE]) buf.dataLength = 0
|
||||
// set the promise first, in case an error is raised
|
||||
// by triggering the flow here.
|
||||
const p = this.promise()
|
||||
this.on('data', c => {
|
||||
buf.push(c)
|
||||
if (!this[OBJECTMODE]) buf.dataLength += c.length
|
||||
})
|
||||
return p.then(() => buf)
|
||||
}
|
||||
|
||||
// const data = await stream.concat()
|
||||
concat() {
|
||||
return this[OBJECTMODE]
|
||||
? Promise.reject(new Error('cannot concat in objectMode'))
|
||||
: this.collect().then(buf =>
|
||||
this[OBJECTMODE]
|
||||
? Promise.reject(new Error('cannot concat in objectMode'))
|
||||
: this[ENCODING]
|
||||
? buf.join('')
|
||||
: Buffer.concat(buf, buf.dataLength)
|
||||
)
|
||||
}
|
||||
|
||||
// stream.promise().then(() => done, er => emitted error)
|
||||
promise() {
|
||||
return new Promise((resolve, reject) => {
|
||||
this.on(DESTROYED, () => reject(new Error('stream destroyed')))
|
||||
this.on('error', er => reject(er))
|
||||
this.on('end', () => resolve())
|
||||
})
|
||||
}
|
||||
|
||||
// for await (let chunk of stream)
|
||||
[ASYNCITERATOR]() {
|
||||
let stopped = false
|
||||
const stop = () => {
|
||||
this.pause()
|
||||
stopped = true
|
||||
return Promise.resolve({ done: true })
|
||||
}
|
||||
const next = () => {
|
||||
if (stopped) return stop()
|
||||
const res = this.read()
|
||||
if (res !== null) return Promise.resolve({ done: false, value: res })
|
||||
|
||||
if (this[EOF]) return stop()
|
||||
|
||||
let resolve = null
|
||||
let reject = null
|
||||
const onerr = er => {
|
||||
this.removeListener('data', ondata)
|
||||
this.removeListener('end', onend)
|
||||
this.removeListener(DESTROYED, ondestroy)
|
||||
stop()
|
||||
reject(er)
|
||||
}
|
||||
const ondata = value => {
|
||||
this.removeListener('error', onerr)
|
||||
this.removeListener('end', onend)
|
||||
this.removeListener(DESTROYED, ondestroy)
|
||||
this.pause()
|
||||
resolve({ value: value, done: !!this[EOF] })
|
||||
}
|
||||
const onend = () => {
|
||||
this.removeListener('error', onerr)
|
||||
this.removeListener('data', ondata)
|
||||
this.removeListener(DESTROYED, ondestroy)
|
||||
stop()
|
||||
resolve({ done: true })
|
||||
}
|
||||
const ondestroy = () => onerr(new Error('stream destroyed'))
|
||||
return new Promise((res, rej) => {
|
||||
reject = rej
|
||||
resolve = res
|
||||
this.once(DESTROYED, ondestroy)
|
||||
this.once('error', onerr)
|
||||
this.once('end', onend)
|
||||
this.once('data', ondata)
|
||||
})
|
||||
}
|
||||
|
||||
return {
|
||||
next,
|
||||
throw: stop,
|
||||
return: stop,
|
||||
[ASYNCITERATOR]() {
|
||||
return this
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
// for (let chunk of stream)
|
||||
[ITERATOR]() {
|
||||
let stopped = false
|
||||
const stop = () => {
|
||||
this.pause()
|
||||
this.removeListener(ERROR, stop)
|
||||
this.removeListener(DESTROYED, stop)
|
||||
this.removeListener('end', stop)
|
||||
stopped = true
|
||||
return { done: true }
|
||||
}
|
||||
|
||||
const next = () => {
|
||||
if (stopped) return stop()
|
||||
const value = this.read()
|
||||
return value === null ? stop() : { value }
|
||||
}
|
||||
this.once('end', stop)
|
||||
this.once(ERROR, stop)
|
||||
this.once(DESTROYED, stop)
|
||||
|
||||
return {
|
||||
next,
|
||||
throw: stop,
|
||||
return: stop,
|
||||
[ITERATOR]() {
|
||||
return this
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
destroy(er) {
|
||||
if (this[DESTROYED]) {
|
||||
if (er) this.emit('error', er)
|
||||
else this.emit(DESTROYED)
|
||||
return this
|
||||
}
|
||||
|
||||
this[DESTROYED] = true
|
||||
|
||||
// throw away all buffered data, it's never coming out
|
||||
this[BUFFER].length = 0
|
||||
this[BUFFERLENGTH] = 0
|
||||
|
||||
if (typeof this.close === 'function' && !this[CLOSED]) this.close()
|
||||
|
||||
if (er) this.emit('error', er)
|
||||
// if no error to emit, still reject pending promises
|
||||
else this.emit(DESTROYED)
|
||||
|
||||
return this
|
||||
}
|
||||
|
||||
static isStream(s) {
|
||||
return (
|
||||
!!s &&
|
||||
(s instanceof Minipass ||
|
||||
s instanceof Stream ||
|
||||
(s instanceof EE &&
|
||||
// readable
|
||||
(typeof s.pipe === 'function' ||
|
||||
// writable
|
||||
(typeof s.write === 'function' && typeof s.end === 'function'))))
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
exports.Minipass = Minipass
|
||||
702
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/index.mjs
generated
vendored
Normal file
702
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/index.mjs
generated
vendored
Normal file
|
|
@ -0,0 +1,702 @@
|
|||
'use strict'
|
||||
const proc =
|
||||
typeof process === 'object' && process
|
||||
? process
|
||||
: {
|
||||
stdout: null,
|
||||
stderr: null,
|
||||
}
|
||||
import EE from 'events'
|
||||
import Stream from 'stream'
|
||||
import stringdecoder from 'string_decoder'
|
||||
const SD = stringdecoder.StringDecoder
|
||||
|
||||
const EOF = Symbol('EOF')
|
||||
const MAYBE_EMIT_END = Symbol('maybeEmitEnd')
|
||||
const EMITTED_END = Symbol('emittedEnd')
|
||||
const EMITTING_END = Symbol('emittingEnd')
|
||||
const EMITTED_ERROR = Symbol('emittedError')
|
||||
const CLOSED = Symbol('closed')
|
||||
const READ = Symbol('read')
|
||||
const FLUSH = Symbol('flush')
|
||||
const FLUSHCHUNK = Symbol('flushChunk')
|
||||
const ENCODING = Symbol('encoding')
|
||||
const DECODER = Symbol('decoder')
|
||||
const FLOWING = Symbol('flowing')
|
||||
const PAUSED = Symbol('paused')
|
||||
const RESUME = Symbol('resume')
|
||||
const BUFFER = Symbol('buffer')
|
||||
const PIPES = Symbol('pipes')
|
||||
const BUFFERLENGTH = Symbol('bufferLength')
|
||||
const BUFFERPUSH = Symbol('bufferPush')
|
||||
const BUFFERSHIFT = Symbol('bufferShift')
|
||||
const OBJECTMODE = Symbol('objectMode')
|
||||
// internal event when stream is destroyed
|
||||
const DESTROYED = Symbol('destroyed')
|
||||
// internal event when stream has an error
|
||||
const ERROR = Symbol('error')
|
||||
const EMITDATA = Symbol('emitData')
|
||||
const EMITEND = Symbol('emitEnd')
|
||||
const EMITEND2 = Symbol('emitEnd2')
|
||||
const ASYNC = Symbol('async')
|
||||
const ABORT = Symbol('abort')
|
||||
const ABORTED = Symbol('aborted')
|
||||
const SIGNAL = Symbol('signal')
|
||||
|
||||
const defer = fn => Promise.resolve().then(fn)
|
||||
|
||||
// TODO remove when Node v8 support drops
|
||||
const doIter = global._MP_NO_ITERATOR_SYMBOLS_ !== '1'
|
||||
const ASYNCITERATOR =
|
||||
(doIter && Symbol.asyncIterator) || Symbol('asyncIterator not implemented')
|
||||
const ITERATOR =
|
||||
(doIter && Symbol.iterator) || Symbol('iterator not implemented')
|
||||
|
||||
// events that mean 'the stream is over'
|
||||
// these are treated specially, and re-emitted
|
||||
// if they are listened for after emitting.
|
||||
const isEndish = ev => ev === 'end' || ev === 'finish' || ev === 'prefinish'
|
||||
|
||||
const isArrayBuffer = b =>
|
||||
b instanceof ArrayBuffer ||
|
||||
(typeof b === 'object' &&
|
||||
b.constructor &&
|
||||
b.constructor.name === 'ArrayBuffer' &&
|
||||
b.byteLength >= 0)
|
||||
|
||||
const isArrayBufferView = b => !Buffer.isBuffer(b) && ArrayBuffer.isView(b)
|
||||
|
||||
class Pipe {
|
||||
constructor(src, dest, opts) {
|
||||
this.src = src
|
||||
this.dest = dest
|
||||
this.opts = opts
|
||||
this.ondrain = () => src[RESUME]()
|
||||
dest.on('drain', this.ondrain)
|
||||
}
|
||||
unpipe() {
|
||||
this.dest.removeListener('drain', this.ondrain)
|
||||
}
|
||||
// istanbul ignore next - only here for the prototype
|
||||
proxyErrors() {}
|
||||
end() {
|
||||
this.unpipe()
|
||||
if (this.opts.end) this.dest.end()
|
||||
}
|
||||
}
|
||||
|
||||
class PipeProxyErrors extends Pipe {
|
||||
unpipe() {
|
||||
this.src.removeListener('error', this.proxyErrors)
|
||||
super.unpipe()
|
||||
}
|
||||
constructor(src, dest, opts) {
|
||||
super(src, dest, opts)
|
||||
this.proxyErrors = er => dest.emit('error', er)
|
||||
src.on('error', this.proxyErrors)
|
||||
}
|
||||
}
|
||||
|
||||
export class Minipass extends Stream {
|
||||
constructor(options) {
|
||||
super()
|
||||
this[FLOWING] = false
|
||||
// whether we're explicitly paused
|
||||
this[PAUSED] = false
|
||||
this[PIPES] = []
|
||||
this[BUFFER] = []
|
||||
this[OBJECTMODE] = (options && options.objectMode) || false
|
||||
if (this[OBJECTMODE]) this[ENCODING] = null
|
||||
else this[ENCODING] = (options && options.encoding) || null
|
||||
if (this[ENCODING] === 'buffer') this[ENCODING] = null
|
||||
this[ASYNC] = (options && !!options.async) || false
|
||||
this[DECODER] = this[ENCODING] ? new SD(this[ENCODING]) : null
|
||||
this[EOF] = false
|
||||
this[EMITTED_END] = false
|
||||
this[EMITTING_END] = false
|
||||
this[CLOSED] = false
|
||||
this[EMITTED_ERROR] = null
|
||||
this.writable = true
|
||||
this.readable = true
|
||||
this[BUFFERLENGTH] = 0
|
||||
this[DESTROYED] = false
|
||||
if (options && options.debugExposeBuffer === true) {
|
||||
Object.defineProperty(this, 'buffer', { get: () => this[BUFFER] })
|
||||
}
|
||||
if (options && options.debugExposePipes === true) {
|
||||
Object.defineProperty(this, 'pipes', { get: () => this[PIPES] })
|
||||
}
|
||||
this[SIGNAL] = options && options.signal
|
||||
this[ABORTED] = false
|
||||
if (this[SIGNAL]) {
|
||||
this[SIGNAL].addEventListener('abort', () => this[ABORT]())
|
||||
if (this[SIGNAL].aborted) {
|
||||
this[ABORT]()
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
get bufferLength() {
|
||||
return this[BUFFERLENGTH]
|
||||
}
|
||||
|
||||
get encoding() {
|
||||
return this[ENCODING]
|
||||
}
|
||||
set encoding(enc) {
|
||||
if (this[OBJECTMODE]) throw new Error('cannot set encoding in objectMode')
|
||||
|
||||
if (
|
||||
this[ENCODING] &&
|
||||
enc !== this[ENCODING] &&
|
||||
((this[DECODER] && this[DECODER].lastNeed) || this[BUFFERLENGTH])
|
||||
)
|
||||
throw new Error('cannot change encoding')
|
||||
|
||||
if (this[ENCODING] !== enc) {
|
||||
this[DECODER] = enc ? new SD(enc) : null
|
||||
if (this[BUFFER].length)
|
||||
this[BUFFER] = this[BUFFER].map(chunk => this[DECODER].write(chunk))
|
||||
}
|
||||
|
||||
this[ENCODING] = enc
|
||||
}
|
||||
|
||||
setEncoding(enc) {
|
||||
this.encoding = enc
|
||||
}
|
||||
|
||||
get objectMode() {
|
||||
return this[OBJECTMODE]
|
||||
}
|
||||
set objectMode(om) {
|
||||
this[OBJECTMODE] = this[OBJECTMODE] || !!om
|
||||
}
|
||||
|
||||
get ['async']() {
|
||||
return this[ASYNC]
|
||||
}
|
||||
set ['async'](a) {
|
||||
this[ASYNC] = this[ASYNC] || !!a
|
||||
}
|
||||
|
||||
// drop everything and get out of the flow completely
|
||||
[ABORT]() {
|
||||
this[ABORTED] = true
|
||||
this.emit('abort', this[SIGNAL].reason)
|
||||
this.destroy(this[SIGNAL].reason)
|
||||
}
|
||||
|
||||
get aborted() {
|
||||
return this[ABORTED]
|
||||
}
|
||||
set aborted(_) {}
|
||||
|
||||
write(chunk, encoding, cb) {
|
||||
if (this[ABORTED]) return false
|
||||
if (this[EOF]) throw new Error('write after end')
|
||||
|
||||
if (this[DESTROYED]) {
|
||||
this.emit(
|
||||
'error',
|
||||
Object.assign(
|
||||
new Error('Cannot call write after a stream was destroyed'),
|
||||
{ code: 'ERR_STREAM_DESTROYED' }
|
||||
)
|
||||
)
|
||||
return true
|
||||
}
|
||||
|
||||
if (typeof encoding === 'function') (cb = encoding), (encoding = 'utf8')
|
||||
|
||||
if (!encoding) encoding = 'utf8'
|
||||
|
||||
const fn = this[ASYNC] ? defer : f => f()
|
||||
|
||||
// convert array buffers and typed array views into buffers
|
||||
// at some point in the future, we may want to do the opposite!
|
||||
// leave strings and buffers as-is
|
||||
// anything else switches us into object mode
|
||||
if (!this[OBJECTMODE] && !Buffer.isBuffer(chunk)) {
|
||||
if (isArrayBufferView(chunk))
|
||||
chunk = Buffer.from(chunk.buffer, chunk.byteOffset, chunk.byteLength)
|
||||
else if (isArrayBuffer(chunk)) chunk = Buffer.from(chunk)
|
||||
else if (typeof chunk !== 'string')
|
||||
// use the setter so we throw if we have encoding set
|
||||
this.objectMode = true
|
||||
}
|
||||
|
||||
// handle object mode up front, since it's simpler
|
||||
// this yields better performance, fewer checks later.
|
||||
if (this[OBJECTMODE]) {
|
||||
/* istanbul ignore if - maybe impossible? */
|
||||
if (this.flowing && this[BUFFERLENGTH] !== 0) this[FLUSH](true)
|
||||
|
||||
if (this.flowing) this.emit('data', chunk)
|
||||
else this[BUFFERPUSH](chunk)
|
||||
|
||||
if (this[BUFFERLENGTH] !== 0) this.emit('readable')
|
||||
|
||||
if (cb) fn(cb)
|
||||
|
||||
return this.flowing
|
||||
}
|
||||
|
||||
// at this point the chunk is a buffer or string
|
||||
// don't buffer it up or send it to the decoder
|
||||
if (!chunk.length) {
|
||||
if (this[BUFFERLENGTH] !== 0) this.emit('readable')
|
||||
if (cb) fn(cb)
|
||||
return this.flowing
|
||||
}
|
||||
|
||||
// fast-path writing strings of same encoding to a stream with
|
||||
// an empty buffer, skipping the buffer/decoder dance
|
||||
if (
|
||||
typeof chunk === 'string' &&
|
||||
// unless it is a string already ready for us to use
|
||||
!(encoding === this[ENCODING] && !this[DECODER].lastNeed)
|
||||
) {
|
||||
chunk = Buffer.from(chunk, encoding)
|
||||
}
|
||||
|
||||
if (Buffer.isBuffer(chunk) && this[ENCODING])
|
||||
chunk = this[DECODER].write(chunk)
|
||||
|
||||
// Note: flushing CAN potentially switch us into not-flowing mode
|
||||
if (this.flowing && this[BUFFERLENGTH] !== 0) this[FLUSH](true)
|
||||
|
||||
if (this.flowing) this.emit('data', chunk)
|
||||
else this[BUFFERPUSH](chunk)
|
||||
|
||||
if (this[BUFFERLENGTH] !== 0) this.emit('readable')
|
||||
|
||||
if (cb) fn(cb)
|
||||
|
||||
return this.flowing
|
||||
}
|
||||
|
||||
read(n) {
|
||||
if (this[DESTROYED]) return null
|
||||
|
||||
if (this[BUFFERLENGTH] === 0 || n === 0 || n > this[BUFFERLENGTH]) {
|
||||
this[MAYBE_EMIT_END]()
|
||||
return null
|
||||
}
|
||||
|
||||
if (this[OBJECTMODE]) n = null
|
||||
|
||||
if (this[BUFFER].length > 1 && !this[OBJECTMODE]) {
|
||||
if (this.encoding) this[BUFFER] = [this[BUFFER].join('')]
|
||||
else this[BUFFER] = [Buffer.concat(this[BUFFER], this[BUFFERLENGTH])]
|
||||
}
|
||||
|
||||
const ret = this[READ](n || null, this[BUFFER][0])
|
||||
this[MAYBE_EMIT_END]()
|
||||
return ret
|
||||
}
|
||||
|
||||
[READ](n, chunk) {
|
||||
if (n === chunk.length || n === null) this[BUFFERSHIFT]()
|
||||
else {
|
||||
this[BUFFER][0] = chunk.slice(n)
|
||||
chunk = chunk.slice(0, n)
|
||||
this[BUFFERLENGTH] -= n
|
||||
}
|
||||
|
||||
this.emit('data', chunk)
|
||||
|
||||
if (!this[BUFFER].length && !this[EOF]) this.emit('drain')
|
||||
|
||||
return chunk
|
||||
}
|
||||
|
||||
end(chunk, encoding, cb) {
|
||||
if (typeof chunk === 'function') (cb = chunk), (chunk = null)
|
||||
if (typeof encoding === 'function') (cb = encoding), (encoding = 'utf8')
|
||||
if (chunk) this.write(chunk, encoding)
|
||||
if (cb) this.once('end', cb)
|
||||
this[EOF] = true
|
||||
this.writable = false
|
||||
|
||||
// if we haven't written anything, then go ahead and emit,
|
||||
// even if we're not reading.
|
||||
// we'll re-emit if a new 'end' listener is added anyway.
|
||||
// This makes MP more suitable to write-only use cases.
|
||||
if (this.flowing || !this[PAUSED]) this[MAYBE_EMIT_END]()
|
||||
return this
|
||||
}
|
||||
|
||||
// don't let the internal resume be overwritten
|
||||
[RESUME]() {
|
||||
if (this[DESTROYED]) return
|
||||
|
||||
this[PAUSED] = false
|
||||
this[FLOWING] = true
|
||||
this.emit('resume')
|
||||
if (this[BUFFER].length) this[FLUSH]()
|
||||
else if (this[EOF]) this[MAYBE_EMIT_END]()
|
||||
else this.emit('drain')
|
||||
}
|
||||
|
||||
resume() {
|
||||
return this[RESUME]()
|
||||
}
|
||||
|
||||
pause() {
|
||||
this[FLOWING] = false
|
||||
this[PAUSED] = true
|
||||
}
|
||||
|
||||
get destroyed() {
|
||||
return this[DESTROYED]
|
||||
}
|
||||
|
||||
get flowing() {
|
||||
return this[FLOWING]
|
||||
}
|
||||
|
||||
get paused() {
|
||||
return this[PAUSED]
|
||||
}
|
||||
|
||||
[BUFFERPUSH](chunk) {
|
||||
if (this[OBJECTMODE]) this[BUFFERLENGTH] += 1
|
||||
else this[BUFFERLENGTH] += chunk.length
|
||||
this[BUFFER].push(chunk)
|
||||
}
|
||||
|
||||
[BUFFERSHIFT]() {
|
||||
if (this[OBJECTMODE]) this[BUFFERLENGTH] -= 1
|
||||
else this[BUFFERLENGTH] -= this[BUFFER][0].length
|
||||
return this[BUFFER].shift()
|
||||
}
|
||||
|
||||
[FLUSH](noDrain) {
|
||||
do {} while (this[FLUSHCHUNK](this[BUFFERSHIFT]()) && this[BUFFER].length)
|
||||
|
||||
if (!noDrain && !this[BUFFER].length && !this[EOF]) this.emit('drain')
|
||||
}
|
||||
|
||||
[FLUSHCHUNK](chunk) {
|
||||
this.emit('data', chunk)
|
||||
return this.flowing
|
||||
}
|
||||
|
||||
pipe(dest, opts) {
|
||||
if (this[DESTROYED]) return
|
||||
|
||||
const ended = this[EMITTED_END]
|
||||
opts = opts || {}
|
||||
if (dest === proc.stdout || dest === proc.stderr) opts.end = false
|
||||
else opts.end = opts.end !== false
|
||||
opts.proxyErrors = !!opts.proxyErrors
|
||||
|
||||
// piping an ended stream ends immediately
|
||||
if (ended) {
|
||||
if (opts.end) dest.end()
|
||||
} else {
|
||||
this[PIPES].push(
|
||||
!opts.proxyErrors
|
||||
? new Pipe(this, dest, opts)
|
||||
: new PipeProxyErrors(this, dest, opts)
|
||||
)
|
||||
if (this[ASYNC]) defer(() => this[RESUME]())
|
||||
else this[RESUME]()
|
||||
}
|
||||
|
||||
return dest
|
||||
}
|
||||
|
||||
unpipe(dest) {
|
||||
const p = this[PIPES].find(p => p.dest === dest)
|
||||
if (p) {
|
||||
this[PIPES].splice(this[PIPES].indexOf(p), 1)
|
||||
p.unpipe()
|
||||
}
|
||||
}
|
||||
|
||||
addListener(ev, fn) {
|
||||
return this.on(ev, fn)
|
||||
}
|
||||
|
||||
on(ev, fn) {
|
||||
const ret = super.on(ev, fn)
|
||||
if (ev === 'data' && !this[PIPES].length && !this.flowing) this[RESUME]()
|
||||
else if (ev === 'readable' && this[BUFFERLENGTH] !== 0)
|
||||
super.emit('readable')
|
||||
else if (isEndish(ev) && this[EMITTED_END]) {
|
||||
super.emit(ev)
|
||||
this.removeAllListeners(ev)
|
||||
} else if (ev === 'error' && this[EMITTED_ERROR]) {
|
||||
if (this[ASYNC]) defer(() => fn.call(this, this[EMITTED_ERROR]))
|
||||
else fn.call(this, this[EMITTED_ERROR])
|
||||
}
|
||||
return ret
|
||||
}
|
||||
|
||||
get emittedEnd() {
|
||||
return this[EMITTED_END]
|
||||
}
|
||||
|
||||
[MAYBE_EMIT_END]() {
|
||||
if (
|
||||
!this[EMITTING_END] &&
|
||||
!this[EMITTED_END] &&
|
||||
!this[DESTROYED] &&
|
||||
this[BUFFER].length === 0 &&
|
||||
this[EOF]
|
||||
) {
|
||||
this[EMITTING_END] = true
|
||||
this.emit('end')
|
||||
this.emit('prefinish')
|
||||
this.emit('finish')
|
||||
if (this[CLOSED]) this.emit('close')
|
||||
this[EMITTING_END] = false
|
||||
}
|
||||
}
|
||||
|
||||
emit(ev, data, ...extra) {
|
||||
// error and close are only events allowed after calling destroy()
|
||||
if (ev !== 'error' && ev !== 'close' && ev !== DESTROYED && this[DESTROYED])
|
||||
return
|
||||
else if (ev === 'data') {
|
||||
return !this[OBJECTMODE] && !data
|
||||
? false
|
||||
: this[ASYNC]
|
||||
? defer(() => this[EMITDATA](data))
|
||||
: this[EMITDATA](data)
|
||||
} else if (ev === 'end') {
|
||||
return this[EMITEND]()
|
||||
} else if (ev === 'close') {
|
||||
this[CLOSED] = true
|
||||
// don't emit close before 'end' and 'finish'
|
||||
if (!this[EMITTED_END] && !this[DESTROYED]) return
|
||||
const ret = super.emit('close')
|
||||
this.removeAllListeners('close')
|
||||
return ret
|
||||
} else if (ev === 'error') {
|
||||
this[EMITTED_ERROR] = data
|
||||
super.emit(ERROR, data)
|
||||
const ret =
|
||||
!this[SIGNAL] || this.listeners('error').length
|
||||
? super.emit('error', data)
|
||||
: false
|
||||
this[MAYBE_EMIT_END]()
|
||||
return ret
|
||||
} else if (ev === 'resume') {
|
||||
const ret = super.emit('resume')
|
||||
this[MAYBE_EMIT_END]()
|
||||
return ret
|
||||
} else if (ev === 'finish' || ev === 'prefinish') {
|
||||
const ret = super.emit(ev)
|
||||
this.removeAllListeners(ev)
|
||||
return ret
|
||||
}
|
||||
|
||||
// Some other unknown event
|
||||
const ret = super.emit(ev, data, ...extra)
|
||||
this[MAYBE_EMIT_END]()
|
||||
return ret
|
||||
}
|
||||
|
||||
[EMITDATA](data) {
|
||||
for (const p of this[PIPES]) {
|
||||
if (p.dest.write(data) === false) this.pause()
|
||||
}
|
||||
const ret = super.emit('data', data)
|
||||
this[MAYBE_EMIT_END]()
|
||||
return ret
|
||||
}
|
||||
|
||||
[EMITEND]() {
|
||||
if (this[EMITTED_END]) return
|
||||
|
||||
this[EMITTED_END] = true
|
||||
this.readable = false
|
||||
if (this[ASYNC]) defer(() => this[EMITEND2]())
|
||||
else this[EMITEND2]()
|
||||
}
|
||||
|
||||
[EMITEND2]() {
|
||||
if (this[DECODER]) {
|
||||
const data = this[DECODER].end()
|
||||
if (data) {
|
||||
for (const p of this[PIPES]) {
|
||||
p.dest.write(data)
|
||||
}
|
||||
super.emit('data', data)
|
||||
}
|
||||
}
|
||||
|
||||
for (const p of this[PIPES]) {
|
||||
p.end()
|
||||
}
|
||||
const ret = super.emit('end')
|
||||
this.removeAllListeners('end')
|
||||
return ret
|
||||
}
|
||||
|
||||
// const all = await stream.collect()
|
||||
collect() {
|
||||
const buf = []
|
||||
if (!this[OBJECTMODE]) buf.dataLength = 0
|
||||
// set the promise first, in case an error is raised
|
||||
// by triggering the flow here.
|
||||
const p = this.promise()
|
||||
this.on('data', c => {
|
||||
buf.push(c)
|
||||
if (!this[OBJECTMODE]) buf.dataLength += c.length
|
||||
})
|
||||
return p.then(() => buf)
|
||||
}
|
||||
|
||||
// const data = await stream.concat()
|
||||
concat() {
|
||||
return this[OBJECTMODE]
|
||||
? Promise.reject(new Error('cannot concat in objectMode'))
|
||||
: this.collect().then(buf =>
|
||||
this[OBJECTMODE]
|
||||
? Promise.reject(new Error('cannot concat in objectMode'))
|
||||
: this[ENCODING]
|
||||
? buf.join('')
|
||||
: Buffer.concat(buf, buf.dataLength)
|
||||
)
|
||||
}
|
||||
|
||||
// stream.promise().then(() => done, er => emitted error)
|
||||
promise() {
|
||||
return new Promise((resolve, reject) => {
|
||||
this.on(DESTROYED, () => reject(new Error('stream destroyed')))
|
||||
this.on('error', er => reject(er))
|
||||
this.on('end', () => resolve())
|
||||
})
|
||||
}
|
||||
|
||||
// for await (let chunk of stream)
|
||||
[ASYNCITERATOR]() {
|
||||
let stopped = false
|
||||
const stop = () => {
|
||||
this.pause()
|
||||
stopped = true
|
||||
return Promise.resolve({ done: true })
|
||||
}
|
||||
const next = () => {
|
||||
if (stopped) return stop()
|
||||
const res = this.read()
|
||||
if (res !== null) return Promise.resolve({ done: false, value: res })
|
||||
|
||||
if (this[EOF]) return stop()
|
||||
|
||||
let resolve = null
|
||||
let reject = null
|
||||
const onerr = er => {
|
||||
this.removeListener('data', ondata)
|
||||
this.removeListener('end', onend)
|
||||
this.removeListener(DESTROYED, ondestroy)
|
||||
stop()
|
||||
reject(er)
|
||||
}
|
||||
const ondata = value => {
|
||||
this.removeListener('error', onerr)
|
||||
this.removeListener('end', onend)
|
||||
this.removeListener(DESTROYED, ondestroy)
|
||||
this.pause()
|
||||
resolve({ value: value, done: !!this[EOF] })
|
||||
}
|
||||
const onend = () => {
|
||||
this.removeListener('error', onerr)
|
||||
this.removeListener('data', ondata)
|
||||
this.removeListener(DESTROYED, ondestroy)
|
||||
stop()
|
||||
resolve({ done: true })
|
||||
}
|
||||
const ondestroy = () => onerr(new Error('stream destroyed'))
|
||||
return new Promise((res, rej) => {
|
||||
reject = rej
|
||||
resolve = res
|
||||
this.once(DESTROYED, ondestroy)
|
||||
this.once('error', onerr)
|
||||
this.once('end', onend)
|
||||
this.once('data', ondata)
|
||||
})
|
||||
}
|
||||
|
||||
return {
|
||||
next,
|
||||
throw: stop,
|
||||
return: stop,
|
||||
[ASYNCITERATOR]() {
|
||||
return this
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
// for (let chunk of stream)
|
||||
[ITERATOR]() {
|
||||
let stopped = false
|
||||
const stop = () => {
|
||||
this.pause()
|
||||
this.removeListener(ERROR, stop)
|
||||
this.removeListener(DESTROYED, stop)
|
||||
this.removeListener('end', stop)
|
||||
stopped = true
|
||||
return { done: true }
|
||||
}
|
||||
|
||||
const next = () => {
|
||||
if (stopped) return stop()
|
||||
const value = this.read()
|
||||
return value === null ? stop() : { value }
|
||||
}
|
||||
this.once('end', stop)
|
||||
this.once(ERROR, stop)
|
||||
this.once(DESTROYED, stop)
|
||||
|
||||
return {
|
||||
next,
|
||||
throw: stop,
|
||||
return: stop,
|
||||
[ITERATOR]() {
|
||||
return this
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
destroy(er) {
|
||||
if (this[DESTROYED]) {
|
||||
if (er) this.emit('error', er)
|
||||
else this.emit(DESTROYED)
|
||||
return this
|
||||
}
|
||||
|
||||
this[DESTROYED] = true
|
||||
|
||||
// throw away all buffered data, it's never coming out
|
||||
this[BUFFER].length = 0
|
||||
this[BUFFERLENGTH] = 0
|
||||
|
||||
if (typeof this.close === 'function' && !this[CLOSED]) this.close()
|
||||
|
||||
if (er) this.emit('error', er)
|
||||
// if no error to emit, still reject pending promises
|
||||
else this.emit(DESTROYED)
|
||||
|
||||
return this
|
||||
}
|
||||
|
||||
static isStream(s) {
|
||||
return (
|
||||
!!s &&
|
||||
(s instanceof Minipass ||
|
||||
s instanceof Stream ||
|
||||
(s instanceof EE &&
|
||||
// readable
|
||||
(typeof s.pipe === 'function' ||
|
||||
// writable
|
||||
(typeof s.write === 'function' && typeof s.end === 'function'))))
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
76
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/package.json
generated
vendored
Normal file
76
electron/node_modules/cacache/node_modules/tar/node_modules/minipass/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,76 @@
|
|||
{
|
||||
"name": "minipass",
|
||||
"version": "5.0.0",
|
||||
"description": "minimal implementation of a PassThrough stream",
|
||||
"main": "./index.js",
|
||||
"module": "./index.mjs",
|
||||
"types": "./index.d.ts",
|
||||
"exports": {
|
||||
".": {
|
||||
"import": {
|
||||
"types": "./index.d.ts",
|
||||
"default": "./index.mjs"
|
||||
},
|
||||
"require": {
|
||||
"types": "./index.d.ts",
|
||||
"default": "./index.js"
|
||||
}
|
||||
},
|
||||
"./package.json": "./package.json"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@types/node": "^17.0.41",
|
||||
"end-of-stream": "^1.4.0",
|
||||
"node-abort-controller": "^3.1.1",
|
||||
"prettier": "^2.6.2",
|
||||
"tap": "^16.2.0",
|
||||
"through2": "^2.0.3",
|
||||
"ts-node": "^10.8.1",
|
||||
"typedoc": "^0.23.24",
|
||||
"typescript": "^4.7.3"
|
||||
},
|
||||
"scripts": {
|
||||
"pretest": "npm run prepare",
|
||||
"presnap": "npm run prepare",
|
||||
"prepare": "node ./scripts/transpile-to-esm.js",
|
||||
"snap": "tap",
|
||||
"test": "tap",
|
||||
"preversion": "npm test",
|
||||
"postversion": "npm publish",
|
||||
"postpublish": "git push origin --follow-tags",
|
||||
"typedoc": "typedoc ./index.d.ts",
|
||||
"format": "prettier --write . --loglevel warn"
|
||||
},
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git+https://github.com/isaacs/minipass.git"
|
||||
},
|
||||
"keywords": [
|
||||
"passthrough",
|
||||
"stream"
|
||||
],
|
||||
"author": "Isaac Z. Schlueter <i@izs.me> (http://blog.izs.me/)",
|
||||
"license": "ISC",
|
||||
"files": [
|
||||
"index.d.ts",
|
||||
"index.js",
|
||||
"index.mjs"
|
||||
],
|
||||
"tap": {
|
||||
"check-coverage": true
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=8"
|
||||
},
|
||||
"prettier": {
|
||||
"semi": false,
|
||||
"printWidth": 80,
|
||||
"tabWidth": 2,
|
||||
"useTabs": false,
|
||||
"singleQuote": true,
|
||||
"jsxSingleQuote": false,
|
||||
"bracketSameLine": true,
|
||||
"arrowParens": "avoid",
|
||||
"endOfLine": "lf"
|
||||
}
|
||||
}
|
||||
70
electron/node_modules/cacache/node_modules/tar/package.json
generated
vendored
Normal file
70
electron/node_modules/cacache/node_modules/tar/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,70 @@
|
|||
{
|
||||
"author": "GitHub Inc.",
|
||||
"name": "tar",
|
||||
"description": "tar for node",
|
||||
"version": "6.2.1",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "https://github.com/isaacs/node-tar.git"
|
||||
},
|
||||
"scripts": {
|
||||
"genparse": "node scripts/generate-parse-fixtures.js",
|
||||
"snap": "tap",
|
||||
"test": "tap"
|
||||
},
|
||||
"dependencies": {
|
||||
"chownr": "^2.0.0",
|
||||
"fs-minipass": "^2.0.0",
|
||||
"minipass": "^5.0.0",
|
||||
"minizlib": "^2.1.1",
|
||||
"mkdirp": "^1.0.3",
|
||||
"yallist": "^4.0.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@npmcli/eslint-config": "^4.0.0",
|
||||
"@npmcli/template-oss": "4.11.0",
|
||||
"chmodr": "^1.2.0",
|
||||
"end-of-stream": "^1.4.3",
|
||||
"events-to-array": "^2.0.3",
|
||||
"mutate-fs": "^2.1.1",
|
||||
"nock": "^13.2.9",
|
||||
"rimraf": "^3.0.2",
|
||||
"tap": "^16.0.1"
|
||||
},
|
||||
"license": "ISC",
|
||||
"engines": {
|
||||
"node": ">=10"
|
||||
},
|
||||
"files": [
|
||||
"bin/",
|
||||
"lib/",
|
||||
"index.js"
|
||||
],
|
||||
"tap": {
|
||||
"coverage-map": "map.js",
|
||||
"timeout": 0,
|
||||
"nyc-arg": [
|
||||
"--exclude",
|
||||
"tap-snapshots/**"
|
||||
]
|
||||
},
|
||||
"templateOSS": {
|
||||
"//@npmcli/template-oss": "This file is partially managed by @npmcli/template-oss. Edits may be overwritten.",
|
||||
"version": "4.11.0",
|
||||
"content": "scripts/template-oss",
|
||||
"engines": ">=10",
|
||||
"distPaths": [
|
||||
"index.js"
|
||||
],
|
||||
"allowPaths": [
|
||||
"/index.js"
|
||||
],
|
||||
"ciVersions": [
|
||||
"10.x",
|
||||
"12.x",
|
||||
"14.x",
|
||||
"16.x",
|
||||
"18.x"
|
||||
]
|
||||
}
|
||||
}
|
||||
Loading…
Add table
Add a link
Reference in a new issue